

6. Распределенные системы
Распределенность, возможно, главный признак развития NoSQL баз. С лавинообразным ростом информации в мире и необходимости ее обрабатывать за разумное время встала проблема вертикальной масштабируемости — рост скорости процессора остановился на 3.5 Ггц, скорость чтения с диска также растет тихими темпами, цена мощного сервера всегда больше суммарной цены нескольких простых серверов. В этой ситуации обычные реляционные базы, даже кластеризованные на массиве дисков, не способны решить проблему скорости, масштабируемости и пропускной способности. Единственный выход из ситуации - горизонтальное масштабирование, когда несколько независимых серверов соединяются быстрой сетью и каждый владеет/обрабатывает только часть данных и/или только часть запросов на чтение-обновление. В такой архитектуре для повышения мощности хранилища (емкости, времени отклика, пропускной способности) необходимо лишь добавить новый сервер в кластер — и все. Процедурами шардинга, репликации, обеспечением отказоустойчивости (результат будет получен даже если одна или несколько серверов перестали отвечать), перераспределения данных в случае добавления ноды занимается сама NoSQL база.
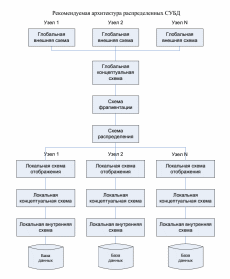
Под распределенной базой данных понимается набор логически связанных между собой разделяемых данных, которые физически распределены по разных узлам компьютерной сети.
Распределенная СУБД в таком случае предназначена для управления распределенной БД и позволяет сделать распределенность прозрачной для конечного пользователя. Прозрачность распределенной БД заключается в том, что с точки зрения конечного пользователя она должна вести себя точно также, как централизованная.
Логически единая БД разделяется на фрагменты, каждый из которых хранится на одном компьютере, а все компьютеры соединены линиями связи. Каждый из этих фрагментов работает под управлением своей СУБД.
Варианты организации архитектуры клиент-сервер в распределенных БД:

Рисунок
Критерии (правила) распределенности были сформулированы К. Дейтом еще в 1987 году, основой всех критериев является то, что распределенная БД для конечного пользователя должна быть неотличима от привычной централизованной БД.
1.Локальная автономия. Это качество означает, что управление данными на каждом из узлов распределенной системы выполняется локально. База данных, расположенная на одном из узлов, является неотъемлемым компонентом распределенной системы. Будучи фрагментом общего пространства данных, она в то же время функционирует как полноценная локальная база данных, а управление ею осуществляется локально, независимо от других узлов системы.
2.Независимость узлов. Все узлы равноправны и независимы, а расположенные на них БД являются равноправными поставщиками данных в общее пространство данных. База данных на каждом из узлов самодостаточна – она включает полный собственный словарь данных и полностью защищена от несанкционированного доступа.
3.Непрерывность операций. Это возможность непрерывного доступа к данным в рамках распределенной БД вне зависимости от их расположения и вне зависимости от операций, выполняемых на локальных узлах.
4.Прозрачность расположения. Пользователь, обращающийся к БД, ничего не должен знать о реальном, физическом размещении данных в узлах информационной системы.
5.Прозрачная фрагментация. Возможность распределенного (т. е. на различных узлах) размещения данных, логически представляющих собой единое целое.
6.Прозрачное тиражирование. Тиражирование данных – это асинхронный процесс переноса изменений объектов исходной базы данных в базы, расположенные на других узлах распределенной системы.
7.Обработка распределенных запросов. Возможность выполнения операций выборки данных из распределенной БД, посредством запросов, сформулированных на языке SQL.
8.Обработка распределенных транзакций. Возможность выполнения операций обновления распределенной базы данных, не нарушающих целостность и согласованность данных. Эта цель достигается применением двухфазного протокола фиксации транзакций.
9.Независимость от оборудования. Это свойство означает, что в качестве узлов распределенной системы могут выступать компьютеры любых моделей и производителей.
10. Независимость от операционных систем. Это качество вытекает из предыдущего и означает многообразие операционных систем, управляющих узлами распределенной системы.
11. Прозрачность сети. Доступ к любым базам данных осуществляется по сети. Спектр поддерживаемых конкретной СУБД сетевых протоколов не должен быть ограничением системы, основанной на распределенной БД.
12. Независимость от СУБД. Это качество означает, что в распределенной системе могут работать СУБД различных производителей, и возможны операции поиска и обновления в базах данных различных моделей и форматов.
Преимущества и недостатки распределенных БД:
Таблица
Преимущества |
Недостатки |
Отражение структуры организации |
Повышение сложности |
Разделяемость и локальная автономность |
Увеличение стоимости |
Повышение доступности данных |
Проблемы защиты |
Повышение надежности |
Усложнение контроля за целостностью данных |
Экономические выгоды |
Недостаток опыта |
Повышение производительности |
Отсутствие стандартов |
Усложнение процедуры разработки базы данных |
Модульность системы |
Дополнительные функции реляционных СУБД:
Расширенные службы установки соединений для передачи данных между узлами сети.
Расширенные средства ведения каталога, позволяющие сохранить сведения о распределении объектов БД в сети.
Средства обработки распределенных запросов, включающиемеханизмы оптимизации и организации удаленного доступа.
Функции, поддерживающие целостность реплицируемых данных.
Расширенные функции восстановления, учитывающие возможности отказов в других узлах сети или линиях связи.
Рисунок
Методы поддержки распределенных данных
Существуют различные методы поддержки распределенности:
1. Репликация – создание и хранение копий одних и тех же данных на разных узлах распределенной БД или копирование данных на другие узлы при обновлении. Позволяет как добиться большей масштабируемости, так и повысить доступность и сохранность данных.
