

Точно Не проект 2 / Не books / Источник_1
.pdf190 |
Глава 4 |
|
|
ем и, следовательно, им не свойственна полумонотонность. Однако полунормальные умолчания позволяют отображать в базах знаний наследование свойств с исключениями, что характерно для сетевого и фреймового представлений знаний.
Иной подход предложили Д. Мак-Дермотт и Дж. Дойл. Они создали формальную систему немонотонного вывода, расширив логику исчисления предикатов. Для этого они переопределили понятие формула, включив в него выражение вида Мр, где М – модальный оператор “выполнимо”, р – формула языка исчисления предикатов. Добавили к системе аксиом исчисления предикатов схемы модальных аксиом и, кроме этого, расширили множество правил вывода специфическим правилом немонотонного вывода, т.е. правилом вывода всего лишь выполнимых утверждений. Выбирая различные подмножества из списка схем модальных аксиом, можно получать различные немонотонные логики. Эти логики позволяют получать различные множества заключений (неподвижных точек) путем изменения порядка вывода. Например, пусть дано множество формул [27,37]
S {MA B,MB A},
где А и В – пропозициональные буквы. Тогда возможны два решения (две
неподвижных точки). Одна неподвижная точка содержит А, но не включа-
ет В. Другая содержит В, но не включает А. Действительно, если первая
точка не содержит В, то она содержит МВ. Тогда из правила modus ponens
MB(МВ А) следует А. Рассуждая аналогично, получаем для второй точ-
ки В. Таким образом, решение в данном случае определяется неоднозначно.
Ценность немонотонных логик Мак-Дермотта и Дойла заключается в распространении модальной логики на формализацию модифицируемых утверждений. Однако при этом остаются серьезные проблемы, связанные с обоснованием выбора системы модальных аксиом [27].
Одной из важных задач, возникающих в системах немонотонного вывода, является управление выводом в условиях постоянного изменения степени достоверности заключений. Например, если на основе утверждения R получено заключение S, а в дальнейшем установлено, что R более не выполнимо, то необходимо не только исключить из базы знаний R , но также и S , если не имеется дополнительных утверждений в поддержку S. Для поддержания непротиворечивости базы знаний применяются специальные механизмы, реализуемые системами поддержания значений истин-
ности (англ. Truth Maintenance System – TMS).
Основные модели вывода |
191 |
|
|
Системы поддержания значений истинности (СПЗИ) применяются для обеспечения логической целостности выводов, формируемых на основе неполных знаний. Один из простых способов решений этой задачи заключается в запоминании протокола вывода. В протоколе вывода с каждым заключением связано соответствующее обоснование. Обоснование включает в себя все факты, правила и предположения, сделанные при выводе заключения. Если то или иное обоснование предположения становится невыполнимым, то, используя процедуру возврата к точкам, в которых принимались альтернативные решения, можно заново оценить истинность тех или иных заключений. В простейшем случае процедура осуществляет слепой хронологический поиск точек возврата. Однако, если пространство поиска большое, то хронологический поиск становится неэффективным. Для повышения эффективности применяют поиск, управляемый причиной противоречия. В этом случае обеспечивается немедленный возврат к предложению, являющемуся источником противоречия. Перемещаясь в прямом направлении от невыполнимого предположения к последующим заключениям, сделанным на его основе, удаляют эти заключения. При этом имеется возможность для каждого заключения, подлежащего удалению, выполнить проверку его выполнимости в новом окружении. Если имеются предположения в поддержку того или иного заключения, то оно не удаляется из базы знаний.
Известны два метода построения систем поиска, управляемого причиной противоречия, которые соответственно реализуются в системах типа JTMS (justification based TMS – система поддержания значений истинности, использующая обоснования) и ATMS (assumption based TMS – система поддержания значений истинности, использующая предположения). Система JTMS была предложена Дж. Дойлом. Дойл был первым исследователем, которому удалось отделить СПЗИ от механизма вывода. При этом СПЗИ взаимодействует с механизмом вывода: получает вновь сформированные следствия и их обоснования и возвращает сведения об утверждениях, которые достоверны на данном шаге работы механизма вывода.
