

5.7 Моделирование потоков данных (методология Гейна-Сарсона)
Диаграммы потоков данных (DFD Date Flow Diagrams) являются основным средством моделирования функциональных требований проектируемой системы. Эти требования разбиваются на функциональные компоненты (процессы) и представляются в виде сети, связанной потоками данных. Главная цель таких средств – продемонстрировать, как каждый процесс преобразует потоки входных данных в выходные, а также выявить отношения между этими процессами.
Для изображения DFD можно использовать нотации Гейна-Сарсона, Йордана – Де Марко и другие [6, 10].
В соответствии с методологией Гейна-Сарсона модель проектируемой или реально существующей системы определяется как иерархия диаграмм потоков данных, описывающих асинхронный процесс преобразования информации от ее ввода в систему до выдачи пользователю. Диаграммы верхних уровней иерархии (контекстные диаграммы) определяют основные процессы или подсистемы ИС с внешними входами и выходами. Они детализируются при помощи диаграмм нижнего уровня. Такая декомпозиция продолжается, создавая многоуровневую иерархию диаграмм, до тех пор, пока не будет достигнут такой уровень декомпозиции, на котором процесс становятся элементарными и детализировать их далее невозможно.
Источники информации (внешние сущности) порождают информационные потоки (потоки данных), переносящие информацию к подсистемам или процессам. Те в свою очередь преобразуют информацию и порождают новые потоки, которые переносят информацию к другим процессам или подсистемам, накопителям данных или внешним сущностям – потребителям информации. Таким образом, основными компонентами диаграмм потоков данных Гейна-Сарсона являются:
внешние сущности;
системы/подсистемы;
процессы;
накопители данных;
потоки данных.
Внешняя сущность это материальный предмет или физическое лицо, представляющее собой источник или приемник информации, например, заказчики, персонал, поставщики, клиенты, склад. Определение некоторого объекта или системы в качестве внешней сущности указывает на то, что она находится за пределами границ анализируемой ИС. В процессе анализа некоторые внешние сущности могут быть перенесены внутрь диаграммы анализируемой ИС, если это необходимо, или, наоборот, часть процессов ИС может быть вынесена за пределы диаграммы и представлена как внешняя сущность.
Внешняя сущность обозначается квадратом (рис. 34) и располагается как бы «над» диаграммой.
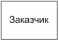
Рис. 34. - Внешняя сущность
При построении модели сложной ИС внешняя сцщность может быть представлена в самом общем виде на так называемой контекстной диаграмме либо может быть декомпозирована на ряд подсистем.
Подсистема (или система) на контекстной диаграмме изображается следующим образом (рис. 35):
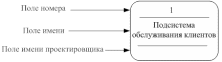
Рис. 35. - Подсистема
Номер подсистемы служит для ее идентификации. В поле имени вводится наименование подсистемы в виде предложения с подлежащим и соответствующими определениями и дополнениями.
Процесс представляет собой преобразование входных потоков данных в выходные в соответствии с определенным алгоритмом. Физически процесс может быть реализован различными способами: это может быть подразделение организации (отдел), выполняющее обработку входных документов и выпуск отчетов, программа, аппаратно реализованное логическое устройство и т.д.
Процесс на диаграмме потоков данных изображается, как показано на рис. 36.
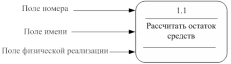
Рис. 36 - Процесс
Номер процесса служит для его идентификации. В поле имени вводится наименование процесса в виде предложения с активным недвусмысленным глаголом в неопределенной форме (вычислить, рассчитать, проверить, определить, создать, получить), за которым следуют существительные в винительном падеже, например: «Ввести сведения о клиентах»; «Выдать информацию о текущих расходах»; «Проверить кредитоспособность клиента».
Использование таких глаголов, как «обработать», «модернизировать» или «отредактировать» означает, как правило, недостаточно глубокое понимание данного процесса и требует дальнейшего анализа.
Информация в поле физической реализации показывает, какое подразделение организации, программа или аппаратное устройство выполняет данный процесс.
Накопитель данных представляет собой абстрактное устройство для хранения информации, которую можно в любой момент поместить в накопитель и через некоторое время извлечь, причем способы помещения и извлечения могут быть любыми.
Накопитель данных может быть реализован физически в виде ящика в картотеке, таблицы в оперативной памяти, файла на магнитном носителе и т.д. Накопитель данных на диаграмме потоков данных изображается, как показано на рис. 37.

