

Точно Не проект 2 / Не books / Источник_1
.pdf200 |
Глава 4 |
|
|
г) обобщением некоторого свойства в соответствии с иерархией обобщений, например, предикаты
форма(Х, прямоугольная),
форма(Х, треугольная)
обобщаются с помощью формулы
форма(Х, многоугольная)
для иерархии обобщений, изображенной на рисунке 4.26.
Рисунок 4.26 – Иерархия обобщений
Если понятие р является более общим, чем понятие q, то р – охваты-
вающее понятие для q.
В алгоритме Митчелла примеры представляются при помощи атомарных формул исчисления предикатов, и в ходе поиска строятся (восстанавливаются) продукционные правила, посылки которых являются конъюнкциями указанных атомов. Восстановленные правила должны обеспечивать правильную классификацию предъявляемых примеров, т.е. отнесение их к тому или иному классу (понятию) по минимальной совокупности отличительных признаков.
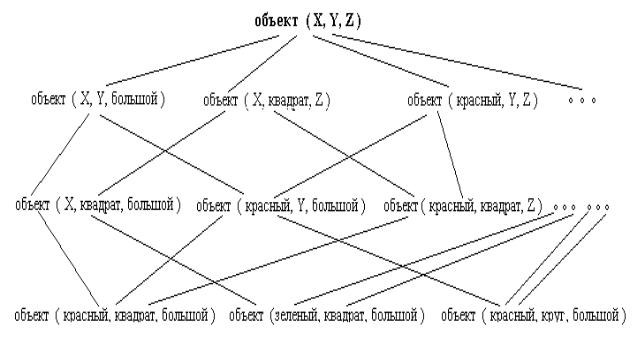
Рассмотрим пример. Пусть имеется множество объектов, характеризуемых следующими свойствами и их возможными значениями:
цвет = {желтый, зеленый, красный, синий};
форма = {круг, квадрат, треугольник}; размер = {маленький, средний, большой}.
Каждый из объектов можно представить предикатом
объект(Цвет, Форма, Размер),
которому соответствует пространство понятий, изображенное на рисунке 4.26. Требуется на основании предъявляемых примеров построить правило, позволяющие обнаруживать круг красного цвета.
Основные модели вывода |
201 |
|
|
Рисунок 4.26 – Пространство понятий
Будем использовать следующие обозначения: G – множество наиболее общих понятий-кандидатов g, g G ; S – множество наименее общих (наиболее специализированных) понятий-кандидатов s, s S . Алгоритм исключения понятий кандидатов формулируется следующим образом:
1)создать множество G, включив в него наиболее общее понятие пространства поиска;
2)создать множество S, включив в него первый положительный пример;
3)для каждого положительного примера р выполнить следующее:
-исключить из G все понятия-кандидаты, не охватывающие р;
-для каждого s S, если s не сопоставимо с р, заменить s более общим понятием, сопоставимым с р, выполнив минимально возможное обобщение;
-исключить из S все понятия-кандидаты более общие, чем любое другое понятие, входящее в S;
-исключить из S все понятия-кандидаты, охватывающие некоторые понятия, входящие в G;
4) для каждого отрицательного примера n выполнять следующее;
-исключить из S все понятия-кандидаты, охватывающие n;
-для каждого g G , если g сопоставимо с n, заменить g менее общим понятием, не сопоставимым с n, выполнив минимально возможную специализацию;
202 |
Глава 4 |
|
|
-исключить из G все понятия-кандидаты менее общие, чем любое другое понятие, входящее G;
-исключить из G все понятия-кандидаты, не охватывающие некоторые понятия, входящие в S;
5) если G = S и оба множества являются одноэлементным, то найденное понятие согласуется со всеми данными, и поиск заканчивается;
6)если G и S – пустые множества, то не существует понятия, которое охватывает все положительные примеры и не охватывает ни одного отрицательного примера.
Процесс обучения понятию “красный круг” с помощью рассмотренного алгоритма представлен в таблице 4.3
Таблица 4.3 – Обучение понятию “красный круг”
№ |
Положительные (р) и |
Множества G и S |
|
отрицательные (n) примеры |
|
0 |
- |
G: объект(X, Y, Z). |
|
|
S: { }. |
1 |
р: объект(средний, круг, красный) |
G: объект(X, Y, Z). |
|
|
S: объект(средний, круг, |
|
|
красный). |
2 |
n: объект(средний, квадрат, зеленый) |
G: объект(X, Y, красный), |
|
|
объект(X, круг, Z). |
|
|
S: объект(средний, круг, |
|
|
красный). |
3 |
р: объект(большой, круг, красный) |
G: объект(X, Y, красный), |
|
|
объект(X, круг, Z). |
|
|
S: объект(X, круг, красный). |
4 |
n: объект(средний, треугольник, красный) |
G: объект(X, круг, красный). |
|
|
S: объект(X, круг, красный). |
Отметим, что множества G и S, представленные в таблице 4.3, содержат только окончательные результаты, соответствующие третьему и четвертому пунктам рассматриваемого алгоритма. Так, в случае предъявления отрицательного примера
объект(средний, квадрат, зеленый)
множество G на первом этапе расширяется при выполнении операции специализации за счет понятий-кандидатов, не сопоставимых с примером:
объект(X, Y, желтый),
объект(X, Y, красный),
объект(X, Y, синий),
объект(X, круг, Z),
объект(X, треугольник, Z), объект(маленький, Y, Z), объект(большой, Y, Z).