Все утверждения в JTMS делятся на достоверные и недостоверные. Достоверные утверждения отмечаются меткой IN, а недостоверные – меткой OUT. При этом утверждения представляются в виде сети обоснования достоверности. Такая сеть содержит узлы двух типов. Узлы первого типа соответствуют утверждениям, а узлы второго типа – логической связке “И”. Связка “И” позволяет отобразить в сети взаимосвязь предпосылки и предположения правила умолчания (4.18). Анализируя сеть, можно выяснить достоверность того или иного утверждения и установить все предпосылки и предположения, которые подтверждают (поддерживают) его дос-
192 |
Глава 4 |
|
|
товерность. Если при добавлении новых знаний возникает противоречие, то происходит пересмотр меток утверждений и модификация сети.
Всистеме ATMS не применяют бинарные метки IN (достоверно) и OUT (недостоверно). Здесь метка достоверности утверждения представляется в виде множества предположений (предпосылок), при которых данное утверждение верно. Это делает системы типа ATMS более гибкими по сравнению с системами типа JTMS [77].
Взаключение отметим, что процесс доказательства в рамках неклассических логик значительно сложнее поддается автоматизации. Главным образом это связано с комбинаторным взрывом. Основной подход к решению этой проблемы состоит в сокращении пространства поиска. Так, во многих модальных логиках ограничиваются анализом “высказывательных фрагментов”, которые формируются с помощью модальных операторов.
Другой подход к автоматизации доказательства в неклассических логиках основан на сведении их к классическим логикам. Это выполняется путем формализации семантики неклассических логик терминами традиционной логики. Например, семантика модальных логик выражается посредством системы “возможных миров”. Для их формализации каждый предикат классической логики снабжается дополнительным аргументом, который специфицирует “возможный мир”. Дальнейшая квантификация таких аргументов с помощью кванторов общности и существования позволяет представить соответствующие модальные операторы. Связи между “возможными мирами” выражаются посредством отношений между ними
иучитываются в алгоритмах унификации. Это позволяет автоматизировать процесс доказательства с помощью процессора резолюций.
4.3. Индуктивный вывод
Кроме дедуктивных рассуждений, рассмотренных в § 4.1, в системах искусственного интеллекта широко используют индуктивные схемы рассуждений. Такие схемы рассуждений позволяют порождать обобщения имеющихся частных утверждений. Способность к обобщению является важной функцией естественного интеллекта. В результате обобщения формируются новые знания. Поэтому индуктивные схемы рассуждений находят применение в подсистемах автоматического приобретения знаний. При этом процесс получения новых знаний рассматривается как обучение ИС. В ходе обучения, благодаря обобщению совокупности имеющихся фактов, формируются понятия и выводятся (восстанавливаются) общие правила, обеспечивающие отнесение объектов, событий, ситуаций к соответствующим классам. Рассмотрим основные понятия индуктивного вывода и процедуры индуктивного формирования понятий по примерам.
Основные модели вывода |
193 |
|
|
4.3.1. Основные понятия индуктивного обобщения
Индукцией называют умозаключение, которое представляет знание о классе предметов, полученное в результате исследования отдельных представителей этого класса [13]. Если дедуктивный вывод строится по принципу движения мысли от общего к частному, то индуктивный вывод определяется как логический переход от частного к общему, т.е. как обобщение.
Обобщение здесь понимается как процесс получения знаний, которые объясняют имеющиеся факты. Целью обобщения является формирование понятий.
Понятие – обобщенная информация о множестве объектов (ситуаций, событий), представленных наборами значений признаков, которая:
а) отражает характерные для этого множества логические отношения между отдельными значениями признаков;
б) является достаточной для различения с помощью некоторого правила распознавания (классификации) объектов, принадлежащих множеству, от объектов, не принадлежащих ему [14].
Таким образом, понятие включает лишь существенные признаки объектов, ситуаций, событий, объединяющих их в один класс, и не включает те признаки, которые индивидуализируют их.
Задачу индуктивного формирования понятий можно определить сле-
дующим образом. Дано множество фактов (наблюдений, данных) F, представляющих специфические знания о некоторых объектах (ситуациях, событиях и т.п.); множество ограничений, которым должно удовлетворять искомое понятие. Требуется сформировать понятие Н (описание, гипотезу), из которого выводимы все факты, т.е. H F , где отношение понимается шире, чем отношение логического следования в исчислении предикатов.
