

Инструменты и фреймворки |
251 |
2.Настройка процесса обучения.
На этом этапе мы задаем три аргумента: yy оптимизатор;
yy функция потерь;
yy метрики, которые будут количественно определять качество модели (рис. 8.15).
Рис. 8.15
Для определения оптимизатора, функции потерь и метрик используется функция model.compile.
3.Обучение модели.
Как только архитектура определена, пришло время обучить модель (рис. 8.16).
Рис. 8.16
Обратите внимание, что такие параметры, как batch_size (размер пакета) и epochs (количество эпох), являются настраиваемыми, что делает их гипер параметрами.
Выбор последовательной или функциональной модели
Последовательная модель создает ИНС в виде простого стека слоев. Такую модель несложно понять и реализовать, но ее упрощенная архитектура накла дывает серьезные ограничения. Каждый слой подключен ровно к одному вход ному и выходному тензору. Если же модель имеет несколько входов или вы ходов на любом из слоев (входном, выходном или скрытом), то она является функциональной.
Знакомство с TensorFlow
TensorFlow — одна из самых популярных библиотек для работы с нейронными сетями. В предыдущем разделе мы узнали о ее применении в качестве сервер

252 |
Глава 8. Алгоритмы нейронных сетей |
ного движка Keras. На самом деле эта высокопроизводительная библиотека с открытым исходным кодом может использоваться для любых вычислительных задач. Если посмотреть на стек, становится ясно, что мы можем написать код TensorFlow на высокоуровневом языке (таком, как Python или C++), который затем интерпретируется распределенным механизмом выполнения. Это делает TensorFlow весьма полезной и популярной среди разработчиков.
Принцип работы TensorFlow заключается в том, что для представления вычис лений создается ориентированный граф (directed graph). Ребра этого графа представляют собой массивы данных (входные и выходные данные), соединя ющие вершины (математические операции).
Основные понятия TensorFlow
Давайте кратко рассмотрим понятия TensorFlow: скаляры, векторы и матрицы. Известно, что простое число, такое как три или пять, в традиционной матема тике называется скаляром. Вектор — это объект, имеющий величину и направ ление. Применительно к TensorFlow вектор используется для обозначения одно мерных массивов. Расширив эту концепцию, мы получим двумерный массив‚ матрицу. Для трехмерного массива применяется термин 3D-тензор. Термин ранг обозначает размерность структуры данных. Таким образом, скаляр — это структура данных ранга 0, вектор — структура данных ранга 1, а матрица — структура данных ранга 2. Эти многомерные структуры известны как тензоры и показаны на следующей схеме (рис. 8.17).
Ранг 0 |
Ранг 1 |
Ранг 2 |
3 |
4 |
Тензор |
Тензор |
Тензор |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 8.17 |
|
|
Перейдем к другому параметру, размеру, называемому также формой (shape). Размер — это кортеж целых чисел, определяющих длину массива в каждом из мерении. На следующей диаграмме объясняется концепция размера (рис. 8.18).

Инструменты и фреймворки |
253 |
1, [3]
2, [2, 3]
3,
[2, 1, 3]
Рис. 8.18
Используя shape и rank, мы задаем параметры тензоров.
Понимание тензорной математики
Рассмотрим различные математические вычисления с использованием тензоров:
zz Определим два скаляра, чтобы потом сложить и умножить их с помощью TensorFlow (рис. 8.19).
Рис. 8.19
zz Осуществим сложение и умножение‚ а затем выведем результаты (рис. 8.20).
Рис. 8.20

254 |
Глава 8. Алгоритмы нейронных сетей |
zz Создадим новый скаляр, сложив два тензора (рис. 8.21).
Рис. 8.21
zz Выполним сложные тензорные функции (рис. 8.22).
Рис. 8.22
Типы нейронных сетей
Существует несколько способов построения нейронных сетей. Если каждый нейрон в каждом слое соединен с каждым нейроном в другом слое, то перед нами полносвязная нейронная сеть. Рассмотрим некоторые другие формы нейронных сетей.
Сверточные нейросети
Сверточные нейросети, СНС (или CNN — Convolutional Neural Networks), обыч но используются для анализа мультимедийных данных. Чтобы узнать больше о том, как СНС используется для анализа данных на основе изображений, нам необходимо иметь представление о следующих процессах:
zz свертка (convolution);
zzобъединение или подвыборка (pooling).
Рассмотрим их по очереди.
Свертка
Процесс свертки выделяет нужный шаблон в конкретном изображении путем обработки его с применением другого изображения меньшего размера, называ
Инструменты и фреймворки |
255 |
емого фильтром или ядром. Например, если мы хотим найти границы объектов на изображении, мы можем свернуть его с помощью определенного фильтра. Выделение границ применяется для обнаружения объектов, их классификации и других задач. Иными словами, процесс свертки заключается в поиске харак теристик и особенностей изображения.
Подход основан на поиске шаблонов, которые можно использовать повторно применительно к другим данным. Такие шаблоны называются фильтрами или ядрами.
Подвыборка (объединение)
Важной частью обработки мультимедийных данных для машинного обучения является понижающая дискретизация (downsampling). Она дает два преимуще ства:
zz Уменьшается размерность задачи‚ существенно сокращается время, необхо димое для обучения модели.
zzПосредством агрегирования ненужные детали в мультимедийных данных абстрагируются. В результате данные становятся более обобщенными и бо лее репрезентативными для аналогичных задач.
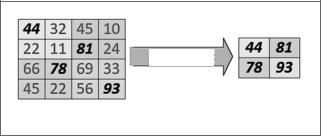
Понижающая дискретизация выполняется следующим образом (рис. 8.23).
|
|
Рис. 8.23
Мы заменили каждый блок из четырех пикселей на один пиксель, выбрав для него наибольшее значение из четырех. Это означает, что выборка сократилась в четыре раза. Поскольку мы взяли максимальное значение в каждом блоке, этот процесс называется объединением (подвыборкой) по максимальному значению. Мы могли бы взять среднее значение; в данном случае это было бы объединением (подвыборкой) средних значений.