

Точно Не проект 2 / Не books / Источник_1
.pdfГЛАВА 4
ОСНОВНЫЕ МОДЕЛИ ВЫВОДА
Под выводом понимают процесс получения заключений из предпосылок. Существуют различные модели вывода. В главе 3 было введено понятие дедуктивного вывода в логике исчисления предикатов, который базируется на применении определенных правил вывода к множеству исходных истинных утверждений, и только лишь обозначено возможное направление автоматизации этого процесса. В данной главе рассмотрим общие процедуры, позволяющие автоматизировать дедуктивный вывод в исчислении предикатов, и, прежде всего, процедуру резолюции. С этой целью введем понятие предложения для формул исчисления предикатов, затем рассмотрим понятие универсума Эрбрана и, наконец, опишем процедуру резолюции и ее применения при решении различных задач.
Хотя исчисление предикатов является весьма мощным инструментом, подходящим для описания самых различных предметных областей, однако оно не лишено недостатков. В частности, теория исчисления предикатов позволяет получать правильные заключения, опираясь на общезначимые утверждения и обоснованные правила вывода. Вместе с тем часто требуется осуществлять вывод в условиях, когда исходные данные не являются абсолютно достоверными и полными, а правила вывода носят эвристический характер и ненадежны. В этом случае применяют процедуры, обеспечивающие вывод заключений с определенной степенью уверенности (процедуры вывода на ненадежных знаниях), а также процедуры немонотонного вывода, допускающие получение в ходе вывода заключений, которые могут логически противоречить утверждениям, имеющимся в базе знаний.
Кроме дедуктивного вывода, в системах искусственного интеллекта широко используют индуктивные схемы вывода. Такие схемы вывода позволяют порождать обобщения имеющихся частных утверждений. Способность к обобщению является важной функцией естественного интеллекта и используется им для получения новых знаний. Поэтому индуктивные схемы вывода являются элементом обучающихся подсистем искусственного интеллекта. Так как при обучении из совокупности имеющихся фактов
Основные модели вывода |
131 |
|
|
формируются путем обобщения новые понятия и правила, то индуктивные схемы вывода находят широкое применение при автоматизации процесса приобретения знаний.
Рассмотрим указанные модели вывода подробнее.
4.1. Дедуктивный вывод в исчислении предикатов
4.1.1. Формулировка задачи дедуктивного вывода
Вернемся к представлению задач в виде теорем (см. §2.1.3). Пусть задача описывается на языке исчисления предикатов. Если обозначить через Ф0 множество исходных утверждений и через Fg целевое утверждение, то задача, представленная в виде доказательства теоремы, формально может быть записана в виде
Ф0 Fg .
Иными словами, необходимо доказать, что формула Fg логически следует из множества формул Ф0.
Формула Fg логически следует из Ф0 , если каждая интерпретация, удовлетворяющая Ф0 , удовлетворяет и Fg. Когда множество Ф0 представлено формулами F1,F2,…,Fn, то задачей дедуктивного вывода исчисления предикатов является выяснение общезначимости формулы
F1 F2 ... Fn Fg .
В ходе вывода часто используют метод доказательства от обратного, т.е. устанавливают не общезначимость приведенной выше формулы, а невыполнимость формулы
F1 F2 ... Fn Fg
или
F1 F2 ... Fn Fg .
Иными словами, доказывают, что объединение Ф0 Fg невыполнимо. Та-
кое доказательство может быть существенно проще прямого вывода. Процесс установления невыполнимости некоторого множества формул назы-
вают опровержением.
Были разработаны эффективные методы автоматизации дедуктивного вывода. История их создания берет свое начало от основополагающих

132 |
Глава 4 |
|
|
работ Ж. Эрбрана, который предложил механическую процедуру дедуктивного вывода (1930). В 1965г. Дж. Робинсон разработал принцип резолюции, позволяющий автоматизировать процесс опровержения и являющийся теоретической базой для построения многих систем автоматического доказательства теорем. Именно эти два подхода будут рассмотрены в дальнейшем при описании дедуктивного вывода.