Пусть Di – множество значений i – го признака, i = 1, 2, …, n ; n – число признаков. Признаковому описанию понятий соответствуют точки n -мерного пространства признаков D = {D1 x D2 x … x Dn}. Если каждому из значений признаков поставить в соответствие переменную, принимающую значение 1 или 0, в зависимости от того, наблюдается или не наблюдается данное значение признака, то можно описывать понятия выражениями булевой алгебры. Конъюнктивным называется понятие, описываемое конъюнкцией значений признаков. Запись понятия в виде логического выражения представляет собой правило классификации. Если логическое выражение, представляющее понятие будет иметь значение 1, то наблюдаемый объект (ситуация, событие) обобщается данным понятием. Поэто-
194 |
Глава 4 |
|
|
му задачу индуктивного формирования понятий на основе анализа конкретных фактов часто рассматривают как задачу восстановления правил.
Наблюдаемые факты называют положительными по отношению к некоторому понятию, если они описываются данным понятием, иначе их называют отрицательными фактами данного понятия.
Задачу индуктивного формирования понятий можно рассматривать как задачу обучения. Выделяют обучение с учителем (обучение по примерам) и обучение без учителя (обучение на основе наблюдения).
Впервом случае совокупность фактов F имеет вид обучающей выборки, которая представляет собой множество примеров объектов (ситуаций, событий) с заданной принадлежностью к тому или иному классу (понятию) K1, K2, …, Km. В основе обучения лежит упорядоченный отбор конъюнкций значений признаков, характеризующих группы положительных примеров понятия и не определяющих ни одного из отрицательных примеров (контрпримеров). Требуется построить решающее правило, позволяющее определить принадлежность произвольного объекта, ситуации, события, заданному классу Ki.
Вслучае обучения без учителя априорное разделение фактов по классам отсутствует. Требуется по тем или иным критериям выделить совокупность классов {Ki} и построить для них решающие правила. Такая задача сложнее задачи обучения с учителем. Методы формирования понятий по фактам без их априорного разбиения на классы рассматриваются в кластерном анализе. Один из алгоритмов группирования объектов, характеризуемых числовыми признаками, в класс (кластер) приведен в § 8.2. Здесь же ограничимся рассмотрением обучения по примерам.
Центральная роль в процессе обучения отводится индуктивному обобщению. При этом различают полную и неполную индукцию [14]. Полной индукцией называют общее заключение, которое выводится на основании изучения всех имеющихся фактов. Это возможно лишь в тех случаях, когда количество возможных фактов конечно и невелико. Если заключения выводятся на основании изучения лишь части фактов, то индукция называется неполной. Заключения, выполненные с помощью неполной индукции, являются правдоподобными, так как из истинности частного не обязательно следует истинность общего.
Воснове индуктивных выводов лежит правило индуктивного обоб-
щения
F,H F |
, |
(4.19) |
|
||
H |
|
|
где F – множество известных фактов; Н – понятие (гипотеза). Смысл этого правила заключается в следующем. Пусть имеется множество фактов F.
Основные модели вывода |
195 |
|
|
Если ввести некоторую гипотезу Н и показать, что из Н выводим любой факт F, то гипотеза Н верна. Особенностью правила индуктивного обобщения (4.19) является то, что множество объектов, описываемых гипотезой Н, шире, чем множество, соответствующее фактам F. Это может приводить к тому, что из гипотезы Н будут выводиться и другие факты. Следовательно, есть риск совершить ошибку. Поэтому при выборе гипотезы Н необходимо стремиться к минимальному обобщению.
Взаключение отметим, что задача индуктивного формирования понятий близка к задаче обучению распознаванию образов. И в том и в другом случае формируется модель класса объектов, ситуаций, событий. Однако в случае формирования понятий, полученная модель должна обеспечивать не только распознавание, но и возможность генерации описаний конкретных объектов, ситуаций и т.п. [13].
Это связано с пониманием процесса формирования понятий как процесса выделения закономерностей, приобретения новых знаний, где должны отражаться признаковые, структурные и логические характеристики объектов, ситуаций, событий реального мира. Учитывая указанную специфику, ниже рассмотрим процедуры индуктивного обобщения, применяемые в подсистемах приобретения знаний. Процедуры обучения, ориентированные на применение в задачах распознавания образов, рассматриваются в главе 8.