Репликация – это поддержание двух и более идентичных копий (реплик) данных на разных узлах распределенной БД. Реплика может включать всю базу данных (полная репликация), одноь или несколько взаимосвязанных отношений или фрагмент отношения.
Достоинства репликации:
– повышение доступности и надежности данных;
– повышение локализации ссылок на реплицируемые данные.
Недостатки репликации:
– сложность поддержания идентичности реплик;
– увеличение объема памяти для хранения данных.
Поддержание идентичности реплик называется распространение изменений и реализуется службой тиражирования.
Служба тиражирования должна выполнять следующие функции:
Обеспечение масштабируемости, т.е. эффективной обработки больших и малых объемов данных.
Преобразование типов и моделей данных (для гетерогенных распределенных БД).
Репликация объектов БД, например, индексов, триггеров и т.п.
Инициализация вновь создаваемой реплики.
Обеспечение возможности "подписаться" на существующие реплики, чтобы получать их в определенной периодичностью.
Для выполнения этих функций в языке, поддерживаемом СУБД, предусматривается наличие средств определения схемы репликации, механизма подписки и механизма инициализации реплик (создания и заполнения данными).
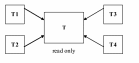
Существуют следующие варианты репликации с основной копией:
1. Классический подход заключается в наличии одной основной копии, в которую можно вносить изменения; остальные копии создаются с определением read only.
2. Асимметричная репликация: основная копия фрагментирована и распределена по разным узлам распределенной БД, и другие узлы могут являться подписчиками отдельных фрагментов (read only).
3. Рабочий поток. При использовании этого подхода право обновления не принадлежит постоянно одной копии, а переходит от одной копии в другой в соответствии с потоком операций. В каждый момент времени обновляться может только одна копия.
4. Консолидация данных:
Рисунок
Способы реализации распространения изменений:
1. Выгрузка (дамп) и повторная загрузка. Данные извлекаются из единственного источника и загружаются в один или более приемников.
Недостатки:
Время между появлением новых данных и их распространением может измеряться часами, днями и более длительными периодами.
Этот подход обеспечивает одностороннюю репликацию без своевременного удаленного обновления.
2. Снимки (snapshot). В определенные моменты времени делаются снимки базы данных, которые затем загружаются в один или более серверов-приемников. Достоинство этого метода – простота реализации. Недостатки:
Получатели работают с относительно устаревшими данными, что делает данный подход неприемлемым в случаях, когда требуется информация в реальном времени.
Этот способ не обеспечивает удаленного обновления.
Симметричная репликация (без основной копии). Все копии реплицируемого набора могут обновляться одновременно и независимо друг от друга, но все изменения одной копии должны попасть во все остальные копии.
Существует два основных механизма распространения изменений при симметричной репликации:
синхронный: изменения во все копии вносятся в рамках одной транзакции;
асинхронный: подразумевает отложенный характер внесения изменений в удаленные копии.
Достоинство синхронного распространения изменений – полная согласованность копий и отсутствие конфликтов обновления.
Недостатки – трудоемкость и большая длительность модификации данных, низкая надежность работы системы.
При симметричной репликации бывают кследующие конфликтные ситуации:
Добавление двух записей с одинаковыми первичными или уникальными ключами. Для предотвращения таких ситуаций обычно каждому узлу распределенной БД выделяется свой диапазон значений ключевых (уникальных) полей.
Конфликты удаления: одна транзакция пытается удалить запись, которая в другой копии уже удалена другой транзакцией. Если такая ситуация считается конфликтом, то она разрешаются вручную.
Конфликты обновления: две транзакции в разных копиях обновили одну и ту же запись, возможно, по-разному, и пытаются распространить свои изменения. Для идентификации конфликтов обновления необходимо передавать с транзакцией дополнительную информацию: старое и новое содержимое записи. Если старая запись не может быть обнаружена, налицо конфликт обновления.
Методы разрешения конфликтов обновления:
Разрешение по приоритету узлов: для каждого узла назначается приоритет, и к записи применяется обновление, поступившее с узла с максимальным приоритетом.
Разрешение по временной отметке: все транзакции имеют временную отметку, и к записи применяется обновление с минимальной или максимальной отметкой. Использовать ли для этого минимальную или максимальную отметку – зависит от предметной области и, обычно, может регулироваться.
Аддитивный метод (add – добавить): может применяться в тех случаях, когда изменения основаны на предыдущем значении поля, например, salary = salary + X. При этом к значению поля последовательно применяются все обновления.
Использование пользовательских процедур.
Разрешение конфликтов вручную. Сведения о конфликте записываются в журнал ошибок для последующего анализа и устранения администратором.
Способы реализации распространения изменений:
а). Использование триггеров. Внутрь триггера помещаются команды, проводящие на других копиях обновления, аналогичные тем, которые вызвали выполнение триггера.
Этот подход достаточно гибкий, но он обладает рядом недостатков:
триггеры создают дополнительную нагрузку на систему;
триггеры не могут выполняться по графику (время срабатывания триггера не определено);
с помощью триггеров сложнее организовать групповое обновление связанных таблиц (из-за проблемы мутирующих таблиц).
б). Поддержка журналов изменений для реплицируемых данных. Рассылка этих изменений входит в задачу сервера СУБД или сервера тиражирования (входящего в состав СУБД). Основные принципы, которых необходимо придерживаться при этом:
Для сохранения согласованности данных должен соблюдаться порядок внесения изменений.
Информация об изменениях должна сохраняться в журнале до тех пор, пока не будут обновлены все копии этих данных.
