


230 Параллелизм и конкурентность
МНОГОПОТОЧНОСТЬ
CPython предоставляет как высокоуровневый, так и низкоуровневый API для создания, порождения и управления потоками из Python.
Чтобы понять, как работают потоки Python, необходимо сначала разобраться в потоках операционной системы. В CPython существуют две реализации потоков:
1.pthreads: потоки POSIX для Linux и macOS.
2.nt threads: потоки NT для Windows.
Вразделе «Структура процесса» показано, что процесс обладает следующими характеристиками:
zz Стек подпрограмм. zz Куча памяти.
zz Доступ к файлам, блокировкам и сокетам операционной системы.
Главное ограничение масштабирования одного процесса заключается в том, что операционная система поддерживает один программный счетчик для исполняемого файла.
Для преодоления этого ограничения современные ОС позволяют процессам отправить сигнал операционной системе о необходимости разветвления выполнения на несколько потоков.
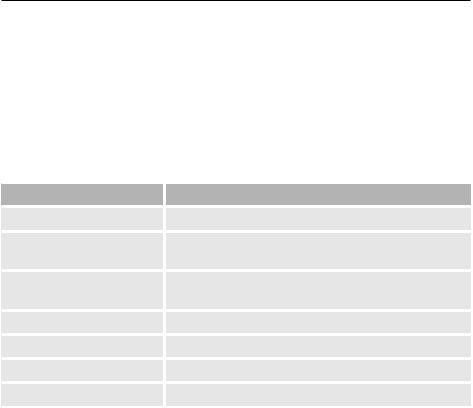
Каждый поток имеет собственный программный счетчик, но использует те же ресурсы, что и управляющий процесс. Также поток имеет собственный стек вызовов, поэтому в них могут выполняться разные функции.
Так как сразу несколько потоков могут выполнять чтение и запись в одно пространство памяти, возможны коллизии. Решение проблемы — обеспечение потокобезопасности; для этого перед обращением к пространству памяти необходимо убедиться, что пространство памяти заблокировано только одним потоком.
Структура одного процесса с тремя потоками выглядит так:
Книги для программистов: https://t.me/booksforits
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Многопоточность 231 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
•• •• |
|
• • |
|
|
|
|||||
|
|
|
|
|
|
|
• •• Python |
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
• • • |
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Python |
|
|
|
|
|
• • •• • |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
1 |
|
2 |
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
• • • |
|
|
|
• • • |
|
|
• • • |
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
СМ. ТАКЖЕ
В качестве вводного урока по потоковому API в Python рекомендуем статью «Intro to Python Threading»1 на сайте Real Python.
GIL
Если вы знакомы с потоками NT или POSIX из C либо если работали на другом высокоуровневом языке, то, вероятно, предполагаете, что многопоточность будет параллельной.
1 https://realpython.com/intro-to-python-threading/.
Книги для программистов: https://t.me/booksforits

232 Параллелизм и конкурентность
В CPython потоки базируются на C API, но являются потоками Python. Это означает, что каждый поток Python должен выполнять байт-код Python через цикл вычисления.
Цикл вычисления Python не является потокобезопасным. Многие компоненты состояния интерпретатора, такие как сборщик мусора, являются глобальными и используются совместно. Чтобы обойти это препятствие, разработчики CPython реализовали мега-блокировку, которая называется
глобальной блокировкой интерпретатора (GIL, Global Interpreter Lock). Перед выполнением любого кода операции в цикле вычисления кадра поток получает блокировку GIL. И хотя такое решение обеспечивает потокобезопасность каждой операции в Python, у него есть один серьезный недостаток. Любые операции, выполнение которых занимает много времени, заставят другие потоки ожидать освобождения GIL, чтобы продолжить работу. Это означает, что в любой конкретный момент времени только один поток может выполнить операцию байт-кода Python.
Для установки GIL вызывается функция take_gil(), а для сбрасывания — функция drop_gil(). Установка GIL осуществляется в основном цикле вычисления кадра, _PyEval_EvalFrameDefault().
