

10.4. Улучшенные методы использования рекуррентных сетей 377
TensorFlow оптимизировать базовый граф вычислений. Правда при этом значительно увеличится потребление памяти вашей сетью RNN — в таком виде она будет пригодна только для обработки относительно небольших последовательностей (не более 100 шагов). Кроме того, поступить так можно, только если количество временных шагов в данных заранее известно (то есть если значение, передаваемое в параметре shape начального вызова Input(), не содержит None). Вот как это работает:
sequence_length не может быть None
inputs = keras.Input(shape=(sequence_length, num_features))
x = layers.LSTM(32, recurrent_dropout=0.2, unroll=True)(inputs)
Передайте unroll=True, чтобы разрешить развертывание
10.4.2. Наложение нескольких рекуррентных слоев друг на друга
Избавившись.от.эффекта.переобучения,.мы.столкнулись.с.проблемой.низкого.качества,.поэтому.теперь.нужно.подумать.об.увеличении.емкости.сети. и.ее.выразительной.мощности..Вспомните.описание.обобщенного.процесса. машинного.обучения:.рекомендуется.всегда.стараться.увеличивать.емкость. сети,.пока.на.первое.место.не.выйдет.проблема.переобучения.(при.условии.что. предприняты.все.основные.меры.против.нее,.такие.как.прореживание)..Пока. проблема.переобучения.не.стоит.остро,.вероятно,.сеть.имеет.недостаточную. емкость.
Увеличение.емкости.сети.обычно.осуществляется.за.счет.увеличения.числа.параметров.слоя.или.добавления.дополнительных.слоев..Наложение.рекуррентных. слоев.друг.на.друга.—.классический.способ.конструирования.более.мощных. рекуррентных.сетей:.например,.в.настоящее.время.алгоритм.Google.Translate. представляет.собой.стек.из.семи.больших.слоев.LSTM.—.это.огромная.сеть.
При.наложении.друг.на.друга.рекуррентных.слоев.в.Keras.все.промежуточные. слои.должны.возвращать.полные.выходные.последовательности.(трехмерный. тензор),.а.не.только.последний.интервал..Это.достигается.установкой.параметра. return_sequences=True.
В.следующем.примере.мы.попробуем.создать.стек.из.двух.рекуррентных.слоев. с.регуляризацией.прореживанием..Для.разнообразия.вместо.LSTM.используем. слои.управляемых.рекуррентных.блоков.(gated.recurrent.unit,.GRU)..Слой.GRU. очень.похож.на.слой.LSTM.—.это.более.простая.и.оптимизированная.версия. архитектуры.LSTM..Он.был.представлен.в.2014.году.Чо.с.коллегами,.когда.
378 Глава 10. Глубокое обучение на временных последовательностях
рекуррентные.сети.только.начинали.вновь.вызывать.интерес.в.крошечном.исследовательском.сообществе.того.времени1.
Листинг 10.23. Обучение и оценка модели с несколькими слоями GRU и с регуляризацией прореживанием
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.GRU(32, recurrent_dropout=0.5, return_sequences=True)(inputs) x = layers.GRU(32, recurrent_dropout=0.5)(x)
x = layers.Dropout(0.5)(x) outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [ keras.callbacks.ModelCheckpoint("jena_stacked_gru_dropout.keras", save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"]) history = model.fit(train_dataset,
epochs=50, validation_data=val_dataset, callbacks=callbacks)
model = keras.models.load_model("jena_stacked_gru_dropout.keras") print(f"Test MAE: {model.evaluate(test_dataset)[1]:.2f}")
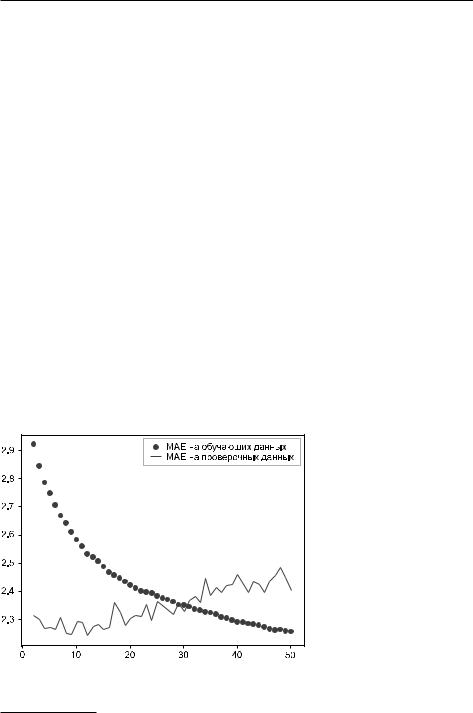
Результаты.показаны.на.рис..10.12..Мы.достигли.средней.абсолютной.ошибки. 2,39.градуса.(на.8,8.%.лучше.базового.решения)..Как.видите,.добавление.слоя. помогло.немного.улучшить.результаты,.хотя.и.незначительно..На.данный.момент. вы.можете.наблюдать.уменьшение.отдачи.от.увеличения.емкости.сети.