2. Фрагментация (шардинг) – основной способ организации распределенной БД, предназначенный для хранения данных на том узле, где они чаще используются, представляет собой разбиение БД или таблицы на несколько частей и хранение этих частей на разных узлах распределенной БД. Шардинг часто использовался как «костыль» к реляционным базам данных в целях увеличения скорости и пропускной способности: пользовательское приложение партиционировало данные по нескольким независимым базам данных и при запросе соответствующих данных пользователем обращалось к конкретной базе. В NoSQL базах данных шардинг, как и репликация, производятся автоматически самой СУБД и пользовательское приложение обособленно от этих сложных механизмов.
Основные проблемы, которые возникают при фрагментировании:
– прозрачность написания запросов к данным;
– поддержка распределенных ограничений целостности.
Схема фрагментации отношения должна удовлетворять трем условиям:
Полнота: если отношение R разбивается на фрагменты R1, R2,…, Rn, то URi = R , т.е каждый кортеж должен входить хотя бы в один фрагмент.
Восстановимость: должна существовать операция реляционной алгебры, позволяющая восстановить отношение R из его фрагментов. Это правило гарантирует сохранение функциональных зависимостей.
Непересекаемость: если элемент данных dj ϵ Ri, то он не должен присутствовать одновременно в других фрагментах. Исключение составляет первичный ключ при вертикальной фрагментации. Это правило гарантирует минимальную избыточность данных
Типы фрагментации:
а) горизонтальная;
б) вертикальная;
в) смешанная;
г) производная.
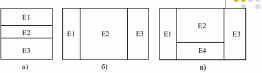
Производная фрагментация строится для подчиненного отношения на основе фрагментов родительского отношения. Например, для фрагментов отношения Emp (сотрудники) Ei подчиненное отношение "Дети" (Child), информацию о которых также целесообразно хранить в соответствующих узлах, имеет смысл разбить на три горизонтальных фрагмента.
Также существуют способы фрагментации БД по ключу, по интервалу значений и по каталогу.
3. Распределенные ограничения целостности – ограничения, для проверки выполнения которых требуется обращение к другому узлу распределенной БД.
Распределенные ограничения целостности возникают тогда, когда для проверки соблюдения какого-либо ограничения целостности системе необходимо обратиться к другому узлу. Например:
1) База данных разделена на фрагменты таким образом, что родительская таблица находится на одном узле, а дочерняя, связанная с ней по внешнему ключу, – на другом. При добавлении записи в дочернюю таблицу система обратится к узлу, на котором расположена родительская таблица, для проверки наличия соответствующего значения ключа.
2) Разбиение одной таблицы на фрагменты и размещение этих фрагментов по разным узлам сети. Здесь будет необходима проверка соблюдения ограничений первичного ключа и уникальных ключей.
4. Распределенные запросы – это запросы на чтение, обращающиеся более чем к одному узлу распределенной БД.
Распределенным называется запрос, который обращается к двум и более узлам распределенной БД, но не обновляет на них данные. Запрашивающий узел должен определить, что в запросе идет обращение к данным на другом узле, выделить подзапрос к удаленному узлу и перенаправить его этому узлу.
Самой сложной проблемой выполнения распределенных запросов является оптимизация, т.е. поиск оптимального плана выполнения запроса. Информация, которая требуется для оптимизации запроса, распределена по узлам. Если выбрать центральный узел, который соберет эту информацию, построит оптимальный план и отправит его на выполнение, то теряется свойство локальной автономности. Поэтому обычно распределенный запрос выполняется так: запрашивающий узел собирает все данные, полученные в результате выполнения подзапросов, у себя, и выполняет их соединение (или объединение), что может занять очень много времени.
5. Распределенные транзакции – команды на изменение данных, обращающиеся более чем к одному узлу распределенной БД.
Распределенные транзакции обращаются к двум и более узлам и обновляют на них данные. Основная проблема распределенных транзакций – соблюдение логической целостности данных. Транзакция на всех узлах должна завершиться одинаково: или фиксацией, или откатом.
Выполнение распределенных транзакций осуществляется с помощью специального алгоритма, который называется двухфазная фиксация, в которой участвует координатор транзакции – узел, который контролирует выполнение этого протокола (обычно, тот узел, который инициирует данную транзакцию) и все остальные узлы, на которых выполняется транзакция, называются участниками транзакции.
CAP теорема
Эта теорема была представлена на симпозиуме по принципам распределенных вычислений в 2000 году Эриком Брюером. В 2002 году Сет Гилберт и Нэнси Линч из MIT опубликовали формальное доказательство гипотезы Брюера, сделав ее теоремой.
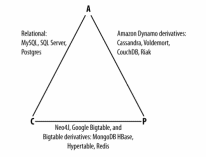
В CAP говорится, что в распределенной системе возможно выбрать и выполнить только два из следующих трех свойств:
C (consistency) — согласованность. Каждое чтение даст вам самую последнюю запись.
A (availability) — доступность. Каждый узел (не упавший) всегда успешно выполняет запросы (на чтение и запись).
P (partition tolerance) — устойчивость к распределению. Даже если между узлами нет связи, они продолжают работать независимо друг от друга.
На практике для наглядности рассматривается как треугольник:
Рисунок
Основные виды NoSQL БД
Существует довольно много различных моделей и функциональных систем для NoSQL баз данных. Самые востребованные и известные:
1. СУБД типа «ключ-значение» – это Redis (БД в оперативной памяти (IMDB) с дополнительной отказоустойчивостью), Riak (распределенное, репликационное хранилище), MemcacheDB и т.д.
