

Точно Не проект 2 / Не books / Источник_1
.pdf240 |
Глава 5 |
|
|
(defun factorial-prog (n)
(prog ((counter 1)(result 1))
A(setq result (* result counter))
(setq counter (+ counter 1))
(if (= counter (+ n 1)) (return result))
(go A)))
Здесь переменные COUNTER и RESULT получают начальные значения, равные единице.
PROG-форма была введена в ранних версиях языка Лисп и называлась PROG-механизмом. В связи с введением более развитых форм циклических вычислений PROG-форма находит ограниченное применение.
5.12. Рекурсивные функции
Функция называется рекурсивной, если в ее определении содержится обращение к ней самой. Рекурсивное определение функций часто встречается в математике. Например, определение факториала
N! (N 1)!N
или чисел Фибоначчи
F1 1, |
|
|
F2 |
1, |
|
Fn |
Fn 1 Fn 2, |
n 2. |
Лисп специально создавался для рекурсивных вычислений, и вся сила языка как раз и заключена в возможности широкого использования рекурсивных функций. Продемонстрируем это на примере вычисления факториала:
(defun factorial (n)
(cond ((zerop n) 1)
(t (* (factorial (- n 1)) n))))
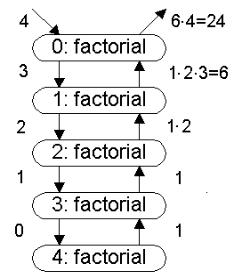
Данная функция непосредственно реализует рекурсивное определение факториала, применяемое в математике. На рисунке 5.6,а изображена схема рекурсивных вызовов при вычислении факториала числа 4. Овалы, представленные на рисунке, изображают вызовы функции FACTORIAL.
Язык Лисп |
241 |
|
|
Числа, записанные рядом со стрелками, направленными вниз, соответствуют значениям аргументов вызова. Числа при стрелках, направленных вверх, представляют возвращаемые значения. Вычисление факториала числа 4 требует четырех рекурсивных вызовов. Рекурсивные вызовы прекращаются при вычислении факториала нуля. Возвращаемые значения рекурсивных вызовов подставляются в точку предыдущего вызова функции FACTORIAL, формируя конечный результат. Рассмотренная схема представляет собой простую рекурсию. Здесь рекурсивный вызов происходит в одной ветви COND и только один раз.
Процесс рекурсивных вызовов можно исследовать, используя возможности трассировки (рисунок 5.6,б). Включение и выключение механизма трассировки выполняется с помощью входящих в состав интерпретатора директив TRACE и UNTRACE:
(trace factorial) (factorial 4) (untrace factorial)
>(trace factorial) (factorial)
>(factorial 4)
0:(factorial 4) 1: (factorial 3) 2: (factorial 2)
3: (factorial 1)
4: (factorial 0) 4: returned 1
3: returned 1
2: returned 2 1: returned 6
0: returned 24
> 24
а) б)
Рисунок 5.6 – Рекурсивное вычисление факториала и трассировка
Рассмотрим более сложную схему рекурсивных вызовов на примере формирования чисел Фибоначчи. Каждое число последовательности Фибоначчи определяется как сумма двух предыдущих:
1, 1, 2, 3, 5, 8, 13, 21, …
242 |
Глава 5 |
|
|
Для того чтобы вычислить очередное число Фибоначчи, необходимо знать два предшествующих. Это легко реализуется с помощью следующей функции:
(defun fibonacci (n) (cond ((= n 0)1)
((= n 1) 1)
(t (+ (fibonacci(- n 1)) (fibonacci (- n 2))))))
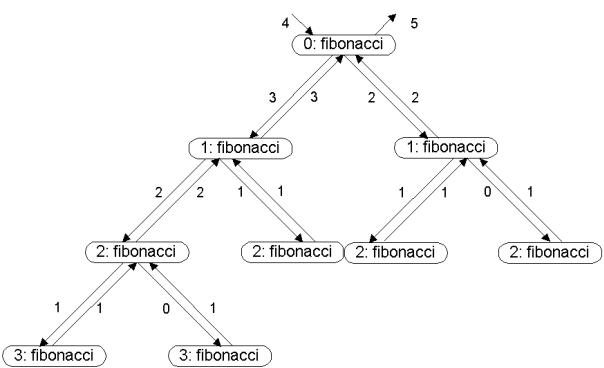
На рисунке 5.7 изображена схема рекурсивных вызовов при определении четвертого числа Фибоначчи. Каждый вызов функции FIBONACCI сводится к двум другим рекурсивным вызовам этой же функции, т.е. функция реализует схему так называемой параллельной рекурсии [48]. Программирование подобной схемы управления вычислительным процессом с помощью итерационных циклов было бы весьма затруднительно. В то же время приведенный пример демонстрирует не только ясность и простоту функции FIBONACCI, но и ее недостатки. Как видно из рисунка 5.7, при вычислении функции происходят повторные вызовы для одних и тех же значений аргументов. К счастью, имеется возможность исключить лишние вы-
зовы [48].