4.3.2.Алгоритм Уинстона
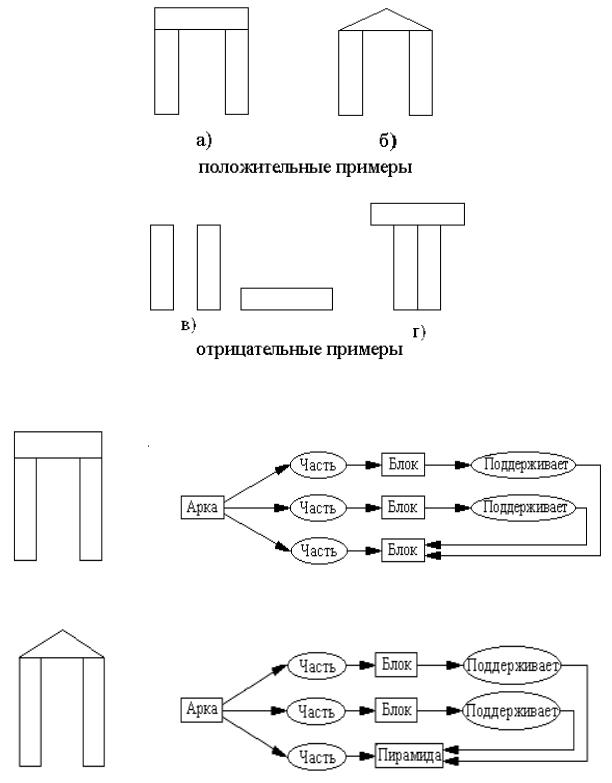
В1975 году П. Уинстоном была разработана программа, формирующая описания структурных понятий. Программе последовательно предъявляются описания положительных и отрицательных примеров (контрпримеров). В качестве контрпримеров используются примеры, в которые специально внесены ошибки. На рисунке 4.20 изображены положительные и отрицательные примеры для понятия “арка”.
Программа строит описание понятия в виде семантической сети, структура которой уточняется по мере предъявления примеров. При этом “соседние” примеры должны минимально отличаться друг от друга. Обучение программы выполняется на основе операций обобщения и специализации.
Вслучае предъявления программе описания арки, состоящей из трех прямоугольных блоков, формируется семантическая сеть, представленная на рисунке 4.21,a . Следующий пример арки, в котором верхний блок заменен пирамидой, описывается семантической сетью, изображенной на рисунке 4.21,б.
196 |
Глава 4 |
|
|
Рисунок 4.20 – Положительные и отрицательные примеры понятия “арка”
а)
б)
Рисунок 4.21 –Описание арки семантической сетью
Основные модели вывода |
197 |
|
|
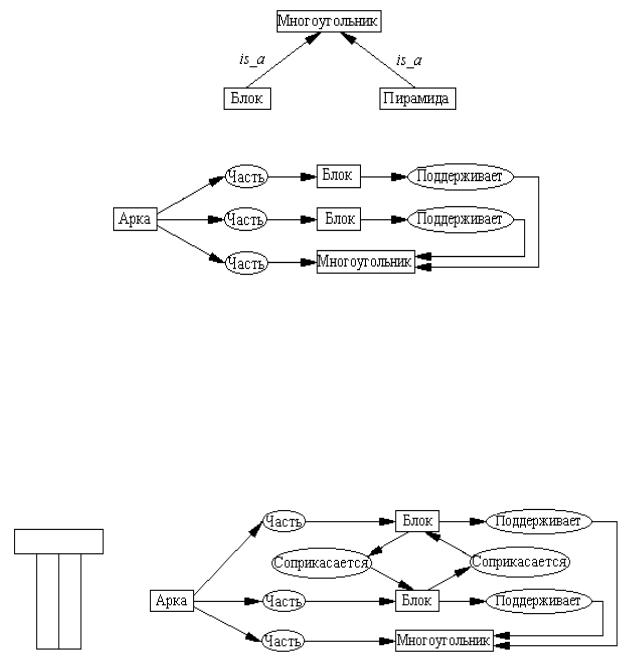
Сопоставляя семантические сети, изображенные на рисунках 4.21,а и 4.21,б программа обнаруживает отличия между арками. Отличие заключается в том, что верхним элементом первой арки является блок, а второй – пирамида. Используя семантическую сеть, отражающую иерархию, указанных “строительных элементов” (рисунок 4.22), программа обобщает описание понятия “арка”. При этом вместо понятий блок и пирамида используется их ближайший супертип – многоугольник, т.е. выполняется минимальное обобщение. В результате формируется обобщенное описание арки, представляемое семантической сетью, изображенной на рисунке 4.23
Рисунок 4.22 – Иерархия “строительных блоков”
Рисунок 4.23 – Обобщенное описание арки
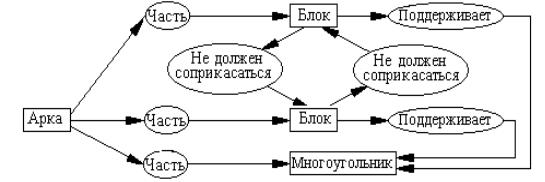
Данная семантическая сеть обобщает положительные примеры, изображенные на рисунке 4.21,а и 4.21,б. В случае предъявления отрицательных примеров выполняется ограничение общности (специализация) формируемого понятия. Если предъявляется контрпример, в котором поддерживающие блоки соприкасаются, то формируется семантическая сеть контрпримера, изображенная на рисунке 4.24. Сеть контрпримера отличается наличием отношения “соприкасается”.