2. Колоночные СУБД (Column-oriented) – Cassandra (структура данных основана на BigTable и DynamoDB), HBase(хранилище для Apache Hadoop основанное на принципах BigTable) и т.д (предназначены для очень больших объёмов данных).
3. Документо-ориентированные СУБД – MongoDB, CouchDB, Couchbase (основанное на JSON, совместимое c Memcached хранилище) и т.д. (предназначены для хранения иерархических структур данных - документов)
4. СУБД на основе графов – OrientDB, Neo4J (безсхемное, очень мощное и популярное хранилище написанное на Java) и т.д.
Базы данных «ключ-значение»
База данных на основе пар «ключ‑значение» – это тип нереляционных баз данных, в котором для хранения данных используется простой метод пар «ключ‑значение», который хранит данные как совокупность пар «ключ‑значение», в которых ключ служит уникальным идентификатором. Как ключи, так и значения могут представлять собой практически что угодно: от простых до сложных составных объектов. Например, объектом данных может быть словарь – особый тип данных, который представляет собой массив коллекций с различными ключами и соответствующими им значениями, где нет места ни структуре, ни связям или это может быть JSON-объект, изображение или текст. Чтобы запросить данные, через приложение к БД отправляется ключ и в ответ будет получен blob-объект.

Рисунок
Рассмотрим СУБД Amazon DynamoDB. Это нереляционная база данных, обеспечивающая надежную производительность при любом масштабе, является полностью управляемой и работает в нескольких регионах с несколькими ведущими серверами. Она обеспечивает устойчивую задержку в пределах нескольких миллисекунд и обладает встроенными средствами безопасности, резервного копирования и восстановления, а также кэширования в памяти. В DynamoDB каждый элемент структуры состоит из первичного или сложного ключа и переменного количества атрибутов. Явно заданных ограничений по количеству атрибутов, связанных с отдельным элементом, не существует, однако суммарный размер, включая все имена и значения атрибутов, не должен превышать 400 КБ. Таблица представляет собой совокупность элементов данных, подобную совокупности строк в таблице реляционной базы данных и может содержать бесконечное количество элементов данных.
На диаграмме показан пример данных, хранящихся в виде пар «ключ‑значение» в DynamoDB.
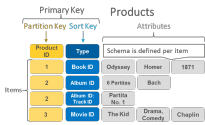
Рисунок
Ниже приведены примеры практического использования базы данных «ключ-значение».
Хранилище сессий. Основанное на сессиях приложение (например, интернет‑приложение) запускает сессию, когда пользователь входит в систему. Оно активно до тех пор, пока пользователь не выйдет из системы или не истечет время сессии. В течение этого периода приложение хранит все связанные с сессией данные либо в основной памяти, либо в базе данных. Данные сессии могут включать информацию профиля пользователя, сообщения, индивидуальные данные и темы, рекомендации, таргетированные рекламные кампании и скидки. Каждая сессия пользователя имеет уникальный идентификатор. Данные сессий всегда запрашиваются только по первичному ключу, поэтому для их хранения отлично подходит быстрое хранилище пар «ключ‑значение».
Корзина интернет‑магазина. Во время праздничного сезона покупок сайт интернет‑магазина может получать миллиарды заказов за считаные секунды. Используя базы данных на основе пар «ключ‑значение», можно обеспечить необходимое масштабирование при существенном увеличении объемов данных и чрезвычайно интенсивных изменениях состояния. Такие базы данных позволяют одновременно обслуживать миллионы пользователей благодаря распределенным обработке и хранению данных. Базы данных на основе пар «ключ‑значение» также обладают встроенной избыточностью, что позволяет справляться с потерей узлов хранилища.
Таким образом, для базы данных «ключ-значение» характерны следующие утверждения:
поддерживают высокую разделяемость и обеспечивают беспрецедентное горизонтальное масштабирование, недостижимое при использовании других типов БД. Для этого, например, СУБД может автоматически выделять дополнительные разделы на таблицу, если существующий раздел заполняется до предела и требуется больше пространства для хранения.
обеспечивают быстрый и малозатратный доступ;
часто хранят данные конфигураций и информацию о состоянии данных, представленных словарями или хэшем;
не имеют жёсткой схемы отношения между данными, поэтому в таких БД часто хранят одновременно различные типы данных;
разработчик отвечает за определение схемы именования ключей и за то, чтобы значение имело соответствующий тип/формат.
Самые известные СУБД «ключ-значение»: Redis, Memcached, ETCD, Amazon DynamoDB.
Документо-ориентированные хранилища
Документо-ориентированые хранилища или документные БД очень быстро захватили свой рынок. Они работают так же, как и предыдущие системы, но допускают гораздо большую вложенность и сложность структуры данных (например, документ вложенный в документ, вложенный в документ). Документы снимают ограничения вложенности первого и второго уровней типа ключ-значение в распределённых хранилищах. В целом, можно описать сколь угодно сложную структуру данных как документ и сохранить в такой БД.
Несмотря на довольно большой функционал и способность доступа к данным по одному ключу, такие СУБД имеют ряд своих проблем. Например, при доступе к одному документу он полностью возвращается в ответ на запрос, даже если необходимо какое-то одно поле, что не может не сказаться на производительности.
Такие БД также используют ключ для уникальной идентификации данных. Разница между хранилищами «ключ-значение» и документными БД заключается в том, что вместо хранения blob-объектов, документоориентированные базы хранят данные в структурированных форматах – JSON, BSON или XML.