Чтобы избежать долговременного удержания GIL при выполнении одного кадра, состояние цикла вычисления содержит флаг gil_drop_request. После завершения каждой операции байт-кода в кадре этот флаг проверяется, и GIL временно сбрасывается перед повторной установкой:
if (_Py_atomic_load_relaxed(&ceval->gil_drop_request)) {
/* Предоставить возможность другому потоку */
if (_PyThreadState_Swap(&runtime->gilstate, NULL) != tstate) { Py_FatalError("ceval: tstate mix-up");
}
drop_gil(ceval, tstate);
/* Теперь другие потоки смогут выполняться */
take_gil(ceval, tstate);
/* Проверить быстрый выход */ exit_thread_if_finalizing(tstate);
if (_PyThreadState_Swap(&runtime->gilstate, tstate) != NULL) { Py_FatalError("ceval: orphan tstate");
}
}
...
Книги для программистов: https://t.me/booksforits
Многопоточность 233
Несмотря на ограничения, которые блокировка GIL накладывает на параллельное выполнение, она делает многопоточность в Python чрезвычайно безопасной и идеально подходящей для одновременного выполнения нескольких задач с интенсивным вводом/выводом.
Исходные файлы
Ниже перечислены исходные файлы, относящиеся к циклу вычисления.
ФАЙЛ |
НАЗНАЧЕНИЕ |
Include pythread.h |
API и определение PyThread |
Lib threading.py |
Высокоуровневый API потоков и модуль стандарт- |
|
ной библиотеки |
Modules _threadmodule.c |
Низкоуровневый API потоков и модуль стандартной |
|
библиотеки |
Python thread.c |
Расширение C для модуля thread |
Python thread_nt.h |
API потоков для Windows |
Python thread_pthread.h |
API потоков для POSIX |
Python ceval_gil.h |
Реализация блокировок GIL |
Запуск потоков в Python
Чтобы продемонстрировать прирост производительности от использования многопоточного кода (несмотря на GIL), мы реализуем простой сетевой сканер портов на Python.
Начнем с клонирования предыдущего скрипта, но изменим логику так, чтобы для каждого порта порождался поток вызовом threading.Thread(). Происходит примерно то же, что в API multiprocessing, где при вызове передается вызываемый объект target и кортеж args.
Потоки будут запускаться в цикле, но мы не будем ожидать их завершения. Вместо этого присоединим экземпляр потока к списку threads:
for port in range(80, 100):
t = Thread(target=check_port, args=(host, port, results)) t.start()
threads.append(t)
Книги для программистов: https://t.me/booksforits

234 Параллелизм и конкурентность
После того как потоки будут созданы, мы перебираем список threads и вызываем .join(), чтобы дождаться их завершения:
for t in threads: t.join()
Затем все элементы в очереди results извлекаются и выводятся на экран:
while not results.empty():
print("Port {0} is open".format(results.get()))
Полный скрипт:
cpython-book-samples 33 portscanner_threads.py
from threading import Thread from queue import Queue import socket
import time
timeout = 1.0
def check_port(host: str, port: int, results: Queue):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.settimeout(timeout)
result = sock.connect_ex((host, port)) if result == 0:
results.put(port)
sock.close()
def main():
start = time.time()
host = "localhost" # Замените вашим хостом threads = []
results = Queue()
for port in range(80, 100):
t = Thread(target=check_port, args=(host, port, results)) t.start()
threads.append(t) for t in threads:
t.join()
while not results.empty():
print("Port {0} is open".format(results.get())) print("Completed scan in {0} seconds".format(time.time() - start))
if __name__ == '__main__': main()
В командной строке этот многопоточный скрипт выполняется в десять раз быстрее однопоточного:
Книги для программистов: https://t.me/booksforits

Многопоточность 235
$ python portscanner_threads.py Port 80 is open
Completed scan in 1.0101029872894287 seconds
Он также выполняется на 50–60 % быстрее многопроцессного скрипта. Не стоит забывать, что многопроцессная обработка сопряжена с определенными затратами на запуск нового процесса. У многопоточных решений затраты тоже есть, но они намного меньше.