Рис. 10.12. Потери на этапах обучения и проверки многослойной модели на основе GRU в задаче прогнозирования температуры по данным Jena
1. Cho et al..On.the.Properties.of.Neural.Machine.Translation:.Encoder-Decoder.Approaches..
2014,.https://arxiv.org/abs/1409.1259.

10.4.Улучшенные методы использования рекуррентных сетей 379
10.4.3.Использование двунаправленных рекуррентных нейронных сетей
Последнее.средство,.которое.мы.рассмотрим.в.этом.разделе,.называется.«двунаправленные рекуррентные нейронные сети».(bidirectional.RNN)..Двунаправ- ленная.рекуррентная.сеть.—.распространенная.разновидность.рекуррентных. сетей,.способная.обеспечить.более.высокое.качество.решения.некоторых.задач.. Она.часто.используется.в.обработке.естественного.языка.—.ее.можно.даже. назвать.швейцарским.армейским.ножом.глубокого.обучения.для.обработки. естественного.языка.
Рекуррентные.сети.зависят.от .порядка.или.от .времени:.они.обрабатывают. входные.последовательности.по.порядку,.и.любое.изменение.порядка.следования.данных.может.полностью.изменить.представление,.которое.рекуррентная.сеть.извлечет.из.последовательности..Именно.поэтому.они.так.хорошо. справляются .с .задачами, .в .которых .порядок .имеет .значение .(такими .как. задача.прогнозирования.температуры)..Двунаправленная.рекуррентная.сеть. использует.чувствительность.RNN.к.порядку:.она.состоит.из.двух.обычных. рекуррентных.сетей,.таких.как.слои.GRU .и.LSTM,.с.которыми.вы.уже.знакомы,. каждая .из .этих .сетей .обрабатывает .входную .последовательность .в .одном. направлении .(прямом .или .обратном), .и .затем .полученные .представления. объединяются..Обрабатывая.последовательность.в.двух.направлениях,.двунаправленная.рекуррентная.сеть.способна.выявить.шаблоны,.незаметные.для. однонаправленной.сети.
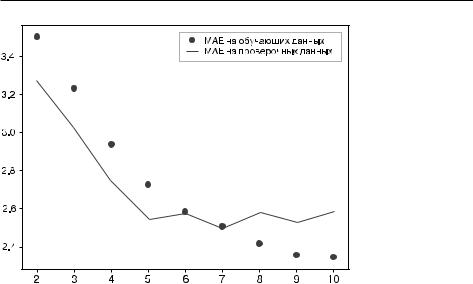
Примечательно,.что.обработка.последовательностей.в.хронологическом.порядке. (от.старых.к.новым).в.данном.разделе.была.выбрана.совершенно.произвольно.. По.крайней.мере,.мы.не.пытались.поставить.это.решение.под.вопрос..Могут.ли. рекуррентные.сети.показывать.хорошие.результаты,.обрабатывая.последовательности,.например,.в.обратном.порядке.(от.новых.к.старым)?.Давайте.попробуем.применить.решение.и.посмотрим,.что.получится..Нужно.лишь.написать. вариант.генератора.данных,.обращающий.входные.последовательности.(проще. говоря,.заменить.последнюю.строку.инструкцией.yield .samples[:, .::-1, .:], . targets)..Обучение.той.же.модели.на.основе.LSTM,.которая.использовалась. в.первом.эксперименте.данного.раздела,.дало.результаты,.представленные.на. рис..10.13.
Сеть.LSTM,.обрабатывающая.последовательности.в.обратном.порядке,.не.до- стигает.даже.уровня.базового.решения.—.явное.свидетельство.того,.что.в.данном. случае.хронологический.порядок.обработки.имеет.большое.значение.для.успеха.. Это.вполне.объяснимо:.слой.LSTM.обычно.запоминает.недавнее.прошлое.лучше,. чем.более.отдаленное,.и,.естественно,.более.свежая.информация.о.погоде.имеет. большее.значение.для.прогнозирования,.чем.старая.(вот.почему.базовое.решение. без.привлечения.машинного.обучения.дает.такую.высокую.точность)..Поэтому. версия.слоя,.обрабатывающая.данные.в.прямом.порядке,.должна.превосходить. версию,.обрабатывающую.данные.в.обратном.порядке.