4.1.2. Стандартизация предикатных формул
Для осуществления дедуктивного вывода методом Эрбрана или на основе принципа резолюции, все формулы множества Ф0 Fg должны
быть представлены в виде дизъюнкций литералов.
Литералом называют элементарную формулу или ее отрицание. Дизъюнкция литералов называется предложением или клозом (от англ.
clause). Например, формула P(x) Q(x, y) R(x, y)является предложением.
Таким образом, формулы множества должны быть записаны в
форме предложений. Так как предложение содержит только знаки операций дизъюнкции и отрицания, причем отрицание должно распространяться не более чем на одну предикатную букву, то для приведения формулы к виду предложения необходимо исключить из неё все остальные операции и сократить область действия операции отрицания.
Приведение формул множества Ф0 Fg к виду предложений выпол-
няют в процессе указанных ниже тождественных преобразований.
Исключение знаков импликации и эквиваленции. Для этого ис-
пользуют равенства:
(P Q) P Q ,
(P Q) (P Q) (Q P).
Уменьшение области действия операции отрицания. При этом используют законы де Моргана:
(P Q) (P Q) , (P Q) (P Q),
xP(x) xP(x), xP(x) xP(x).
Например,
x(P(x) (Q(x) R(x))) x(P(x) (Q(x) R(x))).

Основные модели вывода |
133 |
|
|
Стандартизация переменных. В этом случае выполняют переименование переменных, связанных кванторами общности или существования. Переменные переименовываются так, чтобы каждый квантор связывал отдельную переменную, не встречающуюся в других кванторах. Например,
xP(x) xQ(x)
xP(x) zQ(z).
Исключение кванторов существования. В простейшем случае это соответствует правилу экзистенциальной конкретизации, которое позволяет перейти от xP(x) к Р(а), где а – константа (см. §3.2.3).
Если квантор существования находится в области действия квантора общности, задача становится сложнее. Рассмотрим, например, формулуx y(Q(y) R(x, y)), которая может означать, что для каждого x существует такой конкретный y, что верно Q(y) и R(x,y). В этой интерпретации значение переменной y зависит от значения переменной x. Такая зависимость представляется функцией y=f(x), которую называют функцией Сколема. Функция Сколема позволяет исключить квантор существования и переписать рассматриваемую формулу в виде x(Q( f (x)) R(x, f (x))).
Если квантор существования находится в области действия двух и более кванторов общности, то функция Сколема будет зависеть от двух и более аргументов. Для обозначения функции Сколема не должны применяться функциональные буквы, которые уже имеются в формулах.
Перемещение кванторов общности. Все кванторы общности запи-
сываются в начале формулы. Например, формула x(P(x) yQ(y))преобра-
зуется к виду x y(P(x) Q(y)).
Приведение к конъюнктивной нормальной форме. Для этого ис-
пользуется дистрибутивный закон: (A B) C (A C) (B C). Например, выражение (A B) (B C) приводится к конъюнктивной нормальной форме следующим образом:
(A B) (B C) [A (B C)] [B (B C)] (A B) (A C) B (B C).
Таким образом, любая формула из множества 0 Fg записывается в виде x1... xn (K1 K2 ... Kn ). Здесь каждый член Ki представляет со-
бой предложение (дизъюнкт), т.е. имеет вид (L1 L2 ... |
...Lk ), где Li – ли- |
терал. |
|
Исключение кванторов общности. Так как все переменные в фор-
мулах связаны кванторами общности, а порядок следования кванторов общности не имеет значения, то их можно не указывать в явном виде, то есть исключить.

134 |
Глава 4 |
|
|
Исключение конъюнкций. Любая интерпретация удовлетворяет формуле K1 K2 ... Kn в том случае, когда она удовлетворяет формулам K1, K2,…, Kn. Поэтому каждая формула, приведенная к конъюнктивной нормальной форме, может быть заменена множеством формул
K1,K2 ,...,Kn .
Рассмотрим пример преобразования формулы к множеству предложений. Пусть дана формула
x{P(x) { y[Q(x, y) R(y)]}.
Исключим знаки импликации:
x{P(x) { y[Q(x, y) R(y)].
