


Типы рекомендательных систем |
279 |
ВВЕДЕНИЕ В РЕКОМЕНДАТЕЛЬНЫЕ СИСТЕМЫ
Рекомендательные системы — это методы, первоначально разработанные ис следователями для прогнозирования товаров, которые, скорее всего, заинтере суют клиента. Способность таких систем давать персонализированные реко мендации по товарам делает их, пожалуй, наиболее важной технологией в мире онлайн-покупок.
В приложениях электронной коммерции используются сложные алгоритмы для повышения качества обслуживания клиентов; эти алгоритмы позволяют по ставщикам товаров и услуг настраивать свои предложения в соответствии
спредпочтениями покупателей.
В2009 году Netflix предложил 1 миллион долларов за алгоритм, спо собный улучшить существующий механизм рекомендаций (Cinematch) более чем на 10 %. Приз получила команда BellKor's Pragmatic Chaos.
ТИПЫ РЕКОМЕНДАТЕЛЬНЫХ СИСТЕМ
Существуют три типа рекомендательных систем:
zz на основе контента;
zz на основе коллаборативной, или совместной, фильтрации (collaborative filtering);
zz гибридные.
Рекомендательные системы на основе контента
Основная идея рекомендательной системы на основе контента (content-based recommendation engine) состоит в том, чтобы предлагать позиции (товары), аналогичные тем, к которым пользователь ранее проявлял интерес. Эффектив ность такого механизма зависит от возможности количественно оценить сходство одного товара с другими.
Давайте посмотрим на следующую диаграмму. Если Пользователь 1 прочитал Документ 1, то мы можем рекомендовать пользователю Документ 2, который аналогичен Документу 1 (рис. 10.1).
Но как определить, какие позиции похожи между собой? Рассмотрим несколь ко методов поиска сходства.

280 |
|
Глава 10. Рекомендательные системы |
|
|
|
|
|
|
Пользователь 1 |
|
|
|
|
||
|
|
|
|
|
|
Документ 1 |
|
|
|
|
|
|
|
Документ 2 |
|
Рис. 10.1
Поиск сходства между неструктурированными документами
Одним из способов определения сходства между документами является пред варительная обработка входных неструктурированных документов. В резуль тате мы получаем структуру данных, которая называется терм-документной матрицей (TDM). Она показана на следующей диаграмме (рис. 10.2).
algorithm
Документы |
Представление в векторном |
4 4 |
|
||
пространстве |
|
|
|
|
Терм-документная матрица
Рис. 10.2
Типы рекомендательных систем |
281 |
TDM содержит весь глоссарий слов в виде строк и все документы в виде столбцов. С ее помощью можно выявить похожие документы на основе выбранного критерия. Например, Google News предлагает пользователю но вости, базируясь на их сходстве с новостями, к которым он уже проявлял интерес.
Создав TDM, мы получаем два способа количественной оценки сходства между документами:
zz Подсчет частоты употребления. Данный подход подразумевает, что важность слова прямо пропорциональна его частоте. Это самый простой способ рас чета важности.
zz Использование TF-IDF. Этот показатель представляет важность каждого слова в контексте задачи и является произведением двух сомножителей:
yy Частота слова (TF, term frequency). Это количество раз, когда слово или термин появляется в документе. TF напрямую коррелирует с важностью слова.
yy Обратная частота документов (IDF, inverse document frequency). Об ратите внимание: частота документов (DF, document frequency) — это количество документов, содержащих искомое слово. В противоположность DF, IDF отражает меру уникальности слова и соотносит ее с важностью этого слова.
yy TF и IDF оценивают количественно важность слова в контексте задачи, а их комбинация, TF-IDF, служит хорошим показателем важности каж дого слова и является более сложной альтернативой простому подсчету частоты.
Матрица совместной встречаемости
Использование матрицы совместной встречаемости (co-occurrence matrix) основано на предположении, что если в большинстве случаев два определенных товара покупаются одновременно, то они, скорее всего, похожи (либо, по край ней мере, принадлежат к одной и той же категории, товары из которой обычно покупаются вместе).