Возникает вопрос — если GIL означает, что в любой момент времени выполняться может только одна операция, то почему такое решение работает быстрее?
Следующая команда занимает 1–1000 мс:
result = sock.connect_ex((host, port))
В модуле расширения C Modules socketmodule.c подключение реализуется следующей функцией:
Modules socketmodule.c, строка 3245
static int
internal_connect(PySocketSockObject *s, struct sockaddr *addr, int addrlen, int raise)
{
int res, err, wait_connect;
Py_BEGIN_ALLOW_THREADS
res = connect(s->sock_fd, addr, addrlen);
Py_END_ALLOW_THREADS
Системный вызов connect() заключен между макросами Py_BEGIN_ALLOW_ THREADS и Py_END_ALLOW_THREADS. Макросы определяются в Include ceval.h:
#define Py_BEGIN_ALLOW_THREADS { \
PyThreadState *_save; \ _save = PyEval_SaveThread();
#define Py_BLOCK_THREADS |
PyEval_RestoreThread(_save); |
|
#define |
Py_UNBLOCK_THREADS |
_save = PyEval_SaveThread(); |
#define |
Py_END_ALLOW_THREADS |
PyEval_RestoreThread(_save); \ |
|
} |
|
Таким образом, при выполнении Py_BEGIN_ALLOW_THREADS вызывается PyEval_ SaveThread(). Эта функция изменяет состояние потока на NULL и сбрасывает GIL:
Книги для программистов: https://t.me/booksforits

236 Параллелизм и конкурентность
Python ceval.c, строка 444
PyThreadState * PyEval_SaveThread(void)
{
PyThreadState *tstate = PyThreadState_Swap(NULL); if (tstate == NULL)
Py_FatalError("PyEval_SaveThread: NULL tstate"); assert(gil_created());
drop_gil(tstate); return tstate;
}
Так как GIL сброшен, любой другой выполняемый поток может продолжить выполнение. Этот поток просто будет ожидать системного вызова, не блокируя цикл вычисления.
После того как connect() завершится успешно или по тайм-ауту, макрос
Py_END_ALLOW_THREADS запустит PyEval_RestoreThread() с исходным состоянием потока. Состояние потока восстанавливается, и GIL снова устанавливается. Вызов является блокирующим с ожиданием по семафору:
Python ceval.c, строка 458
void
PyEval_RestoreThread(PyThreadState *tstate)
{
if (tstate == NULL) Py_FatalError("PyEval_RestoreThread: NULL tstate");
assert(gil_created());
int err = errno; take_gil(tstate);
/* _Py_Finalizing защищается GIL */
if (_Py_IsFinalizing() && !_Py_CURRENTLY_FINALIZING(tstate)) { drop_gil(tstate);
PyThread_exit_thread();
Py_UNREACHABLE();
}
errno = err;
PyThreadState_Swap(tstate);
}
Книги для программистов: https://t.me/booksforits

Многопоточность 237
Это не единственный системный вызов, который заключается между макросами Py_BEGIN_ALLOW_THREADS и Py_END_ALLOW_THREADS, управляющими блокированием потоков. В стандартной библиотеке эти макросы используются более трехсот раз, включая следующие области:
zz Отправка HTTP-запросов.
zz Взаимодействие с локальным оборудованием. zz Шифрование данных.
zz Чтение и запись файлов.
Состояние потока
В CPython есть собственная реализация управления потоками. Так как потоки должны выполнять байт-код Python в цикле вычисления, выполнение потока в CPython не сводится к простому порождению потока операционной системы.
Потоки Python называются PyThread, они были кратко рассмотрены в главе «Цикл вычислений CPython».
Потоки Python выполняют объекты кода и порождаются интерпретатором.