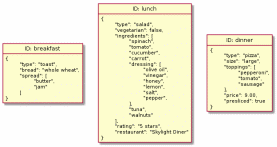
Рисунок
Рассмотрим подробнее документную БД MongoDB. Это тип нереляционных баз данных, предназначенный для хранения и поиска данных в виде документов в формате, подобном JSON. Всю модель устройства базы данных в MongoDB можно представить следующим образом:

Рисунок
 Если
в реляционных БД содержимое составляют
таблицы, то в MongoDB база данных состоит
из коллекций.
Если
в реляционных БД содержимое составляют
таблицы, то в MongoDB база данных состоит
из коллекций.
Каждая коллекция имеет свое уникальное имя - произвольный идентификатор, состоящий из не более чем 128 различных алфавитно-цифровых символов и знака подчеркивания.
В отличие от реляционных баз данных MongoDB не использует табличное устройство с четко заданным количеством столбцов и типов данных, а является документо-ориентированной системой, в которой центральным понятием является документ.
Документ можно представить как объект, хранящий некоторую информацию. В некотором смысле он подобен строкам в реляционных СУБД, где строки хранят информацию об отдельном элементе. Например, типичный документ:
1 2 3 4 5 6 7 8 9 10 |
{ "name": "Bill", "surname": "Gates", "age": "48", "company": { "name" : "microsoft", "year" : "1974", "price" : "300000" } } |
Документ представляет набор пар ключ-значение. Например, в выражении "name": "Bill" name представляет ключ, а Bill - значение.
Ключи представляют строки. Значения же могут различаться по типу данных. В данном случае почти все значения также представляют строковый тип, и лишь один ключ (company) ссылается на отдельный объект. Существуют следующие типы значений:
String: строковый тип данных (для строк используется кодировка UTF-8);
Array (массив): тип данных для хранения массивов элементов;
Binary data (двоичные данные): тип для хранения данных в бинарном формате;
Boolean: булевый тип данных, хранящий логические значения TRUE или FALSE, например, {"married": FALSE};
Date: хранит дату в формате времени Unix;
Double: числовой тип данных для хранения чисел с плавающей точкой;
Integer: используется для хранения целочисленных значений, например, {"age": 29};
JavaScript: тип данных для хранения кода javascript;
Min key/Max key: используются для сравнения значений с наименьшим/наибольшим элементов BSON;
Null: тип данных для хранения значения Null;
Object: строковый тип данных, как в приведенном выше примере;
ObjectID: тип данных для хранения id документа;
Regular expression: применяется для хранения регулярных выражений;
Symbol: тип данных, идентичный строковому. Используется преимущественно для тех языков, в которых есть специальные символы;
Timestamp: применяется для хранения времени.
В отличие от строк документы могут содержать разнородную информацию. Так, рядом с документом, описанным выше, в одной коллекции может находиться другой объект, например:
1 2 3 4 5 6 7 8 9 10 |
{ "name": "Tom", "birthday": "1985.06.28", "place" : "Berlin", "languages" :[ "english", "german", "spanish" ] } |
То есть разные объекты за исключением отдельных свойств, могут находиться в одной коллекции.
В MongoDB запросы обладают регистрозависимостью и строгой типизацией. То есть следующие два документа не будут идентичны:
1 2 |
{"age" : "28"} {"age" : 28} |
Если в первом случае для ключа age определена в качестве значения строка, то во втором случае значением является число.
Идентификатор документа. Для каждого документа в MongoDB определен уникальный идентификатор, который называется _id. При добавлении документа в коллекцию данный идентификатор создается автоматически. Однако разработчик может сам явным образом задать идентификатор, а не полагаться на автоматически генерируемые, указав соответствующий ключ и его значение в документе.
Данное поле должно иметь уникальное значение в рамках коллекции. И если добавить в коллекцию два документа с одинаковым идентификатором, то добавится только один из них, а при добавлении второго сгенерируется сообщение об ошибке.
Если идентификатор не задан явно, то MongoDB создает специальное бинарное значение размером 12 байт. Это значение состоит из нескольких сегментов: значение типа timestamp размером 4 байта, идентификатор машины из 3 байт, идентификатор процесса из 2 байт и счетчик из 3 байт. Таким образом, первые 9 байт гарантируют уникальность среди других машин, на которых могут быть реплики базы данных. А следующие 3 байта гарантируют уникальность в течение одной секунды для одного процесса. Такая модель построения идентификатора гарантирует с высокой долей вероятности, что он будет иметь уникальное значение, ведь она позволяет создавать до 16 777 216 уникальных объектов ObjectId в секунду для одного процесса.
Ниже приведены примеры практического использования документо-ориентированных БД.
Управление контентом. Документная база данных – отличный выбор для приложений управления контентом, таких как платформы для блогов и размещения видео. При использовании документной базы данных каждая сущность, отслеживаемая приложением, может храниться как отдельный документ. Документная база данных позволяет разработчику с удобством обновлять приложение при изменении требований. Кроме того, если необходимо изменить модель данных, то требуется обновление только затронутых этим изменением документов. Для внесения изменений нет необходимости обновлять схему и прерывать работу базы данных.
Каталоги. Документные базы данных эффективны для хранения каталожной информации. Например, в приложениях для интернет‑коммерции разные товары обычно имеют различное количество атрибутов. Управление тысячами атрибутов в реляционных базах данных неэффективно. Кроме того, количество атрибутов влияет на производительность чтения. При использовании документной базы данных атрибуты каждого товара можно описать в одном документе, что упрощает управление и повышает скорость чтения. Изменение атрибутов одного товара не повлияет на другие товары.
Таким образом, для документно-ориентированных баз данных характерны следующие утверждения:
Документные базы данных позволяют разработчикам хранить и запрашивать данные в БД с помощью той же документной модели, которую они используют в коде приложения, другими словами БД не предписывает опредёленный формат или схему.
