

1.6 Организация внешней памяти реляционной субд
СУБД обладает рядом особенностей, влияющих на организацию внешней памяти [4, 6]. К наиболее важным можно отнести следующие:
Наличие двух уровней системы: уровня непосредственного управления данными во внешней памяти и языкового уровня. При такой организации подсистема нижнего уровня должна поддерживать во внешней памяти набор базовых структур, конкретная интерпретация которых входит в число функций подсистемы верхнего уровня.
Поддержание системных каталогов. Информация, связанная с именованием объектов БД и их параметрами, поддерживается подсистемой языкового уровня.
Регулярность структур данных. Поскольку основным объектом реляционной модели данных является плоская таблица, главный набор объектов внешней памяти может иметь очень простую регулярную структуру. При этом необходимо обеспечить возможность эффективного выполнения операторов как над одной таблицей, так и над несколькими. Для этого во внешней памяти должны поддерживаться дополнительные «управляющие» структуры − индексы.
Надежное хранение. Для выполнения требования надежного хранения БД необходимо поддерживать избыточность хранения данных, что обычно реализуется в виде журнала изменений БД.
Наличие перечисленных особенностей привело к созданию во внешней памяти следующих разновидностей объектов базы данных:
строки таблиц – основная часть БД, непосредственно видимая пользователям;
управляющие структуры – индексы, создаваемые из соображений повышения эффективности выполнения запросов и обычно автоматически поддерживаемые нижним уровнем системы;
журнал - специальный файл, поддерживаемый для удовлетворения потребности в надежном хранении данных;
служебная информация - информация, которая поддерживается для удовлетворения внутренних потребностей нижнего уровня системы (например, информация о свободной памяти).
Хранение отношений. Существуют два принципиальных подхода к физическому хранению таблиц: хранить строками или столбцами. Наиболее распространенным является строковое (страничное) хранение. Естественно, это обеспечивает быстрый доступ к целому кортежу, но при этом во внешней памяти дублируются общие значения разных кортежей одной таблицы и могут потребоваться лишние обмены с внешней памятью, если нужна часть кортежа.
Основные принципы организации хранения кортежей:
Каждый кортеж обладает уникальным идентификатором, не изменяемым во все время существования кортежа и позволяющим выбрать кортеж в основную память не более чем за два обращения к внешней памяти.
Обычно каждый кортеж хранится целиком в одной странице. Из этого следует, что максимальная длина кортежа любой таблицы ограничена размерами страницы и возникает вопрос хранения «длинных» данных. Для его решения применяется несколько методов: хранение таких данных в отдельных файлах вне БД с заменой «длинного» данного в кортеже на имя соответствующего файла; хранение внутри БД в отдельном наборе страниц внешней памяти, связанном физическими ссылками; хранение в виде B-деревьев последовательностей байт.
Как правило, в одной странице данных хранятся кортежи только одной таблицы. Существуют варианты с возможностью хранения в одной странице кортежей нескольких таблиц. Хотя это вызывает некоторые дополнительные расходы по части служебной информации (при каждом кортеже нужно хранить информацию о соответствующей таблице), но при этом позволяет резко сократить число обменов с внешней памятью при выполнении соединений.
Изменение структуры хранимой таблицы с добавлением нового поля не вызывает потребности в физической реорганизации таблицы. Достаточно лишь изменить информацию в описателе таблицы, и расширяться кортежи только при занесении информации в новое поле.
Проблема распределения памяти в страницах данных связана с проблемами синхронизации и журнализации и не всегда тривиальна. Например, если в ходе выполнения транзакции некоторая страница данных опустошается, то ее нельзя перевести в статус свободных страниц до конца транзакции, поскольку при откате транзакции удаленные при прямом выполнении транзакции и восстановленные при ее откате кортежи должны получить те же самые идентификаторы.
Распространенным способом повышения эффективности СУБД является кластеризация таблицы по значениям одного или нескольких столбцов. Полезной для оптимизации соединений является совместная кластеризация нескольких таблиц.
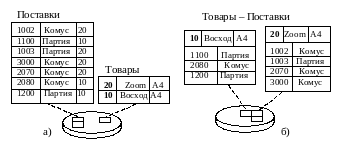
Кластеризация является методом совместного хранения родственных данных (таблиц).
