

Рекуррентные нейросети в NLP |
271 |
собаках и т. д., а модель сама поймет, что мы имеем в виду животных. При этом модель‚ никогда не обучаясь на овцах‚ все же будет правильно их клас сифицировать. Используя эмбеддинг, мы можем рассчитывать на правильный ответ.
Теперь обсудим использование рекуррентных нейронных сетей для обработки естественного языка.
РЕКУРРЕНТНЫЕ НЕЙРОСЕТИ В NLP
Рекуррентная нейросеть (Recurrent Neural Networks, RNN) — это традиционная сеть прямого распространения с обратной связью. Чтобы понять RNN, нужно представить ее как нейронную сеть с состояниями (states). Рекуррентные ней росети используются с любым типом данных для генерации и прогнозирования различных последовательностей. Обучение модели RNN заключается в форму лировании последовательностей данных. RNN можно применять и для тексто вых данных, поскольку предложения — это просто последовательности слов. Используя рекуррентные сети для NLP, можно добиться следующего:
zz предсказать следующее слово при вводе текста;
zz создать новый текст, придерживаясь стиля, уже использованного в тексте ранее (рис. 9.4).
Рис. 9.4
Помните комбинацию слов, которая привела к правильному предсказанию? Процесс обучения RNN основан на тексте, который содержится в корпусе. Ней росеть обучается, уменьшая ошибку между предсказанным словом и фактиче ским следующим словом.
272 |
Глава 9. Алгоритмы обработки естественного языка |
ИСПОЛЬЗОВАНИЕ NLP ДЛЯ АНАЛИЗА ЭМОЦИОНАЛЬНОЙ ОКРАСКИ ТЕКСТА
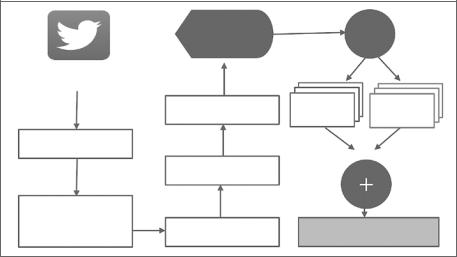
В этом разделе анализ эмоциональной окраски (или тональности) представлен на примере классификации плотного потока входящих твитов. Задача состоит в том, чтобы извлечь эмоциональную окраску твитов на определенную тему. Классификация эмоций количественно определяет полярность в режиме реаль ного времени. После этого показатели суммируются в попытке отразить общие настроения по выбранной теме. Необходимо преодолеть трудности, связанные с содержанием и поведением потоковых данных Twitter, и при этом осуществить эффективный анализ в реальном времени. Для этого мы используем обученный классификатор NLP. Он подключается к потоку Twitter для определения поляр ности каждого твита (положительной, отрицательной или нейтральной). Далее происходят агрегирование и определение общей полярности всех твитов на выбранную тему. Теперь пошагово разберем этот процесс.
Сначала мы должны обучить классификатор. Для обучения классификатора нужен уже подготовленный набор исторических данных Twitter, обладающий той же структурой и трендами, что и данные реального времени. Поэтому мы используем набор данных с веб-сайта www.sentiment140.com. Он представляет собой размеченный вручную корпус текстов для анализа с огромным количе ством твитов (более 1,6 миллиона). Твиты в этом наборе данных помечены одной из трех полярностей: 0 — для отрицательных, 2 — для нейтральных и 4 — для положительных. В дополнение к тексту твита корпус предоставляет иден тификатор твита, дату, флаг и имя пользователя, который его написал. Рассмо трим операции, выполняемые с твитом в реальном времени, прежде чем он достигнет обученного классификатора:
1.Сначала твиты разбиваются на отдельные слова, называемые токенами (то кенизация).
2.В результате токенизации возникает мешок слов, который представляет со бой набор отдельных слов в тексте.
3.Твиты дополнительно фильтруются путем удаления цифр, знаков препина ния и стоп-слов. Напомним, что стоп-слова — это распространенные слова и служебные части речи, такие как артикли, формы глагола «to be» и т. д. Они не содержат дополнительной информации, поэтому удаляются.
4.Кроме того, неалфавитные символы, такие как #@ и цифры, удаляются с по мощью сопоставления с образцом, поскольку не имеют отношения к анали зу тональности. Регулярные выражения используются только для сопостав
Использование NLP для анализа эмоциональной окраски текста |
273 |
ления буквенных символов, остальные же игнорируются. Это помогает уменьшить шум в потоке сообщений Twitter.
5.Результаты предыдущей фазы переносятся на этап стемминга. На этом эта пе производные слова сводятся к своим корням — например, слово «рыба» имеет тот же корень, что и «рыбалка» и «рыбак». Для этого мы используем библиотеку NLTK, предоставляющую различные алгоритмы (например, стеммер Портера).
6.Как только данные обработаны, они преобразуются в структуру, называемую терм-документной матрицей (term document matrix TDM). TDM отобра жает термины и частоту их употребления в отфильтрованном корпусе.
7.Из TDM твит переходит к обученному классификатору (поскольку он обу чен, то может обрабатывать твит), который вычисляет важность эмоциональной полярности (sentimental polarity importance, SPI) каждого слова, пред ставляющей собой число от –5 до + 5. Положительный или отрицательный знак определяет тип эмоций, представленных этим конкретным словом, а величина отражает силу чувства. Это означает, что твит может быть клас сифицирован как положительный или отрицательный (рис. 9.5). Как только мы вычисляем полярность отдельных твитов, мы суммируем их общий SPI, чтобы агрегировать настроение источника. Например, общая полярность больше единицы указывает на то, что общее настроение твитов за наблюда емый нами период времени является положительным.
|
•• • • |
|
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
TDM |
•- |
€‚- |
|
• |
• |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
••ƒ „ |
|
Рис. 9.5