Гибкий, полуструктурированный, иерархический характер документов и документных баз данных, где каждый документ может иметь свою внутреннюю структуру, позволяет БД легко развиваться в соответствии с потребностями приложений.
Документная модель хорошо работает в таких примерах использования, как каталоги, пользовательские профили и системы управления контентом, где каждый документ уникален и изменяется со временем.
Документные базы данных обеспечивают гибкость индексации, производительность выполнения стандартных запросов и аналитику наборов документов.
Документные БД являются хорошим выбором для быстрой разработки, в любой момент позволяют менять свойства данных, не изменяя структуру или сами данные.
Самые известные документо-ориентированные СУБД: MongoDB, RethinkDB, CouchDB, Couchbase, MarkLogic, eXist.
Колоночные базы данных
Колоночные базы данных (хранилища семейств колонок, нереляционные колоночные хранилища или базы данных с широкими столбцами) ‒ это следующий шаг развития БД после СУБД типа «ключ-значение». Начало было положено еще в 90х годах (Sybase IQ), но массово они появились в основном в середине 2000-х. Несмотря на довольно сложную для понимания сущность, эти базы данных отлично работают, создавая коллекции из одного или нескольких пар ключ-значение, которые в сумме соответствуют одной записи.
В отличии от привычных таблиц в реляционных моделях, эти СУБД не требует предварительного описания структуры данных. Каждая запись состоит из одного или нескольких столбцов, содержащих данные, а каждый столбец состоит из разных записей и может хранить разные типы данных. Другими словами, как и реляционные, колоночные БД хранят данные, используя строки и столбцы, но с иной связью между элементами.
В целом, это хранилище ни что иное как двумерный разреженный массив, где каждый ключ (запись) содержит одну или несколько пар ключ-значение привязанных к нему, или другими словами строки и столбцы которого используются как ключи. Такая система позволяет хранить и использовать большие объемы неструктурированных данных. (одна запись с большим количеством дополнительной информации). Такие базы данных обычно используются, когда недостаточно простых пар ключ-значение, а хранить необходимо большой объем записей с различной информацией.
Колоночные БД внешне похожи на реляционные БД, но в реляционных БД все строки должны соответствовать фиксированной схеме, где схема определяет, какие столбцы будут в таблице, типы данных и другие критерии. В колоночных базах вместо таблиц имеются структуры – «колоночные семейства». Семейства содержат строки, каждая из которых определяет собственный формат. Строка состоит из уникального идентификатора, используемого для поиска, за которым следуют наборы имён и значений столбцов.
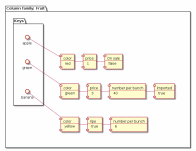
Рисунок
Основная идея колоночных СУБД — это хранение данных не по строкам, как это делают традиционные СУБД, а по колонкам. Это означает, что с точки зрения SQL-клиента данные представлены как обычно в виде таблиц, но физически эти таблицы являются совокупностью колонок, каждая из которых по сути представляет собой таблицу из одного поля. При этом физически на диске значения одного поля хранятся последовательно друг за другом — приблизительно так: [A1, A2, A3], [B1, B2, B3], [C1, C2, C3] и т.д., в отличие от построчного хранения – [A1, B1, C1], [A2, B2, C2], [A3, B3, C3]…, где A, B и С — это поля (столбцы), а 1,2 и 3 — номер записи (строки).
Такая организация данных приводит к тому, что при выполнении запроса, например, в котором фигурируют только 3 поля из 50 полей таблицы, с диска физически будут прочитаны только 3 колонки. Это означает что нагрузка на канал ввода-вывода будет приблизительно в 50/3=17 раз меньше чем при выполнении такого же запроса в традиционной реляционной СУБД.

Рисунок
Кроме того, при поколоночном хранении данных появляется возможность сильно компрессировать данные, так как в одной колонке таблицы данные как правило однотипные, чего не скажешь о строке. Алгоритмы компрессии могут быть разными, например, Run-Length Encoding (RLE) работает так: если есть таблица со 100 млн записей, сделанных в течение одного года, то в колонке «Дата» будет храниться не более 366 возможных значений. Следовательно можно 100 млн отсортированных значений в этом поле заменить на 366 пар значений вида «дата, количество раз» и хранить их на диске в таком виде, что будет занимать приблизительно в 100 тыс. раз меньше места и также способствовать повышению скорости выполнения запросов.
С точки зрения разработчика, колоночные СУБД как правило соответствуют ACID и поддерживают в значительной степени стандарт SQL-99.
Колоночные СУБД призваны решить проблему неэффективной работы традиционных СУБД в аналитических системах класса business intelligence (ROLAP) и аналитических хранилищах данных (data warehouses). Они позволяют на более дешевом и маломощном оборудовании получить прирост скорости выполнения запросов в 5, 10 и иногда даже в 100 раз, при этом, благодаря компрессии, данные будут занимать на диске в 5-10 раз меньше, чем в случае с традиционными СУБД. Причем объемы данных могут быть достаточно большими – есть примеры по 300-500ТБ и даже случаи с >1ПБ данных.
У колоночных СУБД есть и недостатки — они медленно работают на запись, не подходят для транзакционных систем и как правило, имеют ряд ограничений для разработчика, привыкшего к развитым традиционным СУБД.
Типичными сферами применения этого вида СУБД является веб-индексирование, а также задачи, связанные с большими данными, с пониженными требованиями к согласованности данных.