Кластер – это структура памяти, в которой хранится набор таблиц (в одних и тех же блоках памяти). Таблицы, помещаемые в кластер, должны иметь общие столбцы, используемые для соединения.
Рисунок
Кластерный ключ (КК) – это поле или набор полей, общих для всех таблиц кластера. Каждая таблица, хранимая в кластере, должна иметь поля, соответствующие типам и размерам полей кластерного ключа. Количество полей в кластерном ключе ограничено. Фактически, данные хранятся в виде соединения таблиц по значениям кластерного ключа. Поэтому соединение кластеризованных таблиц по сравнению с раздельно хранимыми таблицами выполняется в 3-6 раз быстрее.
Если все данные, относящиеся к одному значению кластерного ключа, не помещаются в одном блоке, то выделяется новый блок памяти и предыдущий блок хранит ссылку на него. Но если система позволяет изменять размер блока, при создании кластера желательно установить размер блока исходя из оценки среднего объёма записей с одинаковыми значениями кластерного ключа. Если же записи с одинаковым значением КК занимают только часть блока (например, в среднем 1К при размере блока 4К), то при создании таблицы кластера можно указать количество значений КК на один блок.
Два основных преимущества кластеров:
Уменьшается время соединения таблиц по значению кластерного ключа.
Каждое значение кластерного ключа хранится только один раз, за счёт чего достигается экономия памяти.
Недостатки:
Наличие кластеров обычно увеличивает время выполнения операции добавления записи (INSERT): система тратит дополнительное время на поиск блока, в который нужно поместить новую запись.
Чтение отдельной таблицы из кластера может занимать гораздо больше времени, чем чтение некластеризованной таблицы.
Значения кластерного ключа таблицы могут обновляться. Но это обновление может вызвать физическое перемещение записи, т.к. расположение записи зависит от значения кластерного ключа. Поэтому часто обновляющиеся атрибуты не являются хорошими кандидатами на вхождение в кластерный ключ
С целью использования возможностей распараллеливания обменов с внешней памятью иногда применяют схему декластеризованного хранения таблиц: кортежи с общим значением столбца декластеризации размещают на разных дисковых устройствах, обмены с которыми можно выполнять параллельно.
Альтернативным (менее распространенным) подходом является хранение отношения по столбцам, т.е. единицей хранения является столбец таблицы с исключенными дубликатами. Естественно, что при такой организации суммарно в среднем тратится меньше внешней памяти, поскольку дубликаты значений не хранятся; за один обмен с внешней памятью в общем случае считывается больше полезной информации. Дополнительным преимуществом является возможность использования значений столбца для оптимизации выполнения операций соединения. Но при этом требуются существенные дополнительные действия для сборки целой строки (или ее части). На основе этого подхода в распределенных БД возникло целое направление колоночных БД, применяемых для работы аналитических систем.
Индексы. В общем виде, индекс в базах данных — это файл с последовательностью пар ключей и указателей. Идея использования индексов пришла от того, что современные базы данных слишком массивны и не помещаются в основную память, поэтому данные делятся на блоки и размещаются по-блочно, и хотя при этом поиск записи в БД может занять много времени, с другой стороны, файл индексов или блок индексов намного меньше блока данных и может поместиться в буфере основной памяти, что увеличивает скорость поиска записи.
Существует два типа индексов: кластерные и некластерные. При наличии кластерного индекса строки таблицы упорядочены по значению ключа этого индекса. Если в таблице нет кластерного индекса, таблица называется кучей. Некластерный индекс, созданный для такой таблицы, содержит только указатели на записи таблицы. Кластерный индекс может быть только одним для каждой таблицы, но каждая таблица может иметь несколько различных некластерных индексов, каждый из которых определяет свой собственный порядок следования записей.
Индексы могут быть реализованы различными структурами. Наиболее часто B*-деревья, B+-деревья, B-деревья и хеши.
Также индекс может быть разреженный и плотный. Разрежённый индекс (sparse index), характеризуется тем, что каждый ключ ассоциируется с определённым указателем на блок в сортированном файле данных.
Плотный индекс (dense index) отличается тем, что каждый ключ ассоциируется с определённым указателем на запись в сортированном файле данных.
В кластерных индексах с дублированными ключами разрежённый индекс указывает на наименьший ключ в каждом блоке, в то время как плотный индекс указывает на первую запись с указанным ключом.
