

книги / Цифровая обработка сигналов
..pdfпервых, достигается бóльшая наглядность при визуальном восприятии, чем у исходного изображения. Во-вторых, ощутимо сокращается объем запоминающегоустройства дляхранения изображения.
Препарирование часто используется и в автоматических системах обработки визуальной информации, поскольку подготавливаемый при этом препарат может содержать всю информацию, необходимую для последующей (вторичной) обработки.
6.3. Применение цифровой обработки звуковых сигналов
Цифровая обработка звуковых сигналов [8] может применяться в различных областях науки и техники (рис. 6.1).
Рис. 6.1. Примеры применения ЦОС
Цифровое микширование
Микширование звука применяется в профессиональных и полупрофессиональных аудиоприложениях, например, для студийной звукозаписи, радиовещания, при усилении звука и в системах публичных выступлений. Микшер позволяет регулировать, смешивать и выводить на экран характеристики многоканальных аудиосигналов от различных источников для подстройки их под требования определенных приложений.
Цифровая система микширования состоит из средств аудиовыравнивания, аудиомикширования и обработки после микширования
(рис. 6.2).
101

Рис. 6.2. Упрощенная блок-схема цифровой системы микширования
Цифровой аудиоэквалайзер – это набор цифровых фильтров с регулируемыми характеристиками, т.е. с возможностью выполнять действия над различными частями полос входного спектра аудиосистемы для достижения желаемого звука (например, усиливать или обрезать определенные тона) подобно настройке высоких и низких частот. Затем выровненные звуковые сигналы смешиваются с помощью матрицы смешивания (позволяет смешивать любой произвольный звуковой вход с любым выходом). После смешивания обработка сигнала может продолжаться путем реверберации и выравнивания.
Система микширования обладает такими интерактивными средствами контроля для управления параметрами микшера: значениями операторов микшера (регуляторов уровня сигнала) и параметрами контроля эквалайзера (частота, добротность и коэффициент усиления фильтра) в реальном времени. Одна из сложных проблем цифрового микширования звука — это достижение пользовательского контроля над параметрами микшера при относительно высокой скорости обработки данных без заметных искажений. Каждый раз, когда пользователь передвигает рычаги управления, параметры микшера должны изменяться, чтобы соответствовать новым требованиям. Такая регулировка может привести к заметным искажениям, что недопустимо в профессиональных системах смешивания звука. Тщательное следование алгоритму смешивания является главным условием достижения профессионального уровня звучания.
102
Характерные особенности обычного микшера:
–n моновходов (n микрофонов или n линий);
–2 пары стереоканалов (левый и правый) сигнала;
–главная кодовая шина для централизованного контроля, например, выбора области памяти, усиления по мощности и обработке сигнала.
В цифровом микшере обычно используется современный процессор ЦОС, позволяющий реализовывать новейшие алгоритмы, необходимые при смешивании цифровых сигналов (например, выравнивание, стробирование шума, динамический контроль) и выполнении операций после смешивания.
Синтез и распознавание речи
В прошлом синтезированная речь воспринималась как звучание механического голоса. Однако прогресс в области полупроводниковых технологий и ЦОС сделали экономически возможным достижение такого качества речи, что ее нельзя отличить от человеческой.
Примером успешного коммерческого продукта с речевым выходом является, например, электронное пособие для обучения детей, в котором используется метод линейного кодирования с пред-
сказанием (Linear predictive coding – LPC), где настоящая человече-
ская речь, которую нужно воспроизвести, моделируется как отклик переменного во времени цифрового фильтра на периодический или случайный сигнал возбуждения (рис. 6.3). Периодическое возбуждение используется для генерации голосовых звуков (например, гласных) и представляет поток воздуха через вибрирующие голосовые связки. Случайное возбуждение используется для неголосовых звуков (таких, как С, Ш) и представляет шум, создаваемый при проталкивании воздуха через преграды в речевом канале. Человеческая речь содержит очень много лишней информации. Кодер оставляет только важную информацию, необходимую для сохранения таких характеристик речи, как интонация, акцент и диалект, позволяя держать целые минуты звука высокого качества в памяти среднего размера.