380 Глава 10. Глубокое обучение на временных последовательностях |
Рис. 10.13. Потери на этапах обучения и проверки модели на основе LSTM в задаче |
прогнозирования температуры по данным Jena с обучением на обращенных |
последовательностях |
Следует.отметить,.что.это.не.всегда.верно.для.других.задач,.в.том.числе.обработки.естественных.языков:.очевидно,.важность.слова.для.понимания.предложения.обычно.не.зависит.от.его.позиции.в.предложении..Обработка.текстовых. данных.в.обратном.порядке.дает.результаты.не.хуже,.чем.обработка.в.прямом. порядке,.—.человек.может.читать.текст.в.обратном.порядке.и.понимать.его.смысл. (попробуйте!)..Конечно,.порядок.слов.важен.для.понимания.языка,.но.порядок их чтения.не.имеет.решающего.значения.
Важно .также .отметить, .что .рекуррентная .сеть, .обученная .на .обращенных. последовательностях, .получит .иные .представления, .так .же .как .вы .сами. получили.бы.разные .ментальные .модели, .если .бы .время.текло.в .обратном. направлении.и.вы.проживали.бы.свою.жизнь.в.направлении.от.смерти.к.ро ждению..В.машинном.обучении.не.следует.пренебрегать.разными,.но.полезными. представлениями,.и.чем.больше.они.различаются,.тем.лучше:.они.позволяют. взглянуть.на.данные.под.другим.углом,.обнаружить.аспекты,.пропущенные. другими .подходами, .и, .как .результат, .улучшить .качество .решения .задачи.. Эта.идея.лежит.в.основе.метода.обучения ансамблей,.который.мы.рассмотрим. в.главе.13.
Двунаправленная .рекуррентная .сеть .использует .эту .идею .для .улучшения. качества.обучения.на.упорядоченных.данных..Она.просматривает.входную.последовательность.в.обоих.направлениях.(рис..10.14),.получает.потенциально. более.насыщенные.представления.и.выделяет.шаблоны,.которые.могли.быть. упущены.однонаправленной.версией.
10.4. Улучшенные методы использования рекуррентных сетей 381
Рис. 10.14. Принцип действия двунаправленной рекуррентной нейронной сети
Для .создания .двунаправленной .рекуррентной .сети .в .Keras .имеется .слой. Bidirectional,.который.в.своем.первом.аргументе.принимает.экземпляр.рекуррентного.слоя..Слой.Bidirectional .создает.второй,.отдельный.экземпляр.этого. рекуррентного.слоя.и.использует.один.экземпляр.для.обработки.входных.по- следовательностей.в.прямом.порядке,.а.другой.—.в.обратном..Давайте.опробуем. этот.прием.на.задаче.прогнозирования.температуры.
Листинг 10.24. Обучение и оценка двунаправленной модели LSTM
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1])) x = layers.Bidirectional(layers.LSTM(16))(inputs)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs) model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"]) history = model.fit(train_dataset,
epochs=10, validation_data=val_dataset)
Качество.этой.модели.по.сравнению.с.обычным.слоем.LSTM .ничуть.не.улучшилось..Легко.понять.почему:.все.прогностические.способности.исходят.из. половины.сети,.обрабатывающей.данные.в.прямом.хронологическом.порядке,. поскольку,.как.мы.уже.выяснили,.качество.половины,.обрабатывающей.данные. в.обратном.порядке,.в.этой.задаче.сильно.отстает.(в.данном.случае.недавнее. прошлое.имеет.большее.значение,.чем.отдаленное)..В.то.же.время.наличие.половины,.обрабатывающей.данные.в.обратном.порядке,.удваивает.емкость.сети,. вследствие.чего.эффект.переобучения.наступает.раньше.
Однако.двунаправленные.рекуррентные.сети.прекрасно.подходят.для.обработки.текстовых.или.любых.других.типов.данных,.где.порядок.имеет.значение,.но. используемый порядок.не.так.важен..Фактически.в.течение.некоторого.времени. в.2016.году.двунаправленные.сети.LSTM.считались.наиболее.совершенным. средством.решения.многих.задач.обработки.естественного.языка.(до.появления. архитектуры.Transformer,.с.которой.вы.познакомитесь.в.следующей.главе).