Рис. 37. - Накопитель данных
Накопитель данных идентифицируется буквой «D» и произвольным числом. Имя накопителя выбирается из соображения наибольшей информативности для проектировщика.
Накопитель данных в общем случае является прообразом таблицы будущей БД и описание хранящихся в нем данных должно быть увязано с информационной моделью.
Поток данных определяет информацию, передаваемую через некоторое соединение от источника к приемнику. Реальный поток данных может быть информацией, передаваемой по кабелю между двумя устройствами, пересылаемыми по почте письмами, магнитными лентами или дискетами, переносимыми с одного компьютера на другой и т.д.
Поток данных на диаграмме изображается линией, оканчивающейся стрелкой, которая показывает направление потока (рис. 38).

Рис. 38. - Поток данных
Атрибутами потока данных могут быть:
имена и синонимы потоков данных в соответствии с узлами изменения имени;
единицы измерения потоков;
диапазон значений для непрерывного потока;
список значений и их смысл для дискретного потока;
список номеров диаграмм, в которых встречается поток;
комментарии.
Построение диаграммы потоков данных можно условно разбить на несколько этапов [11]:
1. построение контекстной диаграммы;
2. декомпозиция (детализация) процессов;
3. декомпозиция данных.
Первым шагом при построении иерархии DFD является построение контекстной диаграммы. Контекстная диаграмма – это диаграмма верхнего уровня модели, которая отражает интерфейс системы с внешним миром.
Обычно при проектировании относительно простых ИС строится единственная контекстная диаграмма со звездообразной топологией, в центре которой находится так называемый главный процесс, соединенный с приемниками и источниками информации, посредством которых с системой взаимодействуют пользователи и другие внешние системы, например, как на рис. 39:
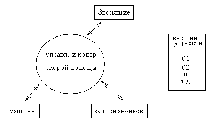
Рис. 39. - Пример контекстной диаграммы
Если же для сложной системы ограничиться единственной контекстной диаграммой, то она будет содержать слишком большое количество источников и приемников информации, которые трудно расположить на листе бумаги нормального формата, и кроме того, единственный главный процесс не раскрывает структуры распределенной системы.
Признаками сложности (в смысле контекста) могут быть:
наличие большого количества внешних сущностей (десять и более);
распределенная природа системы;
многофункциональность системы с уже сложившейся или выявленной группировкой функций в отдельные подсистемы.
Для сложных ИС строится иерархия контекстных диаграмм. При этом контекстная диаграмма верхнего уровня содержит не единственный главный процесс, а набор подсистем, соединенных потоками данных. Контекстные диаграммы следующего уровня детализируют контекст и структуру подсистем.
Иерархия диаграмм определяет взаимодействие основных функциональных подсистем проектируемой ИС как между собой, так и с внешними входными и выходными потоками данных и внешними объектами (источниками и приемниками информации), с которыми взаимодействует ИС.
Разработка контекстных диаграмм решает проблему строгого определения функциональной структуры ИС на самой ранней стадии ее проектирования, что особенно важно для сложных многофункциональных систем, в разработке которых участвуют разные организации и коллективы разработчиков.
После построения контекстной диаграммы полученную модель следует проверить на полноту исходных данных об объектах системы и изолированность объектов (отсутствие информационных связей с другими объектами).
Для каждой подсистемы, присутствующей на контекстной диаграмме, выполняется ее детализация при помощи DFD уровня подсистемы (рис. 40).
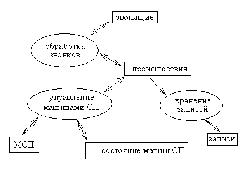
Рис. 40. - Пример детализации основного процесса
Каждый процесс на DFD подсистемы, в свою очередь, может быть детализирован при помощи DFD еще более низкого уровня (рис. 41) или спецификации.
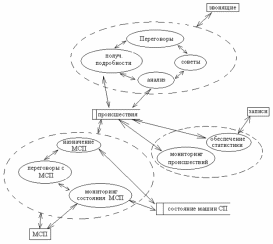
Рис. 41. - Пример дальнейшей детализации основного процесса
При детализации должны выполняться следующие правила:
1. правило балансировки, которое означает, что при детализации подсистемы или процесса детализирующая диаграмма в качестве внешних источников/приемников данных может иметь только те компоненты (подсистемы, процессы, внешние сущности, накопители данных), с которыми имеет информационную связь детализируемая подсистема или процесс на родительской диаграмме;
2. правило нумерации, которое означает, что при детализации процессов должна поддерживаться их иерархическая нумерация. Например, процессы, детализирующие процесс с номером 12, получают номера 12.1, 12.2, 12.3 и т.д.
Для обеспечения декомпозиции данных в DFD могут быть добавлены следующие типы объектов:
1. групповой узел предназначен для расщепления или объединения потоков;
 или
или