Таким образом, для колоночных баз данных характерны следующие утверждения:
БД удобны при работе с приложениями, требующими высокой производительности;
данные и метаданные записи доступны по одному идентификатору;
гарантировано размещение всех данных из строки в одном кластере, что упрощает сегментацию и масштабирование данных.
Самые известные колоночные СУБД: Sybase IQ, Cassandra, HBase, Vertica, ParAccel, Kognito, Infobright, SAND.
Графовые БД
Базы данных на основе графов в отличие от всех рассмотренных ранее хранят данные в совсем другом виде. Они используют древовидные структуры с узлами и связями, таким образом, можно сказать, что графовая модель сама по себе является наиболее естественным подходом к моделированию. Коме этого, как и в математике, некоторые операции гораздо удобнее выполнять с такими данными благодаря связям между ними и их группировке.
Графовые базы представляют данные в виде отдельных узлов, которые могут иметь любое количество связанных с ними свойств. Вместо сопоставления связей с таблицами и внешними ключами, графовые базы данных устанавливают связи, используя узлы, рёбра и свойства.
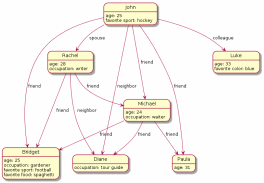
Рисунок
Такие базы данных часто используются в приложениях, где нужно иметь четко установленные связи. Например, когда происходит регистрация в какой-либо социальной сети, хранить связи между вами и вашими друзьями гораздо проще при использовании баз данных на основе графов.
Другой пример – постепенное превращение Интернета из большой «информационной свалки» в большую базу знаний. Чтобы превратить информацию в знания необходимо, хотя и недостаточно, так или иначе связать блоки информации между собой. В начале XXI века Internet сообщество взяло курс на построение Semantic Web (Web 3.0). Напомним вкратце, что
Web 1.0 – это интернет разработчиков, когда основной контент Web представляли простые сайты на основе статических HTML страниц, создаваемых разработчиками;
Web 2.0 – это интернет пользователей, эпоха развития социальных сетей, пользовательских интернет-сервисов, и т.п. – эпоха динамического контента, который на 90% создается пользователями;
Web 3.0 – это «умный» интернет - Semantic Web, когда большая часть контента будет создаваться и использоваться компьютерами. Пользователю и разработчику в Web 3.0 останется лишь самый верхний, сервисный слой.
Наконец, укрупнение и интеграция информационных сервисов, характерные для современного этапа развития корпоративных ИТ, сопровождаются объединением разнородных баз данных в единые комплексы, что весьма затратно реализуется на основе реляционной модели, но практически безболезненно может быть произведено с использованием графовой.
Существует две основных разновидности графовой модели данных: Property Graph и RDF-граф (RDF — Resource Description Framework).
Property Graph – это ориентированный граф, в котором вершины соответствуют «записям», а ребра — «связям» между ними. Дополнительно и ребра, и связи могут быть снабжены скалярными атрибутами.
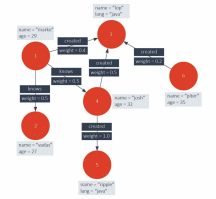
Рисунок
Наиболее известной СУБД, работающей с моделью Property Graph, является Neo4j. В основном, СУБД, работающие с Property Graph, имеют проприетарные интерфейсы и несовместимы друг с другом.
Модель данных RDF еще раньше развивалась в недрах науки искусственного интеллекта (ИИ) как один из способов представления знаний. После 2001 года, когда в журнале Scientific American была опубликована статья знаменитого Тима Бернерса Ли (автора идеи всемирной паутины – World Wide Web), в Internet сообществе стал лавинообразно нарастать интерес к графовым базам, в частности, RDF. В 2004 г. RDF принят как стандарт комитета W3C (World Wide Web Consortium).
RDF – это формат задания графа, представленный в виде троек «субъект – предикат – объект».
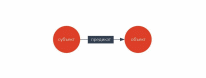
Рисунок
Пример на рисунке ниже показывает тройки, определяющие человека по имени Петр Иванов как автора некоторой статьи в журнале «Вопросы биологии».
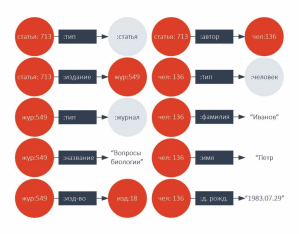
Рисунок
RDF тройки по несложным правилам логически могут быть «упакованы» в граф, изображенный на рисунке ниже.
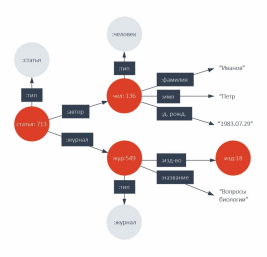
Рисунок
На графе, заданном таким образом, можно делать запросы с помощью специальных языков. Наиболее известный из них — язык, принятый в качестве стандарта W3C –SPARQL. Его синтаксис похож на SQL и имеет декларативную основу.
Например, на графе, фрагмент которого представлен на рисунке выше, можно с помощью SPARQL запроса найти всех авторов, печатавшихся в издательстве «Вопросы биологии», или, например, найти в каких издательствах печатался автор Петр Иванов, родившийся 29 июля 1983 г. и т.д., и т.п.
Что особенно важно, графовая RDF база данных гораздо легче проектируется, управляется и модифицируется, чем аналогичная реляционная база. Поиск сложных связей на этой модели также происходит с гораздо большей эффективностью, поскольку (при правильной архитектуре СУБД) все связи прямые, нет необходимости проводить операцию JOIN через внешние ключи.
Стандартизация RDF. Благодаря усилиям консорциума W3C модель RDF удалось сделать гораздо более стандартизованной, чем это было достигнуто для реляционной модели.