Основное назначение индексов состоит в обеспечении эффективного прямого доступа к строке таблицы по ключу. На практике при объявлении первичного ключа таблицы (primary key) автоматически создается уникальный индекс, а единственным способом объявления возможного ключа, отличного от первичного, является явное создание уникального индекса (uniquie). Это связано с тем, что для проверки сохранения свойства уникальности возможного ключа, так или иначе, требуется индексная поддержка.
Поскольку при выполнении многих операций языкового уровня требуется сортировка отношений в соответствии со значениями некоторых атрибутов, полезным свойством индекса является обеспечение последовательного просмотра строк таблицы в диапазоне значений ключа в порядке возрастания или убывания этих значений.
Наконец, одним из способов оптимизации выполнения соединения таблиц по равенству значений некоторых столбцов является организация так называемых мультииндексов, обладающих общими атрибутами нескольких таблиц. Любой из этих атрибутов (или их набор) может выступать в качестве ключа мультииндекса. Значению ключа сопоставляется набор строк всех связанных мультииндексом отношений, значения выделенных атрибутов которых совпадают со значением ключа.
Общей идеей любой организации индекса, поддерживающего прямой доступ по ключу и последовательный просмотр в порядке возрастания или убывания значений ключа, является хранение упорядоченного списка значений ключа с привязкой к каждому значению ключа списка идентификаторов строк. Одна организация индекса отличается от другой главным образом по способу поиска ключа с заданным значением.
B-дерево. Наиболее популярным подходом к организации индексов в БД является использование техники B-деревьев. С точки зрения внешнего логического представления B-дерево – это сбалансированное сильноветвистое дерево во внешней памяти. Сбалансированность означает, что длина пути от корня дерева к любому его листу одна и та же. Ветвистость дерева – это свойство каждого узла дерева ссылаться на большое число узлов-потомков. С точки зрения физической организации B-дерево представляется как мультисписочная структура страниц внешней памяти, т.е. каждому узлу дерева соответствует блок внешней памяти (страница). Внутренние и листовые страницы обычно имеют разную структуру.
Поиск в B-дереве – это прохождение от корня к листу в соответствии с заданным значением ключа. Заметим, что поскольку деревья сильноветвистые и сбалансированные, то для выполнения поиска по любому значению ключа потребуется одно и то же (и обычно небольшое) число обменов с внешней памятью. Более точно: если в сбалансированном дереве на внутренней странице помещается n ключей, то при хранении m записей требуется дерево глубиной logn(m), где logn – логарифм по основанию n. Если n достаточно велико, то глубина дерева невелика, и производится быстрый поиск.
Основной особенностью B-деревьев является автоматическое поддержание свойства сбалансированности. При выполнении операций вставки и удаления свойство сбалансированности B-дерева сохраняется, а внешняя память расходуется достаточно экономно.
Проблемой использования B-деревьев является то, что при выполнении операций модификации слишком часто могут возникать расщепления и слияния.
Рассмотрим подробнее структуру и основные операции с B-деревом. При построении B-дерева применяется фактор t, который называется минимальной степенью. Каждый узел, кроме корневого, должен иметь, как минимум t – 1, и не более 2t – 1 ключей. Обозначается n[x] – количество ключей в узле x. Ключи в узле хранятся в неубывающем порядке. Если x не является листом, то он имеет n[x] + 1 детей. Если занумеровать ключи в узле x, как k[i], а детей c[i], то для любого ключа в поддереве с корнем c[i] (пусть, например, k1), выполняется следующее неравенство – k[i-1] ≤k1≤k[i] (для c[0]: k[i-1] = -∞, а для c[n[x]]: k[i] = +∞). Таким образом, ключи узла задают диапазон для ключей их детей.
Все листья B-дерева должны быть расположены на одной высоте, которая и является высотой дерева. Очень важно, что высота B-дерева с n ≥ 1 узлами и минимальной степенью t ≥ 2 не превышает logt(n+1):
h ≤ logt((n+1)/2).
Операции, выполнимые с B-деревом: Поиск
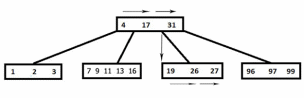
Поиск в B-дереве очень схож с поиском в простом бинарном дереве, только выбор пути к потомку состоит не из 2 вариантов, а из нескольких. В остальном никаких отличий нет. На рисунке ниже показан поиск ключа 27.