Основные модели вывода |
203 |
|
|
Затем из множества G исключаются все понятия-кандидаты, не охватывающие понятий, содержащихся во множестве S. В итоге в G остаются два понятия
объект(X, Y, красный),
объект(X, круг, Z),
что отражено в таблице 4.3 . Такое свойство алгоритма объясняется тем, что S – множество наименее общих понятий, которые охватывают положительные примеры, поэтому любое новое понятие, включаемое в G в ходе операции специализации и не сопоставимое с любым из понятий, входящих в S, не может охватывать положительных примеров и должно быть исключено.
Имеет место симметричная ситуация, когда выполняется операция обобщения S. Так как G – множество наиболее общих понятий, которые не охватывают ни одного отрицательного примера, то любое более общее понятие, включаемое в S, будет сопоставимо с некоторым отрицательным примером. Следовательно, оно должно быть исключено.
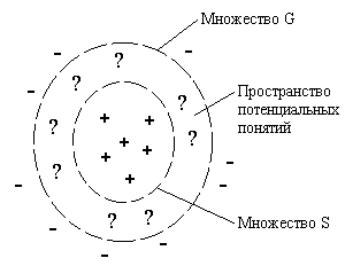
Условно поиск понятий в пространстве версий можно представить в виде рисунка 4.27 [77]. Здесь знаком “+” отмечены положительные обучающие примеры, а знаком “-” – отрицательные примеры.
Рисунок 4.27 – Обучение в соответствии с алгоритмом Митчелла
Множество S включает наименее общие понятия, которые охватывает все положительные примеры. Множество G включает наиболее общие понятия, которые не охватывают ни одного отрицательного примера. Любое понятие более общее, чем понятие из G, будет охватывать некоторые отрицательные примеры; любое понятие менее общее, чем понятие из S,
204 |
Глава 4 |
|
|
может не охватывать некоторые положительные примеры. Поэтому в процессе обучения граница множества G сужается, чтобы исключить понятия, охватывающие отрицательные примеры, а граница множества S расширяется за счет включения понятий, охватывающих положительные примеры. Процесс специализации понятий, входящих в G , и обобщения понятий, входящих в S, заканчивается успешно, когда множества G и S будут содержать одно и то же понятие.
Таким образом, алгоритм Митчелла относится к группе поисковых алгоритмов обучения. При этом выполняется поиск в ширину, что не эффективно, если множества G и S быстро расширяются. В этом случае могут применяться методы эвристического поиска.
В алгоритме Митчелла предполагается, что каждый класс описывается одним конъюнктивным правилом, и предъявляемые примеры не искажены шумом. На практике часто необходимо восстанавливать правила в условиях зашумленных данных. Алгоритм Митчелла весьма чувствителен к предъявляемым примерам. Даже один ошибочный пример может привести к потере сходимости.
4.3.4. Алгоритм обобщения ID3
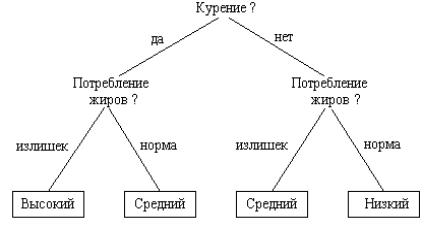
Алгоритм ID3 (Iterative Dichotomizer 3) был предложен Дж. Квинланом в 1983 г. Также как и алгоритм Митчелла, он обеспечивает индуктивное формирование понятий по примерам. Однако понятия в этом случае представляются с помощью деревьев решений. Каждый нетерминальный узел дерева решений соответствует некоторому признаку классификации, а ветви, выходящие из узла, характеризуют альтернативные значения признака. Терминальные узлы дерева решений определяют класс (понятие), к которому относится предъявленный пример. На рисунке 4.28 изображен фрагмент дерева решений при определении степени риска сердечно-сосудистых заболеваний.
Алгоритм ID3 обеспечивает построение простейшего дерева решений, которое охватывает все предъявленные примеры. Построение дерева в соответствии с алгоритмом ID3 выполняется в направлении сверху вниз. В этом случае каждый признак разделяет множество обучающих примеров на подмножества, содержащие примеры с одинаковым значением того или иного признака. Затем алгоритм рекурсивно применяется к подмножествам и т.д. Процесс продолжается, пока предъявленный пример не будет отнесен к заданному классу.