Уменьшим область действия операции отрицания:
x{P(x) { y[Q(x, y) R(y)]}.
Исключим квантор существования:
x{P(x) [Q(x, f (x)) R( f (x))].
Приведем формулу к конъюнктивной нормальной форме:
x{(P(x) Q(x, f (x)) (P(x) R( f (x)))}.
Исключив квантор общности и конъюнкцию, получим множество предложений:
{P(x) Q(x, f (x)),P(x) R( f (x))}.
4.1.3. Метод Эрбрана
Как отмечалось выше, доказательство теоремы 0 Fg состоит в
том, чтобы показать, что расширенное множество формул, образованное путем объединения множества аксиом Ф0 и отрицания целевого утверждения Fg, невыполнимо. Обозначим расширенное множество формул, приведенных предварительно к виду предложений (дизъюнктов), через S. Множество дизъюнктов S невыполнимо тогда, когда не существует интерпретации, которая ему удовлетворяет. Для того чтобы это выяснить, необходимо перечислить все интерпретации на всех возможных областях. Очевидно, рассмотреть все интерпретации на всех областях невозможно. Но,

Основные модели вывода |
135 |
|
|
тем не менее, решение задачи может быть найдено. Оно основывается на понятии универсума Эрбрана. Универсум Эрбрана представляет такую область интерпретации H, что если не существует интерпретации множества предложений S в этой области, то ее не существует вообще. Универсум Эрбрана строится из константных термов и определяется следующим образом:
а) множество всех предметных констант, встречающихся в S, принадлежит H; если в S нет констант, то в H включается произвольная константа а;
б) множество всех функций, встречающихся в S и определенных на множестве термов из H, принадлежит H.
Проиллюстрируем построение универсума Эрбрана на примере.
Пусть
SP (x, f (x,a)) Q(x,a) R(x,b) .
Вмножество S входят предметные константы а и b, функциональная буква f. В этом случае область H представляет бесконечное счетное множе-
ство:
H a,b, f (a,a), f (a,b), f (b,a), f (b,b), f (a, f (a,a)), f (a, f (a,b)),... ,
которое формируют последовательно в виде уровней:
H0 a,b ,
H1 a,b, f(a,a), f(a,b), f(b,a), f(b,b) ,
H2 a,b, f(a,a),...,f(b,b), f(a, f(a,a)), f(a, f(a,b)),...,...
Здесь H0, H1, H2 и т.д. – уровни универсума Эрбрана и H H . Дизъюнкт, который не содержит переменных, называется фунда-
ментальным. Он получается заменой предметных переменных константными термами. Если термы являются элементами универсума Эрбрана, то фундаментальный дизъюнкт называют фундаментальным примером дизъюнкта. Множество всех фундаментальных атомов вида P(t1, t2,… tn,), где Р
– предикатные буквы, встречающиеся в S, а t1, t2,… tn – элементы универсума Эрбрана, называется эрбрановской базой для S. Например, эрбрановской базой для рассматриваемого выше примера является множество:
A P(a, f (a,a)),Q(a,a),R(a,b),P(b, f (b,a)),... .
Задание интерпретации множества S в области H заканчивают, когда с каждой атомарной формулой эрбрановской базы связано соответствующее значение истинности.

136 |
Глава 4 |
|
|
Введенные определения позволяют сформулировать теорему Эрбрана: множество дизъюнктов S невыполнимо тогда и только тогда, когда существует конечное невыполнимое подмножество фундаментальных примеров дизъюнктов в S. Данная теорема позволяет формально построить процедуру опровержения. Для установления невыполнимости множества дизъюнктов S необходимо: 1) образовывать множества S1, S2,…, Si,… фундаментальных примеров дизъюнктов для каждого уровня i множества H; 2) последовательно проверять их на ложность. Согласно теореме Эрбрана, если S невыполнимо, то процедура обнаружит такой уровень i, что Si будет ложным.
На указанном принципе работали первые программы доказательства теорем. Основным недостатком процедуры Эрбрана является экспоненциальный рост множества фундаментальных примеров Si при увеличении уровня i. Поэтому на практике удается с помощью процедуры Эрбрана доказывать только простые теоремы.