Язык SPARQL гораздо лучше стандартизован, чем SQL. Запросы на SPARQL можно смело посылать разным графовым RDF СУБД, содержащим одинаковые данные, результат будет одинаковым.
RDF стандартизует также идентификацию информации (концепция URI – Universal Resource Identifier).
Стандартизован протокол взаимодействия компонентов (HTTP), точка доступа SPARQL, и т.д.
Есть мнение, что переход от SQL баз данных к RDF системам обещает такой же технологический скачок, как переход от самых первых СУБД к SQL.
Применения графовых СУБД. Можно выделить несколько направлений, в которых применение графовых СУБД наиболее эффективно.
Государственный сектор. Управление процессами, документооборот, аналитика, социологические исследования, и т.д. Клиентами могут быть федеральные и региональные министерства, исследовательские организации, и т.д.
Жизненный цикл предприятий. Интеграция и управление жизненным циклом предприятий в системах автоматизации предприятий. Применение графовых технологий дает возможность единообразно хранить и обрабатывать очень разнородную информацию, включая данные систем ERP, EAM, PLM, САПР и т.д. Клиенты – компании, переходящие на ISO 15926 и другие стандарты на основе RDF, например, Bentley, Siemens, OAK, OCK, Росатом, Роснефть, РАО ЕЭС и т.д.
Маркетинг, реклама, PR. Сбор и анализ разнородной информации из блогов, соцсетей и т.д. для выявления источников информации, предпочтений пользователей; программы лояльности; SEO и т. д.
СМИ. Единая база событий, фактов, компаний, предприятий, журналистов, изданий, статей, сообщений и т.д.
Оборона. АСУ вооруженными силами; системы распределения военной информации; системы планирования войсковых операций; системы анализа и поддержки принятия решений на ТВД; средства автоматизации процессов боевого информационного обеспечения и управления войсками; тренажерные системы; и т.д.
Безопасность. Анализ логов, электронной почты, интернет трафика; финансовый анализ; анализ информации о людях из разных источников, включая данные о работе, собственности, доходах; анализ информации о связях и интересах из социальных сетей; поиск связей по аффилированности и т.д. Возможные клиенты – службы безопасности банков и предприятий, холдингов, корпораций и т.д.
Бизнес-аналитика. Построение аналитических систем нового поколения; построение систем Semantic Data Warehouse — нового класса хранилищ, использующего взаимосвязи данных для повышения качества принятия решений. Клиенты – государственный сектор, банки, предприятия, корпорации, страховые компании и т.д.
Управление сетями и дата-центрами. Управление жизненным циклом вычислительных комплексов, дата-центров, компьютерных и телекоммуникационных сетей и т.д.; моделирование и оптимизация взаимодействия физического, сетевого и других. уровней. Возможные клиенты – дата-центры, Internet провайдеры, службы коммуникаций и кибербезопасности.
Социальные приложения, рекомендационные сервисы и коммерция.
Построение и анализ социальных графов. Применение графовых подходов позволяет выявлять модели аналогичного поведения, групп влияния, неявных групп, и т.д. Возможные клиенты: Компании-разработчики Web-сервисов для более тонкого учета предпочтений клиентов; разработчики приложений для мобильных устройств, Интернет-торговли, форумов и социальных сетей.
Образование. Построение графа взаимосвязей между терминами, понятиями, программами обучения, задачами, тестами, знаниями учащегося и т.д. для построения адаптивных обучающих систем. Клиенты – учебные заведения, провайдеры систем дистанционного обучения.
Геосервисы, геоприложения. Построение взаимосвязей разнородных данных на карте, связанной с людьми, местами и событиями, компаниями, предприятиями и т.д.; решение задач логистики, маршрутизации и т.д. Возможные клиенты –Министерство обороны, МЧС, другие министерства, разработчики социальных приложений и т.д.
Проблемы графовых СУБД. Графовые СУБД в силу своей гибкости и универсальности завоевывает все большее место на рынке. Но широкому их распространению по-прежнему мешает проблема их сравнительно низкой производительности на простых запросах. Таким образом, получается, что графовые СУБД проявляют свои преимущества только при большом количестве связей. Но для типовых современных приложений характерно кол-во связей (операций JOIN в терминах SQL баз) от 2 до 5. То есть, применение графовых СУБД в настоящее время ограничено только сильно связанными данными.
Таким образом, для графовых баз данных характерны следующие утверждения:
представляют наиболее естественный способ моделирования и выглядят аналогично сетевым;
фокусируются на связях между элементами;
явно отображает связи между типами данных;
не требуют пошагового обхода для перемещения между элементами;
нет ограничений в типах представляемых связей.
Самые известные графовые СУБД: Neo4j, JanusGraph, Dgraph, InfiniteGraph, .OrientDB (гетерогенная).
С точки зрения специальности ИТиУТС, невозможно не упомянуть также NOSQL базы данных временны́х рядов, которые созданы для сбора и управления элементами, меняющимися с течением времени. Большинство таких БД организованы в структуры, которые записывают значения для одного элемента. Например, можно создать таблицу для отслеживания температуры процессора. Внутри каждое значение будет состоять из временной метки и показателя температуры. В таблице может быть несколько метрик.
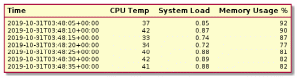
Рисунок
Такие БД ориентированы на запись; предназначены для обработки постоянного потока входных данных; их производительность зависит от количества отслеживаемых элементов, интервала опроса между записью новых значений и фактической полезной нагрузки данных.
Примеры СУБД: OpenTSDB; Prometheus; InfluxDB; TimescaleDB.