В общем случае различный порядок анализа признаков приводит к построению разных деревьев решений. В алгоритме ID3 для определения по-
Основные модели вывода |
205 |
|
|
рядка, в котором анализируются признаки, используется информационный критерий. Сформулируем алгоритм индуктивного построения деревьев решений, а затем рассмотрим критерий отбора признаков.
Представим алгоритм в виде рекурсивной функции на псевдоязыке [77]. При этом будем использовать следующие обозначения: MP – множество примеров; SP – список признаков классификации; V(P) – множество значений признака Р; v – значение признака Р, v V(P).
Function Induce_Tree(MP, SP);
Begin
If Все элементы множества МР принадлежат одному классу
Then
Вернуть лист дерева, снабдив его меткой класса
Else If список SP пустой Then
Вернуть лист дерева, представив его в виде дизъюнкции
всех классов, формирующих множество МР
Else Begin
Выбрать в качестве корня нового поддерева
очередной признак Р;
Удалить признак Р из списка SP;
For v V(P) Do Begin
Создать ветвь дерева, снабдив ее меткой v; Сформировать из МР подмножество примеров МРv,
признак Р для которых имеет значение v;
Осуществить вызов Induce_Tree (MPv, SP) и
присоединить возвращаемое поддерево к ветви v
End End
End.
Рисунок 4.28 – Фрагмент дерева решений
206 |
Глава 4 |
|
|
Рассмотрим процесс построения дерева решений, изображенного на рисунке 4.28. Множество примеров MP задано таблицей 4.4
Таблица 4.4– Примеры оценки риска сердечно-сосудистых заболеваний
№ |
Риск |
Курение |
Потребление жиров |
1 |
Высокий |
да |
излишек |
2 |
Средний |
да |
норма |
3 |
Средний |
нет |
излишек |
4 |
Низкий |
нет |
норма |
При первом вызове функции Induce_Tree в качестве корня дерева выбирается признак “курение”, который характеризуется двумя значениями “да” и “нет”. Эти значения разбивают множество примеров МР на два подмножества МР1 и МР2. Элементами первого подмножества являются примеры 1 и 2. Элементами второго подмножества – примеры 3 и 4. Для каждого из подмножеств МР1 и МР2 функция Induce_Tree вызывается рекурсивно. При этом в ходе каждого из вызовов происходит дальнейшее разбиение подмножеств МР1 и МР2, но уже относительно признака потребления жиров. В этом случае образуются подмножества, составленные из элементов одного класса, и рекурсия возвращает листья дерева (рисунок 4.28), снабженные метками соответствующих классов. Листья связываются с соответствующими ветвями, отмеченными возможными значениями признака “потребление жиров”, т.е. “норма” и “излишек”. В итоге формируются два поддерева, соответствующие подмножествам МР1 и МР2. Указанные поддеревья, в свою очередь, связываются с ветвями, отмеченными возможными значениями признака “курение”, и процесс формирования дерева решений завершается.
Каждый вызов функции Induce_Tree формирует очередное поддерево решений, корень которого представляется признаком Р. В качестве критерия выбора очередного признака используется количество информации, обусловленное включением того или иного признака в дерево решений.
Пусть имеются независимые и несовместные сообщения х1, х2,…, хn, вероятности получения которых равны р(х1), р(х2),…, р(хn). Тогда количество информации для всей совокупности сообщений можно оценить с помощью меры К. Шеннона:
n |
|
I(x) p(xi )log2 p(xi ). |
(4.20) |
i 1 |
|
Если рассматривать обучающие примеры как сообщения, то с помощью (4.20) можно оценить количество информации, содержащееся в обучающей выборке и, следовательно, в дереве решений, которое охватывает
Основные модели вывода |
207 |
|
|
данную обучающую выборку. Так, для обучающей выборки, заданной таблицей 4.4 и соответствующей дереву решений, изображенному на рисунке 4.28 , получим р(высокий) = 1 ∕ 4 ; р(средний) = 2 ∕ 4 ; р(низкий) = 1 ∕ 4, и
1 |
|
1 |
2 |
|
|
2 |
1 |
|
1 |
|
1 |
|
1 |
1 |
3 |
|
||||||||
I(x) |
|
log ( |
|
) |
|
log |
|
|
|
|
|
|
log ( |
|
) |
|
log ( |
|
) |
|
( 3) |
|
1,5 |
бит. |
|
4 |
|
|
|
|
2 |
|
|
|
|||||||||||||||
4 |
2 |
4 |
2 |
4 4 |
2 |
4 |
2 |
8 |
2 |
2 |
|
|||||||||||||
Количество информации, обусловленное включением того или иного признака в дерево решений, определяется как разность между количеством информации, соответствующим всему дереву решений, и количеством информации, соответствующих поддеревьев, расположенных ниже узла, определяемого выбранным признаком классификации. Количество информации, содержащееся во всех указанных поддеревьях, представляет ожидаемый объем информации, который может быть получен после их построения.