Рисунок 5.7 – Рекурсивные вызовы при вычислении функции FIBONACCI
Рассмотренные примеры касались числовой обработки. Лисп позволяет также эффективно определять рекурсивные функции для обработки символьных данных. Определим упрощенную версию функции MEMBER. Чтобы отличать ее от функции, встроенной в систему назовём ее
Язык Лисп |
243 |
|
|
MY-MEMBER. Функция проверяет, входит ли элемент Х в список У и возвращает подсписок У, начинающующийся с обнаруженного элемента:
(defun my-member (х у)
(cond ((null у) nil) ((equal х (first у)) у)
(t (my-member х (rest у)))))
В функции выполняется сравнение элемента Х с первым элементом списка У. Если обнаруживается совпадение, то функция возвращает список У. Если совпадение не обнаружено, то продолжается поиск элемента Х в хвосте списка У. Для этого рекурсивно вызывается функция MY-MEMBER. Первое условие формы COND на каждом шаге рекурсии контролирует список У. Если этот список исчерпан, то определяемая функция MY-MEMBER возвратит значение NIL. Функция MY-MEMBER использует простую рекурсию.
Примером функции, выполняющей символьную обработку и основанной на параллельной рекурсии, может служить рекурсивная версия функции MY-INTERSECTION:
(defun my-intersection (a b) |
|
(cond |
|
((null a) nil) |
;1) |
((member (first a) b) |
;2) |
(cons (first a)(my-intersection (rest a) b))) |
|
(t (my-intersection (rest a) b)))) |
;3) |
Данная функция вычисляет список общих элементов двух списков А
иВ. В определении функции реализованы три правила:
1)если список А исчерпан, то список общих элементов пустой;
2)если первый элемент списка А входит в список В, то этот элемент добавляется к списку общих элементов списков (REST А) и В; такой список формируется рекурсивным вызовом функции MYINTERSECTION, применяемой к хвосту списка А и исходному списку
В;
3)если первый элемент списка А не входит в список В, то строится
список общих элементов из хвоста списка А и списка В с помощью рекурсивного вызова функции MY-INTERSECTION.
Ранее функция MY-INTERSECTION была определена с помощью итерационных циклов. Рекурсивная версия функции ближе к естественному пониманию отношения “общие элементы” и выглядит элегантнее. Однако в общем случае, по быстродействию и эффективности использования памяти, рекурсивные версии функций часто уступают итерационным версиям этих функций.
244 |
Глава 5 |
|
|
5.13. Структурно-разрушающие функции
Все рассмотренные до сих пор функции манипулировали точечными парами или списками, не модифицируя их представление в памяти. Например, добавление элемента Z в множество, представленное символом L , не меняет исходного списка L:
(setf l ’(a b c d e)) (A B C D E)
(adjoin ’z l) (Z A B C D E)
l(A B C D E)
ВЛиспе имеются функции, при помощи которых можно непосредственно изменять структуры, хранящиеся в памяти. Такие функции называют структурно-разрушающими. К ним относятся функции NCONC,
RPLACA, RPLACD и DELETE.
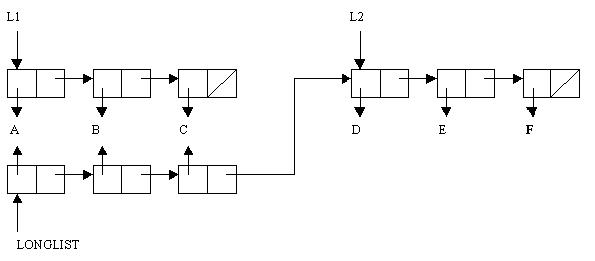
Для того чтобы лучше понять суть операций, выполняемых этими функциями, рассмотрим представление списков в памяти ЭВМ. Пусть требуется создать два списка L1 и L2, а затем объединить их в один список
LONGLIST:
(setf l1 ’(a b c) l2 ’(d e f)) (D E F)
(setf longlist (append l1 l2)) ( A B C D E F)
Структуры данных, образующиеся в памяти при выполнении указанных функций, показаны на рисунке 5.8.