Рисунок 4.24 – Семантическая сеть контрпримера
198 |
Глава 4 |
|
|
Поэтому программа выполняет специализацию сети, изображенной на рисунке 4.24 , добавляя отношение “не должен соприкасаться” (рисунок 4.25). Целью специализации является исключение из формируемого описания понятия контрпримера. Отметим, что контрпримеры должны быть максимально близки к формируемому описанию целевого понятия. Рассматриваемый контрпример понятия “арка” отличается от положительного примера только одним дополнительным отношением. Это упрощает выполнение операции специализации.
Рисунок 4.25 – Специализация описания
Таким образом, в ходе обучения выполняются две основные операции: обобщение и специализация. Обобщение заключается в замене узлов сети более общими понятиями. Специализация предполагает добавление в сеть новых связей. Если представить понятия, формируемые на основе операций специализации и обобщения, в виде некоторых состояний процесса обучения, то можно заметить, что программа П.Уинстона выполняет поиск в пространстве понятий. При этом поиск управляется обучающими примерами (данными) и соответствует алгоритму подъема на гору (см. § 2.2.2.1) [77]. Так как в этом случае не предусматривается возврат к предыдущим состояниям, то алгоритм П. Уинстона весьма чувствителен к порядку, в котором предъявляются обучающие примеры. Примеры должны предъявляться в “хорошем педагогическом порядке”, который исключает попадание в тупиковые вершины на графе поиска. Кроме этого, соседние примеры и контрпримеры должны минимально отличаться друг от друга, что облегчает выполнение операций обобщения и специализации, а также упрощает процедуру сопоставления подграфов семантической сети.
Программа П. Уинстона была одной из первых программ, реализующей идеи индуктивного обучения. Она обозначила важные моменты, свойственные многим программам машинного обучения:
-применение операций обобщения и специализация для формирования пространства понятий;
Основные модели вывода |
199 |
|
|
-применение методов поиска, управляемых данными (примерами);
-зависимость результатов обучения от качества обучающих данных.
4.3.3. Алгоритм Митчелла
Алгоритм Т.М.Митчелла, называемый алгоритмом исключения по- нятий–кандидатов, аналогично алгоритму П.Уинстона предназначен для формирования одного понятия по предъявляемым примерам. Алгоритм основывается на двунаправленном поиске в пространстве версий, которое представляется множеством всех понятий, охватывающих положительные примеры и не выполняющихся на отрицательных примерах. В процессе выполнения алгоритма поисковое пространство сокращается как в направлении от частных понятий к общим, так и в обратном направлении. Если предъявляется положительный пример, то из поисковой области исключаются все понятия-кандидаты, не охватывающие его. Если предъявляется отрицательный пример, то, наоборот, исключаются все охватывающие его понятия-кандидаты. Когда в поисковой области остается одно понятие, алгоритм прекращает работу.
Термин “охватывающие понятие” связан с операцией обобщения. При этом обобщение может выполняться следующими способами:
а) заменой константы на переменную, например, высказывание, заданное атомарной формулой
цвет(мяч, синий),
обобщается предикатом цвет(Х, синий); б) исключением конъюнктивных членов из формул, например, формула
цвет(Х,синий) вес(Х,большой) форма(Х,прямоугольная)
является частным случаем формулы
цвет(Х,синий) форма(Х,прямоугольная);
в) добавлением дизъюнктивных элементов, например, утверждение
цвет(Х, синий) форма(Х, прямоугольная)
обобщается формулой
цвет(Х,синий) (форма(Х, прямоугольная) форма(Х,треугольная));