Рисунок
Алгоритм: идем по ключам корня, пока меньше необходимого. В данном случае дошли до 31. Спускаемся к ребенку, который находится левее этого ключа. Идем по ключам нового узла, пока меньше 27. В данном случае – нашли 27 и остановились.
Операция поиска выполняется за время O(t logt n), где t – минимальная степень. Важно здесь, что дисковых операций совершается всего лишь O(logt n).
Операции, выполнимые с B-деревом: Добавление
В отличие от поиска, операция добавления существенно сложнее, чем в бинарном дереве, так как просто создать новый лист и вставить туда ключ нельзя, поскольку будут нарушаться свойства B-дерева. Также вставить ключ в уже заполненный лист невозможно, то есть необходима операция разбиения узла на 2. Если лист был заполнен, то в нем находилось 2t-1 ключей, тогда разбиваем на 2 по t-1, а средний элемент (для которого t-1 первых ключей меньше его, а t-1 последних больше) перемещается в родительский узел. Соответственно, если родительский узел также был заполнен, то опять приходится разбивать. И так далее до корня (если разбивается корень, то появляется новый корень и глубина дерева увеличивается). Как и в случае обычных бинарных деревьев, вставка осуществляется за один проход от корня к листу. На каждой итерации (в поисках позиции для нового ключа – от корня к листу) расщепляются все заполненные узлы, через которые проходим (в том числе лист). Таким образом, если в результате для вставки потребуется разбить какой-то узел, ест гарантия того, что его родитель не заполнен.
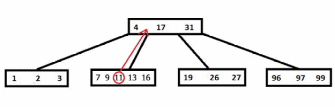
На рисунке проиллюстрировано то же дерево, что и в поиске (t=3), на которое добавляем ключ «15». В поисках позиции для нового ключа встречается заполненный узел (7, 9, 11, 13, 16). Следуя алгоритму, разбиваем его – при этом «11» переходит в родительский узел, а исходный разбивается на 2. Далее ключ «15» вставляется во второй «отколовшийся» узел и все свойства B-дерева сохраняются.
Рисунок
Рисунок
Операция добавления происходит также за время O(t logt n). Важно опять же, что дисковых операций выполняется всего лишь O(h), где h – высота дерева.
Операции, выполнимые с B-деревом: Удаление
Удаление ключа из B-дерева еще более громоздкий и сложный процесс, чем вставка. Это связано с тем, что удаление из внутреннего узла требует перестройки дерева в целом. Аналогично вставке необходимо проверять, что сохраняются свойства B-дерева, только в данном случае нужно отслеживать, когда ключей t-1 (то есть, если из этого узла удалить ключ – то узел не сможет существовать). Рассмотрим алгоритм удаления:
1)Если удаление происходит из листа, то необходимо проверить, сколько ключей находится в нем. Если больше t-1, то просто удаляем и больше ничего делать не нужно. Иначе, если существует соседний лист (находящийся рядом с ним и имеющий такого же родителя), который содержит больше t-1 ключа, то выберается ключ из этого соседа, который является разделителем между оставшимися ключами узла-соседа и исходного узла (то есть не больше всех из одной группы и не меньше всех из другой). Пусть это ключ k1. Далее выбирается ключ k2 из узла-родителя, который является разделителем исходного узла и его соседа, который выбран ранее. Удаляется из исходного узла нужный ключ (который необходимо было удалить), спускается k2 в этот узел, а вместо k2 в узле-родителе указывается k1. На рисуноке удаляется ключ «9». Если же все соседи узла имеют по t-1 ключу, то узел объединяется с каким-либо соседом, и удаляется нужный ключ. И тот ключ из узла-родителя, который был разделителем для этих двух «бывших» соседей, перемещается в новообразовавшийся узел (очевидно, он будет в нем медианой).
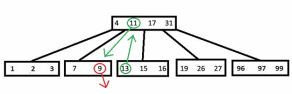
Рисунок
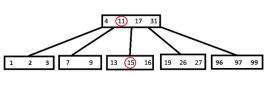
2)Теперь рассмотрим удаление из внутреннего узла x ключа k. Если дочерний узел, предшествующий ключу k содержит больше t-1 ключа, то находится k1 – предшественник k в поддереве этого узла и удаляется (рекурсивно запускается алгоритм). Заменяется k в исходном узле на k1. Аналогично, если дочерний узел, следующий за ключом k, имеет больше t-1 ключа. Если оба (следующий и предшествующий дочерние узлы) имеют по t-1 ключу, то объединяюся дети, переносится в них k, а далее удаляется k из нового узла (рекурсивно запускается алгоритм). Если сливаются 2 последних потомка корня – то они становятся корнем, а предыдущий корень освобождается. Ниже представлен рисунок , где из корня удаляется «11» (случай, когда у следующего узла больше t-1 ребенка).