274 |
Глава 9. Алгоритмы обработки естественного языка |
Для получения необработанных твитов в реальном времени мы ис пользуем java-библиотеку Scala Twitter4J. Она предоставляет API для потоковой передачи из Twitter. API требует, чтобы пользователь зареги стрировал учетную запись разработчика в Twitter и ввел ряд параметров аутентификации. Этот интерфейс позволяет как получать случайные твиты, так и фильтровать их по выбранным ключевым словам. Для из влечения твитов мы использовали фильтры, определив ключевые слова.
Общая архитектура показана на рис. 9.5.
Анализ тональности текста применяется в разных сферах. К примеру, его мож но использовать для классификации отзывов клиентов. Правительство может применить анализ полярности социальных сетей, чтобы определить эффектив ность своей политики. С помощью анализа тональности можно оценить успех рекламной кампании.
В следующем разделе мы разберем практический пример применения анализа тональности текстов для определения настроений в отзывах на фильмы.
ПРАКТИЧЕСКИЙ ПРИМЕР — АНАЛИЗ ТОНАЛЬНОСТИ В ОТЗЫВАХ НА ФИЛЬМЫ
Проанализируем настроения в отзывах на фильмы с помощью NLP. Для этого используем открытые источники данных с рецензиями, доступные по адресу http://www.cs.cornell.edu/people/pabo/movie-review-data/:
1. Импортируем набор данных, содержащий отзывы:
import numpy as np import pandas as pd
2.Загрузим данные и выведем несколько первых строк, чтобы увидеть их структуру (рис. 9.6):
df=pd.read_csv("moviereviews.tsv",sep='\t') df.head()
Обратите внимание, что набор данных содержит 2000 отзывов на фильмы. Из них половина — отрицательные, а половина — положительные.
3.Подготовим набор данных для обучения модели. Отбросим все пропущенные значения, которые есть в данных:
df.dropna(inplace=True)

Практический пример — анализ тональности в отзывах на фильмы |
275 |
|
|
|
|
|
|
|
Рис. 9.6
4.Теперь нам нужно убрать пробелы. Пробелы не являются null-значениями, но их необходимо удалить. Для этого выполним итерацию по каждой строке во входном DataFrame. Используем .itertuples() для доступа к каждому полю:
blanks=[]
for i,lb,rv in df.itertuples(): if rv.isspace():
blanks.append(i)
df.drop(blanks,inplace=True)
Обратите внимание, что мы использовали i, lb и rv для столбцов индекса, метки и обзора.
Разделим данные на контрольный и обучающий наборы:
1.Первый шаг — указать признаки и метку, а затем разделить данные на обу чающие и контрольные:
from sklearn.model_selection import train_test_split
X = df['review'] y = df['label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Теперь у нас есть наборы данных для обучения и контроля. 2. Импортируем необходимые библиотеки и построим модель:
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB
276 Глава 9. Алгоритмы обработки естественного языка
# Наивный байесовский классификатор:
text_clf_nb = Pipeline([('tfidf', TfidfVectorizer()), ('clf', MultinomialNB()),
])
Обратите внимание, что мы используем tfidf для количественной оценки важности точки данных в коллекции.
Далее обучим модель с использованием наивного байесовского классификато ра, а затем протестируем обученную модель.
Выполним следующие действия:
1.Обучим модель, используя подготовленные наборы данных для контроля и обучения:
text_clf_nb.fit(X_train, y_train)
2. Запустим прогнозы и проанализируем результаты:
# Предсказанный набор
predictions = text_clf_nb.predict(X_test)
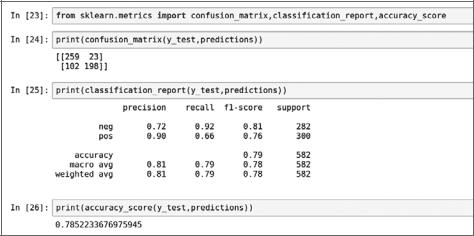
Теперь выведем матрицу ошибок, чтобы оценить производительность модели. Рассмотрим precision (точность), recall (полноту), f1-score (f1-меру) и accuracy (долю правильных ответов) (рис. 9.7).
Рис. 9.7