Пусть имеется множество примеров МР. Если на очередном шаге классификации выбирается признак Р, характеризуемый n значениями, то множество МР разбивается на n подмножеств MP1, MP2, …, MPn. Тогда ожидаемый объем информации, связанный с построением поддеревьев, соответствующих подмножествам MP1, MP2, …, MPn, будет равен
n |
| MP | |
|
|
E(P) |
i |
I(MPi ) , |
|
| MP | |
|||
i 1 |
|
где |MP|, |MPi| - соответственно мощности множеств MP и MPi; I(MPi) - количество информации, соответствующее поддереву множества MPi.
Количество информации, получаемое при выборе признака Р, определится из выражения
G(P) I(MP) E(P) .
На каждом шаге выполнения алгоритма ID3 выбирается признак Р, обеспечивающий максимальное количество информации G(P).
Алгоритм ID3 можно рассматривать как поиск, соответствующий алгоритму подъема на гору в пространстве возможных деревьев решений. На каждом шаге поиска анализируются все признаки, которые могут использоваться для расширения текущего дерева решений. Выбирается тот признак, который обеспечивает получение максимального количества информации.
Рассмотренный метод индуктивного построения деревьев решений применяется при решении многих задач классификации. Например, алгоритм ID3 применялся при обучении классификации окончаний шахматных
208 |
Глава 4 |
|
|
партий (король и ладья против короля и пешки [28]), при классификации заболеваний щитовидной железы. Это один из наиболее широко используемых методов индуктивного восстановления правил по примерам, обеспечивающий автоматическое построение баз знаний диагностических экспертных систем.
Вопросы для самопроверки
1.Приведите формулировку задачи дедуктивного вывода в терминах логики исчисления предикатов.
2.Сформулируйте этапы стандартизации предикатных формул.
3.Преобразуйте формулу x y{[P(x, y) Q(y)] zR(x, y,z)} к виду предложения.
4.Найдите НОУ для множества литералов {P(x,f(x),a), P(b,y,x)}.
5.Получите следствие xL(x) из посылок x(S(x) L(x)) и ( x)( S(x)), используя принцип резолюции.
6.Назовите и объясните основные стратегии поиска, применяемые в ходе выполнения процедуры резолюции.
7.Приведите пример применения принципа резолюции в ходе информационного поиска.
8.Сформулируйте и приведите пример решения задачи планирования перемещения робота на основе принципа резолюции.
9.Объясните общую схему поиска решения в системе STRIPS.
10.Какие три вида дизъюнктов лежат в основе языка Пролог?
11.Постройте дерево опровержения для целевого утверждения ?- member(1,[2,1,3]).
12.Назовите и объясните виды неопределенности.
13.Запишите и объясните формулу Байеса для вычисления апостериорной условной вероятности гипотезы Н
14.Объясните метод обработки неопределенности, используемый в системе
PROSPECTOR.
15.Объясните метод обработки неопределенности, используемый в системе
MYCIN (EMYCIN).
16.Как вычисляются степени доверия и правдоподобия в теории свидетельств Демпстера-Шефера.
17.Приведите и объясните определения нечеткой и лингвистической переменной.
18.Сформулируйте основные операции нечетких множеств.
19.Объясните понятие нечеткого отношения.
20.Представьте в виде нечеткого отношения правило “ если А, то B”, где А и В – нечеткие множества.
21.Что понимают под композицией нечетких отношений?
22.Сформулируйте правила вычисления функции принадлежности многозначной логики.
23.Приведите примеры нечетких правил вывода, предложенных Л. Заде в рамках лингвистической логики.
24.Какие выводы называют правдоподобными?
Основные модели вывода |
209 |
|
|
25.Что понимают под немонотонным выводом?
26.Запишите правило умолчания в общем виде. Что называют нормальным умолчанием?
27.Что понимают под системой поддержания значений истинности?
28.В чем отличие между дедукцией и индукцией?
29.Сформулируйте определение для термина “понятие”.
30.Какое понятие называют конъюнктивным?
31.Сформулируйте постановку задачи индуктивного формирования понятий.
32.Что понимают под обучением с учителем и без учителя?
33.Сформулируйте правило индуктивного обобщения.
34.Объясните суть алгоритма индуктивного обучения Уинстона.
35.Сформулируйте алгоритм исключения кандидатов Митчелла.
36.Объясните основную идею алгоритма построения деревьев решений ID3.
37.Сформулируйте критерий выбора очередного признака классификации в алгоритме ID3.