Рисунок 5.8 – Формирование списка LONGLIST с помощью функции APPEND
C помощью первого вызова формы SETF создаются списки (А В С) и (D E F), на которые указывают соответственно указатели L1 и L2. Во втором вызове SETF происходит обращение к функции APPEND, которая ко-

Язык Лисп |
245 |
|
|
пирует структуру списка L1 и объединяет ее со структурой списка L2. Таким образом, создание нового списка LONGLIST не привело к разрушению иcходных списков L1 и L2, т.е.
l1 (А В С)
l2 (D E F)
longlist (А В С D E F)
Функция APPEND определяется в Лиспе через функцию CONS, конструирующую лисповскую ячейку. Именно с помощью CONS создается копия первого списка. На это требуется определенное время и дополнительная память. Если разрушение первого списка несущественно, то создание списка LONGLIST можно выполнить быстрее, применив вместо
APPEND функцию NCONC:
(setf l1 ’(a b c) l2 ’(d e f)) (D E F)
(setf longlist (nconc l1 l2)) (А В С D E F)
Соответствующие структуры данных изображены на рисунке 5.9. Функция NCONC выполняет объединение списков без копирования, меняя значение второго указателя в последней ячейке списка L1.
Рисунок 5.9 – Формирование списка LONGLIST с помощью функции
NCONC
При запросе значений символов L1, L2 и LONGLIST, интерпретатор вернет следующее:
l1 (А В С D E F)
l2 (D E F)
longlist (A B C D E F)
В Лиспе имеются функции RPLACA и RPLACD, позволяющие непосредственно изменять указатели лисповских ячеек. Обе эти функции в качестве первого аргумента требуют точечную пару. Второй аргумент может быть символом или точечной парой. Функция RPLACA меняет первый ука-
246 |
Глава 5 |
|
|
затель точечной пары таким образом, чтобы он указывал на второй аргумент, заданный в вызове функции:
(setf x ’(a b c)) (А В С)
(rplaca x ’d) (D B C) x (D B C)
Функция RPLACD выполняет аналогичные действия над вторым указателем точечной пары:
(setf x ’(a b c))
(rplacd x ’(1 2))
х (А 1 2)
(А В С)
(А 1 2)
Функция DELETE является деструктивной версией функции REMOVE. Если функция REMOVE сначала копирует список, а затем удаляет из него заданный элемент, то функция DELETE разрушает исходный список в процессе удаления из него элемента:
(setf s ’(х х у у х у)) (Х Х У У Х У)
(delete ’x s) (У У У) s (Х Х У У У)
Здесь значение списка S соответствует некоторому переходному состоянию. Для того чтобы исключить такие неопределенные результаты, необходимо сохранять результирующий список с помощью SETF:
(setf s (delete ‘x s)) (У У У) s (У У У)
При работе с рассмотренными выше функциями следует учитывать два обстоятельства:
1)функции NCONC, RPLACA, RPLACD и DELETE выполняют пре-
образования непосредственно над исходными списками, и поэтому они весьма эффективны, хотя и являются деструктивными;
2)функции APPEND и CONS безопаснее, но не столь эффективны, так как требуют свободных ячеек памяти.
Необходимо отметить, что в процессе преобразования списков в памяти ЭВМ могут возникать лисповские структуры, на которые потеряны указатели. Например,
(setf s ’(a b c d e ) ) (A B C D E) (setf s ’(x y z)) (X Y Z)
Язык Лисп |
247 |
|
|
Здесь, в результате связывания символа S c новым списком (X Y Z), доступ к списку (A B C D E) станет невозможным. Структуры, недоступные программе, представляют собой мусор. Для повторного использования ячеек памяти в Лисп-системах предусмотрен сборщик мусора (garbage collector – gc), который запускается автоматически. Сборщик мусора может быть запущен и принудительно, путем ввода директивы gc. Он собирает ячейки памяти, на которые нет указателей, в список свободной памяти
(free-storage-list).
5.14. Ассоциативные списки и списки свойств
Ассоциативным списком или а-списком называется список, состоя-
щий из точечных пар
((x1 . y1)( x2 . y2) … (xn . yn)),
где хi и уi– произвольные s-выражения, i=1, … , n.