Краткое напоминание:
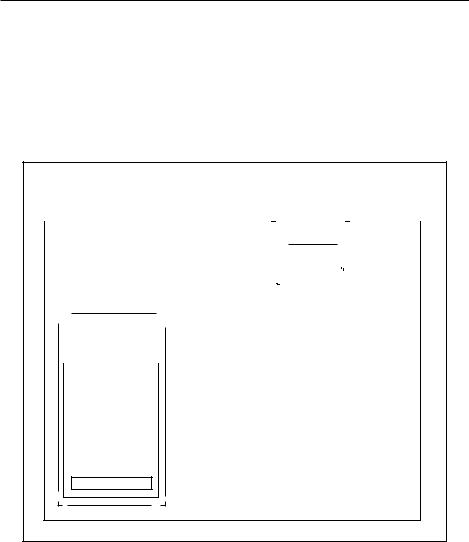
zz CPython использует единую среду выполнения, которая обладает собственным состоянием выполнения.
zz CPython может иметь один или несколько интерпретаторов.
zz Интерпретатор обладает состоянием, которое называется состоянием интерпретатора.
zz Интерпретатор получает объект кода и преобразует его в серию объектов кадров.
zz Интерпретатор содержит хотя бы один поток, и каждый поток обладает
состоянием потока.
zz Объекты кадров выполняются в стеке, который называется стеком кадров.
Книги для программистов: https://t.me/booksforits
238 Параллелизм и конкурентность
zz CPython обращается к переменным в стеке значений.
zz Состояние интерпретатора включает связанный список всех его потоков.
Однопоточная среда выполнения с единственным интерпретатором будет обладать следующими состояниями:
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
GIL |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 ( ) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
•• |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
PyThread |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
ID |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
† ‡ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
ˆ ‰ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
‡‰ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
‰ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
…
Структура данных состояния потока PyThreadState содержит более тридцати свойств, включая следующие:
zz уникальный идентификатор;
zz связанный список с другими состояниями;
Книги для программистов: https://t.me/booksforits

Многопоточность 239
zz состояние интерпретатора, которым был порожден поток; zz выполняемый кадр;
zz текущая глубина рекурсии;
zz необязательные функции трассировки; zz обрабатываемое исключение;
zz обрабатываемое асинхронное исключение; zz стек выданных исключений;
zz счетчик GIL;
zz счетчики асинхронного генератора.
По аналогии с многопроцессными подготовительными данными потоки обладают состоянием инициализации. Однако поскольку они используют общее пространство памяти, необходимость в сериализации и передаче данных через файловый поток отсутствует.
Потоки создаются как экземпляры типа threading.Thread. Это высокоуровневый модуль, абстрагирующий тип данных PyThread. Экземплярами PyThread управляет модуль расширения С _thread.
Модуль _thread содержит точку входа для запуска нового потока, thread_ PyThread_start_new_thread(). start_new_thread() — метод для экземпляра типа Thread.
Новые экземпляры потоков создаются по следующей схеме:
1.Создается состояние инициализации bootstate, связанное с target, с аргументами args и kwargs.
2.bootstate связывается с состоянием интерпретатора.
3.Создается новый экземпляр PyThreadState, связанный с текущим интерпретатором.
4.Вызывается PyEval_InitThreads() для включения блокировки GIL (если она не была включена ранее).
5.Запускается новый поток на основе подходящей для ОС реализации
PyThread_start_new_thread.