Рис. 42. – Групповой узел
2. узел-предок позволяет увязать входящие и выходящие потоки между несколькими уровнями декомпозиции процессов;

Рис. 43. –Узел-предок
3. неиспользуемый узел применяется в ситуации, когда декомпозиция данных производится в групповом узле и при этом требуются не все элементы входящего потока
Рис. 44. – Неиспользуемый узел
4. узел изменения имени позволяет неоднозначно именовать потоки, при том, что их содержимое эквивалентно.

Рис. 45. – Узел изменения имени
5. Текст в свободном формате в любом месте диаграммы.
Спецификация. Конечной точкой иерархии DFD является спецификация. Спецификация (описание логики процесса) должна формулировать его основные функции таким образом, чтобы в дальнейшем специалист, выполняющий реализацию проекта, смог выполнить их или разработать соответствующую программу.
Решение о завершении детализации процесса и использовании спецификации принимается аналитиком исходя из следующих критериев:
наличия у процесса относительно небольшого количества входных и выходных потоков данных (2-3 потока);
возможности описания преобразования данных процессом в виде последовательного алгоритма;
выполнения процессом единственной логической функции преобразования входной информации в выходную;
возможности описания логики процесса при помощи спецификации небольшого объема (не более 20-30 строк).
Итак, спецификация процесса используется для описания функционирования процесса в случае отсутствия необходимости детализировать его с помощью DFD.
Фактически спецификация представляет собой алгоритмы описания задач, выполняемых процессами. Множество всех спецификаций является полной спецификацией системы. Спецификации содержат номер и/или имя процесса, списки входных и выходных данных и тело процесса.
Методы задания спецификации процесса:
текстовое описание;
структурированный естественный язык – является комбинацией строгости языка программирования и читабельности естественного язык и состоит из подмножества слов, организованных в определенные логические структуры, арифметических выражений и диаграмм. Применяется, если детали спецификации известны не полностью, обеспечивает быстрое проектирование, прост в использовании, легок для понимания, но не приспособлен к автоматической кодогенерации из-за наличия неоднозначностей.
таблицы и деревья решений позволяют управлять сложными комбинациями условий и действий, обеспечивают визуальное представление и легко понимаются конечным пользователем, но не обладают процедурными возможностями.
визуальные языки – базируются на основных идеях структурного программирования и позволяют определять потоки управления с помощью специальных иерархически организованных схем. Визуальные языки поддерживают автоматическую кодогенерацию, но вызывают затруднения при модификации спецификации в случае изменения каких-либо деталей.
языки программирования.
При построении иерархии DFD переходить к детализации процессов следует только после определения содержания всех потоков и накопителей данных текущего уровня, которое описывается при помощи структур данных. Структуры данных конструируются из элементов данных и могут содержать альтернативы, условные вхождения и итерации. Условное вхождение означает, что данный компонент может отсутствовать в структуре. Альтернатива означает, что в структуру может входить один из перечисленных элементов. Итерация означает вхождение любого числа элементов в указанном диапазоне. Для каждого элемента данных может указываться его тип (непрерывные или дискретные данные). Для непрерывных данных может указываться единица измерения (кг, см и т.п.), диапазон значений, точность представления и форма физического кодирования. Для дискретных данных может указываться таблица допустимых значений.
После построения законченной модели системы ее необходимо верифицировать (проверить на полноту и согласованность). В полной модели все ее объекты (подсистемы, процессы, потоки данных) должны быть подробно описаны и детализированы. Выявленные не детализированные объекты следует детализировать, вернувшись на предыдущие шаги разработки. В согласованной модели для всех потоков данных и накопителей данных должно выполняться правило сохранения информации: все поступающие куда-либо данные должны быть считаны, а все считываемые данные должны быть записаны.