4.1.4. Принцип резолюции
Принцип резолюции представляет собой процедуру вывода, с помощью которой порождаются новые дизъюнкты из S. Если в ходе применения этой процедуры выводится пустое предложение, то S невыполнимо.
Правило вывода, лежащее в основе принципа резолюции, по существу, представляет собой расширение правила modus ponens и правила силлогизма. Данные правила вывода можно записать в форме:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A B, |
B C |
|
|||||
A, A B |
(modus ponens), |
(силлогизм). |
|||||||||
|
|
|
|
|
|
|
|
||||
B |
|
|
|
A |
C |
|
|||||
В каждом из этих правил имеются дизъюнкты-посылки, содержащие
дополнительные (контрарные) пары литер (A и А, В и В). Можно заметить, что следствие правил формально получается вычеркиванием в дизъюнктах-посылках контрарных пар литер и объединением оставшихся частей дизъюнктов.
Рассмотренные дизъюнкты-посылки содержали одну или две литеры. Дж. Робинсон распространил указанный прием на случай произвольных дизъюнктов с любым числом литер и сформулировал правило резолюции: если любые два дизъюнкта D1 и D2 содержат дополнительную пару литер,
например L и L , то, вычеркивая их, формируем новый дизъюнкт из оставшихся частей дизъюнктов D1 и D2. Вновь сформированный дизъюнкт называется резольвентой (следствием) исходных дизъюнктов. Резольвента, полученная из двух дизъюнктов, является логическим следствием этих
Основные модели вывода |
137 |
|
|
дизъюнктов. Правило резолюции позволяет получать резольвенты множества дизъюнктов S. Если в процессе вывода резольвент получаются два од- но-литеральных дизъюнкта, образующих контрарную пару, то резольвентой этих двух дизъюнктов будет пустой дизъюнкт, обозначаемый символом
NIL.
Объединение исходного множества дизъюнктов с множеством всех резольвент, которые могут быть образованы из дизъюнктов, входящих в S, будем обозначать R(S). Применяя принцип резолюции к R(S), получим R(R(S)) R2 (S). В общем случае Rn 1(S) R(Rn (S)). При этом R0(S)=S. Легко заметить, что если множество S невыполнимо, то Ri(S) при любых i≥1 также невыполнимо, и наоборот, если невыполнимо Ri(S), то невыполнимо и S. Это свойство называется полнотой принципа резолюций. Оно устанавливается следующей теоремой, доказанной Робинсоном: если S – произвольное конечное множество дизъюнктов, то S невыполнимо тогда и только тогда, когда Ri(S) содержит пустой дизъюнкт. Данная теорема позволяет построить процедуру опровержения, которая для исходного множества S последовательно строит множества R1(S), R2(S),…Ri(S) и проверяет, содержит ли множество Ri(S) пустой дизъюнкт.
Вывод с помощью резолюции наглядно можно проиллюстрировать с помощью графа опровержения. Вершинами графа являются исходные дизъюнкты и резольвенты, получаемые в процессе вывода. Дизъюнкты исходного множества S представляют вершины графа, располагаемые в его верхней части. Если два дизъюнкта, находящиеся в каких-либо вершинах графа, образуют резольвенту (разрешаются), то вершина, соответствующая резольвенте, изображается ниже данных дизъюнктов и соединяется с ними ребрами.
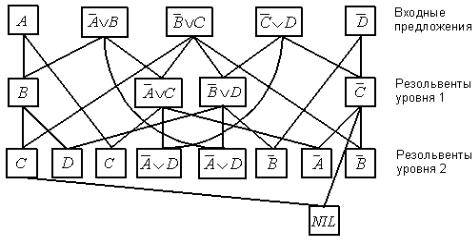
В качестве примера на рисунке 4.1 построен граф опровержения множества исходных дизъюнктов:
S A, A B, B C, C D, D .
В логике высказываний нахождение контрарных пар не вызывает трудностей. Сложнее обстоит дело в логике предикатов. Например, если имеются дизъюнкты P(x, f (x)), P(a, y) Q(z), Q(b), то резольвента может быть получена только после выполнения следующих подстановок: а вместо x, f(x) вместо y, b вместо z. Затем по правилу резолюции получается пустое предложение.