103

Рис. 6.3. Линейное кодирование с предсказанием речи
Впособии Speak and Spell используется микросхема синтезатора речи ТМ5 100, который объединяет все элементы модели [РС (цифровой фильтр и источники возбуждения), а также декодер и 8-битовьий цифроаналоговьий преобразователь (ЦАП). Микросхема синтезатора действует в тесной связи с 4-битовым микропроцессором и двумя 128-килобитовыми ПЗУ, которые вместе вмещают словарь из приблизительно 300 слов и фраз (рис. 6.4). Информация о речи хранится в ПЗУ в форме кадров (содержащих 25 мс речи), каждый кадр характеризуется набором из 10 или 12 параметров LРС. Параметры кадра сообщаются синтезатору каждые 25 мс и используются для обновления коэффициентов цифрового фильтра и выбора источника возбуждения
иего уровня энергии. Выход цифрового фильтра преобразуется в аналоговый и подается на громкоговоритель для создания требуемого звука сопределенным тоном, амплитудой и гармоническим содержанием. Для сглаживания переходов в речевом спектре каждые З мс синтезатор обновляет параметры LPC, проводя интерполяцию между параметрамипредыдущего и следующего кадра.
Впервом режиме операции ребенка просят сказать слово по буквам. Ребенок вводит слово по одной букве с помощью клавиатуры. Если написание верно, то при нажатии клавиши <Enter> программа отвечает «Правильно» или «Верно». Если слово написано неверно, программа говорит «Неправильно, попробуй еще раз». Если же
иследующая попытка неверна, она указывает: «Это неправильно»
идобавляет: «Это слово пишется так...»
104
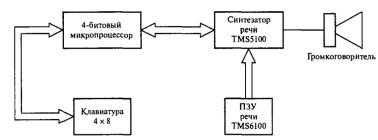
Рис. 6.4. Структура системы Speak and Spell
Под распознаванием голоса подразумевается, что информация вводится в компьютер с помощью человеческого голоса, а компьютер слушает и распознает человеческую речь. Распознавание голоса все еще активно изучается, так как поставленные задачи намного сложнее, чем те, которые возникают при синтезе речи. Поэтому успешные коммерческие системы распознавания речи немногочисленны и встречаются редко. Самыми удачными из них оказались настроенные на диктора системы распознавания изолированных слов. Такие системы работают в одном из двух режимов. В режиме обучения пользователь обучает систему распознавать его или ее голос, произнося каждое слово, подлежащее распознанию, в микрофон. Система оцифровывает и создает эталон каждого слова, сохраняя его в памяти. В режиме распознавания каждое произнесенное слово снова оцифровывается, и его эталон сравнивается с эталонами из памяти. Если есть соответствие, значит, слово распознано, и система сообщает об этом пользователю или выполняет какоето действие. Работа таких систем зависит от того, делает ли говорящий достаточно длинные паузы перед каждым словом, существует ли некий шумовой фон, и от того, насколько четко и ясно произносятся слова. Двумя самыми важными операциями ЦОС при распознавании являются извлечение параметров, когда из сказанного слова получаются отдельные образцы и создаются эталоны, и подбор по образцу, когда эталоны сравниваются с записями, которые хранятся в памяти (рис. 6.5).
105

Рис. 6.5. Блок-схема системы распознавания речи
Для большинства людей разговор – это самая естественная форма общения, ведь говорить намного быстрее, чем писать или печатать. Поэтому сейчас в офисах есть системы, которые позволяют управлять программами не нажатием клавиш, а произнесением команд. Разрабатываются системы, которые позволят создавать и отправлять с помощью голоса обычные офисные документы, такие как письма и служебные записки. Системы распознавания слов встречаются в товарах широкого потребления, таких как системы набора телефонного номера с речевым управлением, и в управляемых голосом предметах домашнего обихода для инвалидов с ограниченной способностью передвижения. Это делает таких людей более независимыми, позволяет самостоятельно выполнять некоторые простые действия, например, включать или выключать свет, радио или телевизор.
Конечно, существует еще множество возможных примеров применения систем распознавания речи. Впрочем, дальнейшее развитие в этой области зависит, главным образом, от технологий искусственного интеллекта, поскольку машины должны не только распознавать, но и понимать человеческую речь.
106
СПИСОК ЛИТЕРАТУРЫ
1.Лайонс Р. Цифровая обработка сигналов: пер. с англ. – М.:
БИНОМ, 2007. – 652 с.