Таким образом DFD предназначены для:
определения основных функций, потоков и хранилищ данных;
отображения потоков данных и функционального состава системы;
определения связей между функциями;
формирования системных требований.
Главная цель построения иерархического множества DFD заключается в том, чтобы сделать требования ясными и понятными на каждом уровне детализации, а также разбить эти требования на части с точно определенными отношениями между ними. Для достижения этого целесообразно использовать следующие рекомендации:
размещать на каждой диаграмме от 3 до 7 процессов;
не загромождать диаграммы не существенными на данном уровне деталями;
осуществлять параллельно декомпозицию процессов и декомпозицию данных;
выбирать ясные, отражающие суть дела, имена процессов и потоков.
Пример построения модели DFD для системы определения допускаемых скоростей. Построение функциональной модели DFD начинается как и в IDEF0 с разработки контекстной диаграммы. На ней отображается основной процесс (сама система в целом) и ее связи с внешней средой (внешними сущностями). Это взаимодействие показывается через потоки данных. Допускается на контекстной диаграмме отображать сразу несколько основных процессов или подсистем. Пример контекстной диаграммы для рассматриваемой задачи приведен на рис. 46.
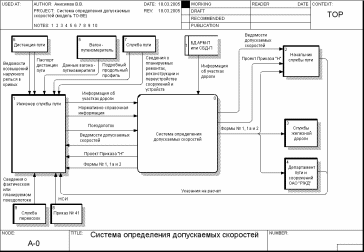
Рис. 46. Контекстная диаграмма системы определения допускаемых скоростей (методология DFD)
На этой диаграмме видно, что в качестве источника исходных данных для работы системы могут использоваться базы данных АРМ-П (АРМ службы пути) или СБД-П (Сводная БД – Путейский фрагмент), содержащие практически всю необходимую информацию по участкам дороги.
В то же время в системе оставлена возможность ее ручного ввода и корректировки. Несмотря на то, что БД АРМ-П или СБД-П по отношению к системе являются внешними сущностями, они, в целях лучшего восприятия, показаны в виде накопителя данных.
Дальнейший процесс проектирования состоит в построении диаграмм декомпозиции, которые строятся (показывают устройство) только для процессов или подсистем (систем).
Диаграмма декомпозиции первого уровня проектируемой системы приведена на рис. 47.
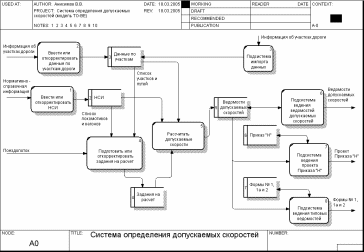
Рис. 47. Диаграмма декомпозиции первого уровня (методология DFD)
На этом рисунке у некоторых потоков данных, связанных с накопителями, отсутствуют имена. Это позволяет устранить дублирование надписей и, как следствие, уменьшить насыщенность диаграммы.
При построении диаграммы декомпозиции блоки системы в одних случаях показаны как процессы (имя начинается с глагола), в других – как подсистемы (имя начинается со слова «подсистема»). Это сделано в целях иллюстрации правил именования блоков. В то же время декомпозицию системы можно было бы представить, либо используя только процессы, либо только подсистемы.
Контекстная диаграмма и диаграмма декомпозиции выполнены с использованием BPwin 4.0.
Модель DFD, помимо описания функционального аспекта системы, содержит также сведения об информационном и компонентном аспектах. Совокупность накопителей данных является прообразом будущей БД, т. е. определяет состав и структуру информации. Построение диаграмм с использованием в качестве блоков подсистем показывает состав и связи компонентов будущей системы.
Расширения DFD для систем реального времени. Системы реального времени построены, как правило, на взаимодействии средств вычислительной техники и различных физических устройств съема информации (датчиков, камер, микрофонов и т. д.). Первые являются дискретными преобразователями информации, вторые в основном – аналоговыми, т. е. генерирующими информацию в виде непрерывного потока. Другой особенностью таких систем является значительный уклон в сторону управления объектами. Для моделирования особенностей поведения систем реального времени П. Вард и С. Меллор предложили использовать на DFD дополнительные элементы.
Квазинепрерывный поток (лат. quasi – как будто, якобы) – поток данных, непрерывный во времени. Отображается линией с двумя стрелками на конце (рис. 48).