Подстановкой называется конечное множество
t1 / x1, t2 / x2, ,tn / xn ,
138 |
Глава 4 |
|
|
где xi - переменная; ti - терм, отличный от xi, 1 ≤ i ≤ n. Применение подстановки к некоторой формуле F означает замену всех вхождений переменной xi на терм ti. Формулу, получившуюся в результате подстановки, обозначают Fα и называют примером F. Для предыдущего примера подстановку можно записать в форме a/ x, f (x)/ y, b/ z . Тогда пример формулы P(x, f (x)) будет иметь вид P(x, f (x)) P(a, f (a)).
Рисунок 4.1 – Граф опровержения
Композицией двух подстановок α и β называется подстановка αβ, получаемая применением подстановки β к термам подстановки α с добавлением из β всех пар ti /xi, содержащих переменные, отсутствующие в α. На-
пример, если f (x)/z , |
a/x,b/ y,c/ z , |
то композиция подстановок |
будет соответствовать множеству f (a)/ z, |
a/ x, b/ y . |
|
Подстановки выполняются с целью приведения литералов к некоторой общей унифицированной форме, чтобы затем исключить образовавшиеся контрарные пары литералов. Подстановка α называется унификатором для множества литералов {L1, L2,…, Lk}, если L1α = L2α = … = Lkα.
Например, литералы P(y, f(x)), P(a,z) с помощью подстановки |
|
1 a/ y, |
f (x)/ z преобразуются к виду P(a,f(x)). Следовательно, 1 явля- |
ется унификатором указанного множества литералов. Если ввести подста-
новку 2 |
b/ x , то можно убедиться в том, что композиция подстановок |
1 2 |
также унифицирует рассматриваемое множество литералов и пре- |
образует их к виду P(a, f(b)). Поэтому подстановка α – тоже унификатор. Однако подстановка получается из подстановки 1 с помощью 2 .
Унификатор, который позволяет получить все другие унификаторы с помощью подходящих подстановок, называется наиболее общим унификатором (НОУ). Чтобы получить резольвенту, необходимо найти НОУ.
Основные модели вывода |
139 |
|
|
Рассмотрим алгоритм построения НОУ на примере множества литералов:
P(g(x), x, f (x)), P(y,a,x) .
Если два литерала имеют общую переменную, то необходимо ее заменить новой переменной в одном из них. Заменив переменную x на z во втором литерале, получим P(x,a,z). Далее, рассматриваем слева направо каждый из литералов и находим позиции, в которых обнаруживается не совпадение термов. В данном случае не совпадают термы g(x) и y. Эти термы образуют множество рассогласования {g(x),y}, где y – переменная. Поэтому выполняется подстановка 1 g(x)/ y , которая преобразует множество исходных литералов к виду {P(g(x)), x, f(x)), P(g(x)), a, z)}. Продолжая процесс сопоставления термов, обнаруживаем несовпадение x и a, которые формируют множество рассогласования {x,a}, соответствующее подстановке 2 ={a/x}. Применив 2 к множеству унифицируемых литералов, получим {P(g(a)),a,f(a)),P(g(a)),a,z)}. Наконец, обнаружив несовпадение литералов f(a) и z, выполняем подстановку3 ={f(a)/z}. Таким образом, НОУ представляет композицию подстановок
3 1 2 3 .
Алгоритм поиска НОУ для двух литералов L1 и L2, не содержащих общих переменных, можно представить в виде процедуры [86]:
Procedure Unify(L1,L2); Begin
α:=[ ]; {пустая подстановка}
Q1:=L1; Q2:=L2;
While True Do
Begin
Построить множество рассогласования D для цепочек символов, образующих Q1 и Q2;
If D=[ ] Then Возврат(α); t1=first(D); t2=last(D);
If var(t1) and non_contain(t1,t2) Then α1:={ t2/t1}
Else If var(t2) and non_contain(t2,t1) Then α1={ t1/t2}
Еlse Выход('Неудача'); Q1:=Q1α1;
Q2:=Q2α1;
α :=αα1 End
End.