2.Сергиенко А.Б. Цифровая обработка сигналов. – СПб.: Пи-
тер, 2006. – 750 с.
3.Документация MATLAB [Электронный ресурс]. – URL: https://docs.exponenta.ru/matlab/index.html.
4.Документация Scilab [Электронный ресурс]. – URL: https://www.scilab.org/tutorials.
5.Поликар Р. Введение в вейвлет-преобразование: пер. с англ. – СПб.: АВТЭКС. – 59 с.
6.Лукин А.С. Введение в цифровую обработку сигналов (математические основы). – М.: Изд-во МГУ, 2007. – 44 с.
7.Цифровая обработка изображений в информационных системах / И.С. Грузман, В.С. Киричук, В.П. Косых, Г.И. Перетягин, А.А. Спектор. – Новосибирск: Изд-во НГТУ, 2000. – 168 с.
8.Айфичер Э.С., Джервис Б.У. Цифровая обработка сигналов: практический подход. – М.: Вильямс, 2004. – 989 с.
107
ПРИЛОЖЕНИЕ
Листинг программ в средах моделирования
MathWorks MatLab и SciLab
1. Вычисление и построение спектральных характеристик в среде MathWorks Matlab
Модуль Signal.m (m-script, Matlab) close all;
N=100;
ts=0.001;%The sampling period fs=1/ts;%The sampling frequency
%fs/N must be integer digit!
%f signal must be proportional fs/N
T0=N*ts;
f0=1/T0;
t = 0:ts:T0-ts;
m=3;%rows n=3;%columns
%x1(t) f1 = f0;
x1 = 1*sin(2*pi*f1*t); func(N,ts,x1,m,n,1,['Signal x1(t) f1 = ',num2str(f1),' Hz']); func(N,ts,abs(x1),m,n,2,['Abs x1(t) f1 = ',num2str(f1),' Hz']); spectr(N,fs,f1,x1,m,n,3);
108
%x2(t)
f2 = 2*f0;
x2 = 0.4*sin(2*pi*f2*t); func(N,ts,x2,m,n,4,['Signal x2(t) f2 = ',num2str(f2),' Hz']); func(N,ts,abs(x2),m,n,5,['Abs x2(t) f2 = ',num2str(f2),' Hz']); spectr(N,fs,f2,x2,m,n,6);
%xsum(t) = x1(t) + x2(t) xsum = x1 + x2;
func(N,ts,xsum,m,n,7,['Signal xsum(t) f1=' num2str(f1) ' Hz, f2=' num2str(f2),' Hz']); func(N,ts,abs(xsum),m,n,8,['Abs xsum(t) f1=' num2str(f1) ' Hz, f2=' num2str(f2),' Hz']); spectr(N,fs,max(f1,f2),xsum,m,n,9);
Модуль func.m (m-script, Matlab) function func(Nview,ts,y,m,n,p,st);
t = 0:ts:(Nview-1)*ts; axes_handle=subplot(m,n,p); plot(1000*t(1:Nview),y(1:Nview)); set(axes_handle,'XGrid','on','YGrid','on','XLim' ,[0,Nview],'YLim',[-1.5,1.5]);
xlabel('t(ms)'); title(st);
Модуль spectr.m (m-script, Matlab) function spectr(N,fs,fmax,y,m,n,p);
%The spectrum characterisic forming
Y = fft(y,N);
109
%The power spectrum, a measurement of the power at various frequencies, is
Pyy = 2*abs(Y)/N;
N2=N/2;%The calculation N/2 points
f = fs*(0:N2)/N;%The analize frequency axes_handle=subplot(m,n,p);
N1 = N2+1;
N1 = (fmax * N / fs) * 2 + 1; stem(f(1:N1),Pyy(1:N1)); title('Magnitude'); xlabel('f(Hz)');
set(axes_handle,'XGrid','on','YGrid','on');
2. Вычисление и построение характеристик ДПФ в Scilab
Модуль FT.sce (Scilab) clc();
clear; xdel();
//Source data
N=8;//Points of transformation fs=8000;//Sampling Frequency ts=1/fs;//Sampling Period k=0;//Shift t=(k*ts:ts:(k+N-1)*ts);
A1=1;
f1=1000;
Q1=%pi/4;
A2=1;
f2=3000;
Q2=0;
110