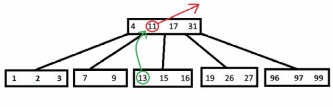
Рисунок
Операция удаления происходит за такое же время, что и вставка O(t logt n). Да и дисковых операций требуется всего лишь O(h), где h – высота дерева.
Таким образом на простых примерах показаны основные преимущества: одно время выполнения и сбалансированность В-дерева. Проанализировав, вместе со скоростью выполнения, количество проведенных операций с дисковой памятью, мы можем сказать, что B-дерево несомненно является более выгодной структурой данных для случаев, когда существует большой объем информации в БД.
Очевидно, что при увеличении t (минимальной степени), увеличивается ветвление дерева, а следовательно, уменьшается высота. Значение t выбирается, как правило, согласно размеру доступной оперативной памяти (т.е. указывает сколько ключей можно единовременно просматривать). Обычно это число находится в пределах от 50 до 2000. Пусть есть миллиард ключей и t=1001, тогда потребуется всего лишь 3 дисковые операции для поиска любого ключа, при чем корень может храниться постоянно! Также, необходимо понимать, что происходит чтение не отдельных данные из разных мест, а целыми блоками и, при перемещении узла дерева в оперативную память, перемещается выделенный блок последовательной памяти, и эта операция тоже достаточно быстро работает. В результате имеется минимальная нагрузка на сервер, и при этом малое время ожидания. Эти и другие описанные преимущества позволили B-деревьям стать основой для индексов, базирующихся на В-деревьях в СУБД.
Хеширование. Альтернативным, более популярным, но и более сложным в понимании и реализации подходом к организации индексов является использование техники хеширования. Общей идеей методов хеширования является применение к значению ключа некоторой функции свертки (хэш-функции), вырабатывающей значение меньшего размера, которое затем используется для доступа к записи.
Принцип хеширования: для определения адреса записи в области хранения к значению ключевого поля этой записи применяется хеш-функция h(K), которая преобразует значение ключа K в адрес участка памяти (это называется свёрткой ключа). Новая запись будет размещаться по тому адресу, который выдаст хеш-функция для ключа этой записи.
Хеш-функция h(K) должна обладать следующими свойствами:
выдавать такие значения адресов, чтобы обеспечить равномерное распределение записей в памяти, в частности, для близких значений ключа значения адресов должны сильно отличаться, чтобы избегать перекосов в размещении данных: K1 K2 h(K1)>>h(K2) V h(K2)>>h(K1);
для разных значений ключа выдавать разные адреса: K1 K2 h(K1) h(K2).
Для реальных функций хеширования допускается совпадение значений функции h(K) для различных ключей. Для разрешения неопределённости при совпадении адресов после вычисления h(K) используются специальные методы разрешения коллизий.
Коллизия – случай, когда для двух и более ключей выдаётся одинаковый адрес. Разрешение коллизий – рехеширование – специальный алгоритм, который используется каждый раз при размещении новой записи или при поиске существующей, если возникла коллизия.
В системах БД рехеширование выполняется одним из следующих способов:
Открытая адресация: новая запись размещается вслед за последней записью на данной странице или на следующей, если страница заполнена.
Использование коллизионных страниц: новая запись размещается на одной из коллизионных страниц, относящихся к таблице (в области переполнения). Для ускорения поиска рехешированных записей может использоваться связанная область переполнения, для которой на странице хранится ссылка на коллизионную страницу. Нулевое значение такой ссылки говорит об отсутствии коллизий для данных, размещённых на этой странице.
Многократное хеширование. Заключается в том, что при возникновении коллизии для поиска другого адреса (возможно, на коллизионных страницах) применяется другая функция хеширования.
Рассмотрим два основных метода хеширования. Предполагаем, что хеш-функция h(K): 0h(K)N для всех ключей K, где N – размер памяти (количество ячеек).
Метод деления использует остаток от деления на М:
h(K)= К mod M.