Рис. 48. Квазинепрерывный поток
Управляющий процесс – процесс, формирующий сигналы управления на выходе (рис. 49).

Рис. 49. Управляющий процесс
Управляющий поток – управляющая информация, запускающая процесс (подсистему) или изменяющая ход его выполнения (рис. 50).

Рис. 50. Управляющий поток
Использование управляющих потоков позволяет отделить управляющую информацию от обрабатываемой, как это делается на диаграммах IDEF0.
Накопитель управлений – накопитель управляющих потоков (рис. 51).

Рис. 51. Накопитель управления
Выделяют 3 группы управляющих потоков:
Т-поток (tigger flow), который может вызвать выполнение процесса одной короткой операцией;
А-поток (activator flow), может изменять выполнение отдельного процесса, оеспечивает непрерывность выполнения процесса, пока включен.
Е/D-поток (enable-disable flow), может переключать выполнение отдельного процесса, течение по линии Е вызывает выполнение процесса, которое продолжается до тех пор, пока не начинается течение по линии D.
На рис. 52 показан пример использования новых элементов на DFD.

Рис. 52. Фрагмент DFD системы реального времени
Правила и рекомендации построения DFD. Правила и рекомендации построения модели DFD в основном совпадают с принятыми в IDEF0.
По аналогии с IDEF0 у каждого процесса (подсистемы) на диаграмме потоков данных должен быть как минимум один входящий и один выходящий поток. Процесс должен запускаться на выполнение либо через обрабатываемый, либо через управляющий поток данных. Работа каждого процесса должна завершаться конкретным результатом.
Каждый накопитель данных также должен иметь как минимум один входящий и один выходящий поток. Наличие только входящих потоков в накопитель означает, что информация накапливается, но не используется.
Наличие только выходящих потоков из накопителя также является ошибкой. Прежде чем использовать данные из накопителя, они должны там появиться в результате работы какого-либо процесса (подсистемы, внешней сущности). Исключением из правил считается случай, когда накопитель является внешней сущностью. Тогда допускается наличие либо только входящих стрелок, либо только выходящих стрелок
Классические ошибки, возникающие при построении DFD:
1. «черная дыра» процесс имеет только входные потоки данных;
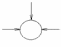
Рис. 53. – «черная дыра»
2. «серая дыра» генерирует выходной поток при недостаточных входных данных;

Рис. 54. – «серая дыра»
3. «белая дыра»наличие только выходных потоков;
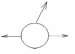
Рис. 55. – «белая дыра»
4. прямая связь двух внешних сущностей или хранилищ (рис. 56);
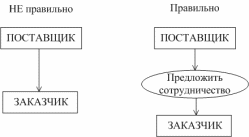
Рис. 56. – Связь внешних сущностей
5. преобразование внешней сущности в хранилище данных (рис. 57) и наоборот.
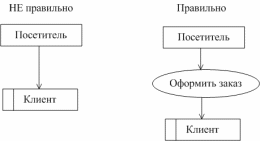
Рис. 57. – Преобразование внешней сущности в хранилище