Например, гель для бритья и бритва почти всегда используются одновременно. Поэтому, если человек покупает бритву, разумно предположить, что он также купит и гель для бритья.
Проанализируем покупательские привычки четырех потребителей (табл. 10.1).
282 |
|
|
Глава 10. Рекомендательные системы |
||
Таблица 10.1 |
|
|
|
|
|
|
|
|
|
|
|
|
Бритва |
Яблоко |
Крем для бри- |
Велосипед |
Хумус |
|
|
|
тья |
|
|
|
|
|
|
|
|
Майк |
1 |
1 |
1 |
0 |
1 |
|
|
|
|
|
|
Тейлор |
1 |
0 |
1 |
1 |
1 |
|
|
|
|
|
|
Елена |
0 |
0 |
0 |
1 |
0 |
|
|
|
|
|
|
Амина |
1 |
0 |
1 |
0 |
0 |
|
|
|
|
|
|
Создадим матрицу совместной встречаемости на основе этих данных (табл. 10.2).
Таблица 10.2
|
Бритва |
Яблоко |
Крем для бри- |
Велосипед |
Хумус |
|
|
|
тья |
|
|
|
|
|
|
|
|
Бритва |
- |
1 |
3 |
1 |
1 |
|
|
|
|
|
|
Яблоко |
1 |
- |
1 |
0 |
1 |
|
|
|
|
|
|
Крем для |
3 |
1 |
- |
1 |
2 |
бритья |
|
|
|
|
|
|
|
|
|
|
|
Велосипед |
1 |
0 |
1 |
- |
1 |
|
|
|
|
|
|
Хумус |
1 |
1 |
2 |
1 |
- |
|
|
|
|
|
|
Матрица совместной встречаемости суммирует вероятность покупки двух то варов вместе. Давайте посмотрим, как ее использовать.
Рекомендательные системы на основе коллаборативной фильтрации
Алгоритм коллаборативной фильтрации (collaborative filtering) основан на анализе покупательского поведения. Базовое предположение состоит в том, что если два пользователя проявляют интерес в основном к одним и тем же товарам, мы можем классифицировать этих покупателей как похожих. Другими словами, можно предположить следующее:
zz Если совпадение в истории покупок двух пользователей превышает порого вое значение, их можно классифицировать как похожих.
Типы рекомендательных систем |
283 |
zz Товары, которые не пересекаются в истории покупок похожих пользователей, становятся предметом будущих рекомендаций на основе коллаборативной фильтрации.
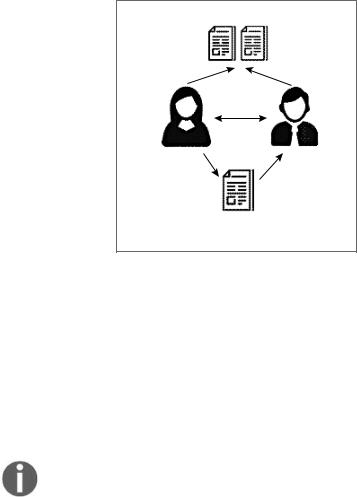
Рассмотрим конкретный пример. У нас есть два пользователя, Майк и Елена (рис. 10.3).
1 |
2 |
|
• |
3
,
!
Рис. 10.3
Обратите внимание:
zz Майк и Елена проявили интерес к одним и тем же позициям, Документу 1
и Документу 2.
zz Основываясь на схожих паттернах покупательского поведения, мы класси фицируем пользователей как похожих.
zz Если Елена в данный момент читает Документ 3, то мы можем предложить
Документ 3 и Майку.
Обратите внимание, что стратегия предложения позиций пользовате лям на основе их истории покупок будет срабатывать не всегда.
Предположим, что Елена и Майк проявили интерес к Документу 1, посвящен ному фотографии (потому что они оба любят фотографировать). Кроме того, Елена и Майк проявили интерес к Документу 2, который посвящен облачным вычислениям, опять же, потому что им обоим интересна эта тема. Основываясь