Книги для программистов: https://t.me/booksforits
240 |
|
Параллелизм и конкурентность |
|
|
|
|
|
|
|
- † |
|
|
|
|
|
|
|
|
|
|
|
‡ |
‰ |
|
|
|
|
„ |
|
|
|
|
|
|
|
|
|
|
|
„ |
‡ |
|
|
GIL |
|
ˆ-„ |
|
|
|
0 ( ) |
|
1 (€) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PyThread |
|
PyThread |
|
|
|
ID |
ID |
|
|
|
|
|
|
||
|
|
- |
|
- |
|
|
|
€‚ |
|
€‚ |
|
|
|
ƒ„… |
|
ƒ„… |
|
|
|
-„‚… † |
|
-„‚… † |
|
|
|
- -„… |
|
- -„… |
|
|
|
… |
|
… |
|
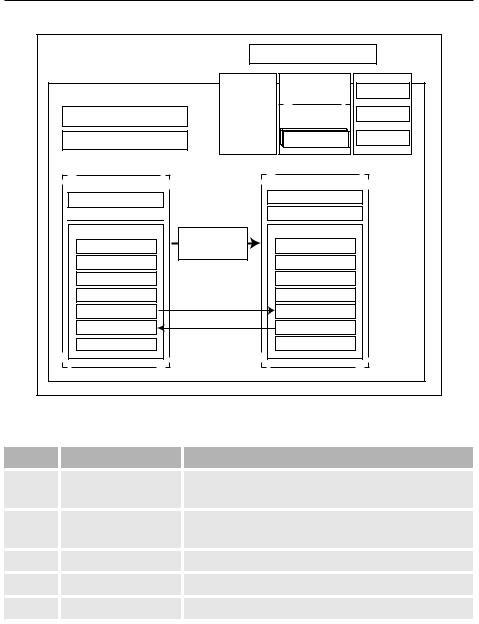
Экземпляр bootstate потока содержит следующие свойства.
ПОЛЕ |
ТИП |
НАЗНАЧЕНИЕ |
interp |
PyInterpreterState* |
Ссылка на интерпретатор, управляющий этим по- |
|
|
током |
func |
PyObject * (callable) |
Ссылка на объект (callable), вызываемый при за- |
|
|
пуске потока |
args |
PyObject * (tuple) |
Аргументы для вызова func |
keyw |
PyObject * (dict) |
Именованные аргументы для вызова func |
tstate |
PyThreadState * |
Состояние потока для нового потока |
Сbootstate используются две реализации PyThread:
1.Потоки POSIX для Linux и macOS.
2.Потоки NT для Windows.
Книги для программистов: https://t.me/booksforits
Многопоточность 241
Обе реализации создают поток операционной системы, устанавливают его атрибут, после чего делают обратный вызов t_bootstrap() из нового потока.
Функция вызывается с одним аргументом boot_raw, которому присваивается экземпляр bootstate, сконструированный в _PyThread_start_new_thread().
Функция t_bootstrap() становится интерфейсом между низкоуровневым потоком и средой выполнения Python. Она инициализирует поток, а затем выполняет цель (target) с помощью вызова PyObject_Call().
После выполнения цели происходит выход из потока:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PyThread |
|
|
- |
|
|
|
t_bootstrap |
|
PyObject_Call |
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Потоки POSIX
Реализация потоков POSIX (pthread) находится в файле Python thread_ pthread.h. Эта реализация абстрагирует C API <pthread.h> с дополнительными защитными мерами и оптимизациями.
Размер стека потоков может настраиваться. Python содержит собственную конструкцию кадра стека, как было показано в главе о цикле вычисления. Если в цикле возникнет рекурсия и выполнение кадра достигнет предельной глубины, Python выдаст ошибку RecursionError, которую можно обработать блоком try...except в Python-коде.
Так как потоки pthread имеют собственный размер стека, возможен конфликт между максимальной глубиной рекурсии Python и размером стека pthread. Если размер стека потока меньше максимальной глубины кадра в Python, то весь процесс Python аварийно завершится до того, как будет выдана ошибка
RecursionError.
Максимальная глубина в Python может настраиваться во время выполнения вызовом sys.setrecursionlimit(). Для предотвращения сбоев реализация pthread в CPython задает в качестве размера стека значение pythread_stacksize из состояния интерпретатора.
Многие современные POSIX-совместимые операционные системы поддерживают системное планирование потоков pthread. Если в pyconfig.h определено
Книги для программистов: https://t.me/booksforits