Если М – чётное число, то при чётных К значение h(K) будет чётным, и наоборот, что даёт значительные смещения значений функции для близких значений К. Нельзя брать М кратным основанию системы счисления машины или кратным 3. М должно удовлетворять условию:
М rk a ,
где k и a – небольшие числа, а r – "основание системы счисления" для большинства используемых литер (как правило, 128 или 256), т.к. остаток от деления на такое число оказывается обычно простой суперпозицией цифр ключа. Чаще всего в качестве М берут простое число, например, вполне удовлетворительные результаты даёт М = 1009.
Мультипликативный метод. В соответствии с ним хеш-функция определяется так:
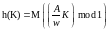 ,
,
где w – размер машинного слова (обычно, 231); А – целое число простое по отношению к w;
M – некоторая степень основания системы счисления ЭВМ (2m).
Таким образом, в качестве значения функции берутся M правых значащих цифр дробной части произведения значения ключа и константы A/w.
При использовании любых методов хеширования для размещения записей должен быть выделен участок памяти размером N. Для того чтобы полученное в результате значение h(K) не вышло за границы отведённого участка памяти, окончательно адрес записи вычисляется так:
А(К) = h(K) mod N.
Итак, в самом простом, классическом случае свертка ключа используется как адрес в таблице, содержащей ключи и записи. Основным требованием к хэш-функции является равномерное распределение значения свертки. При возникновении коллизий (одна и та же свертка для нескольких значений ключа) образуются цепочки переполнения. Главным ограничением этого метода является фиксированный размер таблицы. Если таблица заполнена слишком сильно или переполнена, то возникнет слишком много цепочек переполнения, и главное преимущество хеширования – доступ к записи почти всегда за одно обращение к таблице – будет утрачено. Расширение таблицы требует ее полной переделки на основе новой хэш-функции со значением свертки большего размера. В случае работы с БД такие действия являются неприемлемыми. Поэтому обычно вводят промежуточные таблицы-справочники, содержащие значения ключей и адреса записей, а сами записи хранятся отдельно. Тогда при переполнении справочника требуется только его переделка, что вызывает меньше накладных расходов.
Чтобы избежать потребности полной переделки справочников, при их организации часто используют технику B-деревьев с расщеплениями и слияниями. Хэш-функция при этом меняется динамически, в зависимости от глубины B-дерева. Путем дополнительных технических ухищрений удается добиться сохранения порядка записей в соответствии со значениями ключа.
Достоинства метода:
обращение к данным по значению ключа происходит за одну операцию ввода/вывода;
не нужно создавать никаких дополнительных структур (типа индекса) и тратить память на их хранение.
Недостатки:
количество данных и распределение значений ключа должны быть известны заранее;
записи обычно неупорядочены по значению ключа, что приводит к дополнительным затратам, например, при выполнении сортировки;
сложности подбора хеш-функции.
Журнальная информация. Журнал обычно представляет собой последовательный файл с записями переменного размера, которые можно просматривать в прямом или обратном порядке. Обмены производятся стандартными порциями (страницами) с использованием буфера оперативной памяти. В грамотно организованных системах структура (и тем более смысл) журнальных записей известна только компонентам СУБД, ответственным за журнализацию и восстановление.
Служебная информация. Для корректной работы подсистемы управления данными во внешней памяти необходимо поддерживать информацию, которая используется только этой подсистемой и не видна подсистеме языкового уровня. Набор структур служебной информации зависит от общей организации системы, но обычно требуется поддержание следующих служебных данных:
системные каталоги, описывающие физические свойства объектов БД, например, число атрибутов отношения, их размер и типы данных; описание индексов, определенных для данного отношения и т. д;
описатели свободной и занятой памяти в страницах таблиц, которые требуются для нахождения свободного места при занесении строки.
данные для связывания страниц одной таблицы. Если в одном файле внешней памяти могут располагаться страницы нескольких таблиц (обычно к этому стремятся), то нужно каким-то образом связать страницы одной таблицы. Тривиальный способ использования прямых ссылок между страницами часто приводит к затруднениям при синхронизации транзакций (например, особенно трудно освобождать и заводить новые страницы отношения). Поэтому стараются использовать косвенное связывание страниц с использованием служебных индексов. В частности, известен общий механизм для описания свободной памяти и связывания страниц на основе B-деревьев.