

298 |
Глава 8. Введение в глубокое обучение в технологиях зрения |
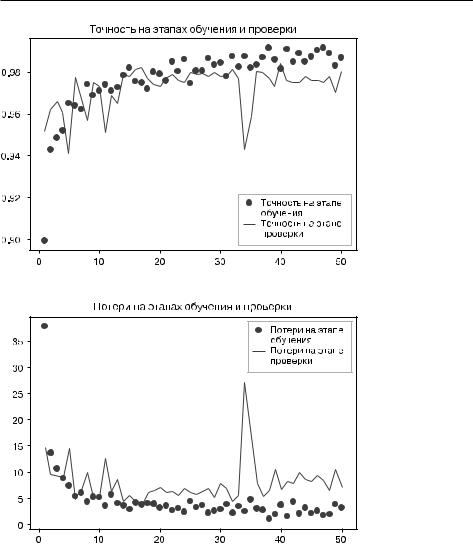
Рис. 8.14. Изменение метрик на этапах проверки и обучения для извлечения |
признаков с обогащением данных |
8.3.2. Дообучение предварительно обученной модели
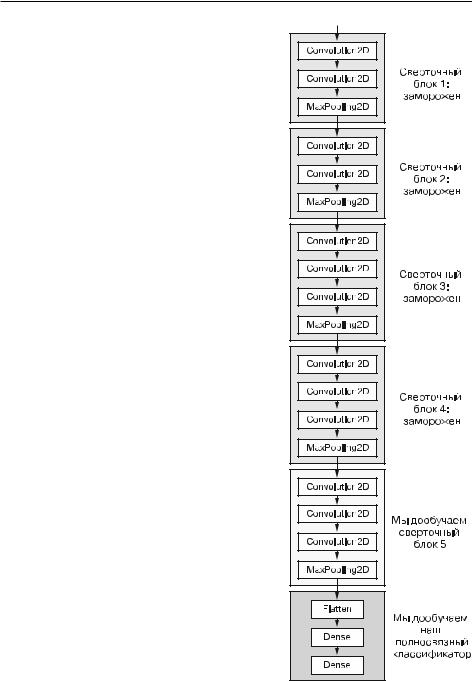
Другой.широко.используемый.прием.повторного.использования.модели,.допол- няющий.выделение.признаков,.—.дообучение (fine-tuning).(рис..8.15)..Дообуче ние.заключается.в.размораживании.нескольких.верхних.слоев.замороженной.
8.3. Использование предварительно обученной модели 299
модели,.которая.использовалась.для.выделения.признаков,.и.совместном.обучении.вновь. добавленной.части.модели.(в.данном.случае. полносвязного.классификатора).и.этих.верхних.слоев..Данный.прием.называется.дообуче нием,.поскольку.немного.корректирует.наиболее.абстрактные.представления.в.повторно. используемой.модели,.чтобы.сделать.их.более. актуальными.для.конкретной.задачи.
Выше.я.отмечал,.что.для.обучения.классификатора, .инициализированного .случайными. значениями,.необходимо.заморозить.сверточную.основу.сети.VGG16..По.той.же.причине. дообучить.несколько.верхних.слоев.сверточной .основы .можно .только .после .обучения. классификатора..Если .классификатор .еще. не .обучен, .ошибочный .сигнал, .распространяющийся .по .сети .в .процессе .дообучения,. окажется.слишком.велик,.и.представления,. полученные.на.предыдущем.этапе.обучения,. будут.разрушены..Поэтому.для.дообучения. сети.нужно.выполнить.следующие.шаги.
1.. Добавить.свою.сеть.поверх.обученной.базовой.сети.
2.. Заморозить.базовую.сеть.
3.. Обучить.добавленную.часть.
4.. Разморозить .несколько .слоев .в .базовой. сети..(Обратите.внимание,.что.не.следует. размораживать.слои.«пакетной.нормализации», .которые .здесь .неактуальны, .по- скольку.в.VGG16.таких.слоев.нет,.—.я.объ- ясню.пакетную.нормализацию.и.покажу. ее .влияние .на .дообучение .в .следующей. главе.)
5.. Обучить .эти .слои .и .добавленную .часть. вместе.
Мы.уже.выполнили.первые.три.шага.в.ходе. выделения.признаков..Теперь.выполним.шаг.4:. разморозим.conv_base.и.заморозим.отдельные. слои.в.ней.
Рис. 8.15. Дообучение последнего сверточного блока сети VGG16

300 Глава 8. Введение в глубокое обучение в технологиях зрения
Вспомним,.как.выглядит.наша.сверточная.основа:
>>> conv_base.summary() Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_19 (InputLayer) [(None, 180, 180, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 180, 180, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 180, 180, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 90, 90, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 90, 90, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 90, 90, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 45, 45, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 45, 45, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 45, 45, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 45, 45, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 22, 22, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 22, 22, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 22, 22, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 22, 22, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 11, 11, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 11, 11, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 11, 11, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 11, 11, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 5, 5, 512) 0
=================================================================
Total params: 14,714,688 Trainable params: 14,714,688 Non-trainable params: 0
_________________________________________________________________
8.3. Использование предварительно обученной модели 301
Почему.бы.не.дообучить.больше.слоев?.Почему.бы.не.дообучить.всю.сверточную. основу?.Так.можно.поступить,.но.имейте.в.виду.следующее.
.Начальные.слои.в.сверточной.основе.кодируют.более.обобщенные.признаки,. пригодные.для.повторного.использования,.а.более.высокие.слои.кодируют. более.конкретные.признаки..Намного.полезнее.донастроить.более.конкретные.признаки,.потому.что.именно.их.часто.нужно.перепрофилировать.для. решения.новой.задачи..Ценность.дообучения.нижних.слоев.быстро.падает. с.их.глубиной.
.Чем.больше.параметров.обучается,.тем.выше.риск.переобучения..Сверточная.основа.имеет.15.миллионов.параметров,.поэтому.было.бы.слишком. рискованно.пытаться.дообучить.ее.целиком.на.нашем.небольшом.наборе. данных.
То.есть.в.данной.ситуации.лучшей.стратегией.будет.дообучить.только.верхние. 2–3.слоя.сверточной.основы..Сделаем.это,.начав.с.того.места,.на.котором.мы. остановились.в.предыдущем.примере.
Листинг 8.27. Замораживание всех слоев, кроме заданных
conv_base.trainable = True
for layer in conv_base.layers[:-4]: layer.trainable = False
Теперь.можно.начинать.дообучение.модели..Для.этого.используем.оптимизатор.RMSProp.с.очень.маленькой.скоростью.обучения..Причина.использования. низкой.скорости.обучения.заключается.в.необходимости.ограничить.величину. изменений,.вносимых.в.представления.трех.дообучаемых.слоев..Слишком.большие.изменения.могут.повредить.эти.представления.
Листинг 8.28. Дообучение модели
model.compile(loss="binary_crossentropy", optimizer=keras.optimizers.RMSprop(learning_rate=1e-5), metrics=["accuracy"])
callbacks = [ keras.callbacks.ModelCheckpoint(
filepath="fine_tuning.keras", save_best_only=True, monitor="val_loss")
]
history = model.fit( train_dataset, epochs=30,
validation_data=validation_dataset, callbacks=callbacks)