Первый элемент каждой точечной пары представляет собой некоторый ключ, а второй – данные, ассоциированные с ключом. Ассоциативный список ставит в соответствие ключу хi выражение уi . Так как любой список можно представить в виде точечной пары, то список, состоящий из подсписков – а-список. Например,
((ivanov 1978 1)(petrov 1979 2) (sidorov 1980 3))
Для работы с ассоциативными списками в Лиспе имеется ряд встроенных функций. Функция PAIRLIS строит а-список из списков ключей и данных. Формат функции:
(pairlis ключи данные [ а-список ])
Функция добавляет новые точечные пары, образованные из списков
ключи и данные, в начало а-списка. Например,
(setf x (pairlis ’(a b d) ’(1 2 3) ’((c . 4))) ((D . 3) (B . 2) (A . 1) (C . 4))
Если а-список при вызове функции PAIRLIS не задан, то образуемые точечные пары добавляются в пустой список.
Функция ASSOC выполняет поиск в ассоциативном списке. Она возвращает в качестве значения первую по порядку точечную пару, у которой ключ совпадает с заданным аргументом поиска:
248 |
Глава 5 |
|
|
(assoc ’d x) (D . 3)
В Коммон Лиспе имеется также обратная функция RASSOC, которая ищет по данным ключ
(rassoc 4 x) (C . 4)
Функция ACONS строит точечную пару из двух своих аргументов и добавляет ее в начало а-списка:
(acons ’a 1 x) ((A . 1)(D . 3)(B . 2)(A . 1)(C . 4))
Дальнейшим развитием понятия а-список является список свойств. В Лиспе с символом можно связать значение. Это значение может быть числом, списком или другим символом. Например, символу можно присвоить значение а-списка:
(setf person ‘((name ivan) (age 25)
(sport football)))
((NAME IVAN)(AGE 25)(SPORT FOOTBALL))
Вэтом случае значение символа можно рассматривать как множество подсписков, характеризующих то или иное свойство символа PERSON. Однако Лисп позволяет символам непосредственно иметь свойства. Свойство символа представляется в виде двух элементов: имени свойства и значения свойства. Свойства символа записываются в хранимый вместе с символом список свойств.
Выяснить значение свойства символа можно с помощью функции GET, аргументами которой являются имя символа и имя свойства. Если
предположить, что с символом PERSON связан указанный выше список свойств, то мы получим следующие результаты:
(get ’person ’name) IVAN (get ’person ’sport) FOOTBALL (get ’person ’address) NIL
Если имя свойства не найдено в списке свойств, то возвращается значение NIL. Внесение нового свойства и его значения в список свойств или изменение значения существующего свойства в языке Коммон Лисп выполняются с помощью функций GET и формы SETF:
(setf (get ’person ’name) ’aleksey) ALEKSEY
(setf (get ’person ’team) ’spartak) SPARTAK
Язык Лисп |
249 |
|
|
Удаление свойства и его значения из списка свойств выполняется с помощью функции REMPROP. Аргументы функции – имя символа и имя удаляемого свойства. В качестве результата функция REMPROP возвращает значение Т или NIL. NIL возвращается в случае, если у символа нет указанного свойства:
(remprop ’person ’team) Т
(remprop ’person ’address) NIL
Просмотреть список свойств, связанных с символом можно с помо-
щью функции SYMBOL-PLIST:
(symbol-plist ’person) (SPORT FOOTBALL AGE 25 NAME ALEKSEY)
Отметим, что свойства символов глобальны. Изменение значения символа не влияет на список свойств символа.
5.15. Типы данных
Используемые в программе данные характеризуется типом значений. Тип фиксирует, во-первых, множество значений, которые могут принимать объекты, принадлежащие данному типу, и, во-вторых, совокупность допустимых операций.
Ранее уже рассматривались некоторые типы данных языка Лисп: числа, атомы, списки. Классификация основных типов данных языка Лисп представлена на рисунке 5.10.
Типы данных, расположенные ниже по дереву классификации, автоматически входят в вышестоящий тип данных. Поэтому встроенные функции, определенные для расположенного выше по иерархии типа данных, можно применять к типам данных, являющихся его потомками.
ВЛиспе используется как явный, так и неявный способ указания типа значения. Например, символы могут вводиться без предварительного описания их типа. Их тип автоматически определяется на основании их позиции в форме, в которой они применяются. Символу можно присвоить значение любого типа.
ВКоммон Лиспе можно явно определить тип символа. Для этого применяется специальная форма DECLARE. Например,
(declare (type fixnum x y))
Здесь символы X, Y определяются как целочисленные значения, лежащие в диапазоне от минус 215 до плюс 215 .