

66 Грамматика и язык Python
Рассмотрим более сложный пример. Оператор try определяется в грамматике так:
try_stmt[stmt_ty]:
| 'try' ':' b=block f=finally_block { _Py_Try(b, NULL, NULL, f, EXTRA) } | 'try' ':' b=block ex=except_block+ el=[else_block] f=[finally_block]..
except_block[excepthandler_ty]:
| 'except' e=expression t=['as' z=target { z }] ':' b=block {
_Py_ExceptHandler(e, (t) ? ((expr_ty) t)->v.Name.id : NULL, b, ...
| 'except' ':' b=block { _Py_ExceptHandler(NULL, NULL, b, EXTRA) } finally_block[asdl_seq*]: 'finally' ':' a=block { a }
Уоператора try есть два варианта использования:
1.try только с оператором finally.
2.try с одним или несколькими блоками except, за которыми может следовать необязательный блок else, а после него необязательный finally.
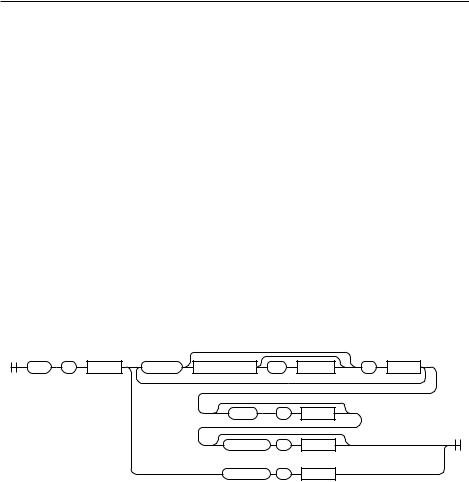
Эти же варианты использования на синтаксической диаграмме:
try |
: |
block |
except |
expression |
as |
target |
: |
block |
|
|
|
|
|
< |
|
|
|
|
|
|
|
else |
: |
block |
|
|
|
|
|
|
finally |
: |
block |
|
|
|
|
|
|
finally |
: |
block |
|
|
Оператор try является хорошим примером более сложной структуры.
Если вы захотите понять язык Python на более глубоком уровне, прочитайте определение грамматики в Grammar python.gram.
ГЕНЕРАТОР ПАРСЕРОВ
Сам файл грамматики никогда не используется компилятором Python. Вместо этого генератор парсеров читает файл и генерирует парсер. Если в файл грамматики будут внесены изменения, вам придется заново сгенерировать парсер и перекомпилировать CPython.
Книги для программистов: https://t.me/booksforits
Повторное генерирование грамматики 67
В Python 3.9 парсер CPython был переписан из автомата, заданного в табличной форме (модуль pgen), в контекстный парсер грамматики. В Python 3.9 старый парсер доступен в командной строке (флаг -X oldparser), а в Python 3.10 он полностью удален. В книге речь идет о новом парсере, реализованном в версии 3.9.
ПОВТОРНОЕ ГЕНЕРИРОВАНИЕ ГРАММАТИКИ
Чтобы увидеть в действии pegen — новый генератор PEG, появившийся
вCPython 3.9, — можно изменить часть грамматики Python. Проведите
вGrammar python.gram поиск small_stmt, чтобы увидеть определение простых операторов:
small_stmt[stmt_ty] (memo): | assignment
| e=star_expressions { _Py_Expr(e, EXTRA) } | &'return' return_stmt
| &('import' | 'from') import_stmt | &'raise' raise_stmt
| 'pass' { _Py_Pass(EXTRA) } | &'del' del_stmt
| &'yield' yield_stmt
| &'assert' assert_stmt
| 'break' { _Py_Break(EXTRA) }
| 'continue' { _Py_Continue(EXTRA) } | &'global' global_stmt
| &'nonlocal' nonlocal_stmt
Строка 'pass' { _Py_Pass(EXTRA) } относится к оператору pass:
pass
Измените эту строку, чтобы в качестве ключевых слов принимались терминалы (ключевые слова) 'pass' или 'proceed'; для этого добавьте конструкцию выбора | и литерал 'proceed':
| ('pass'|'proceed') { _Py_Pass(EXTRA) }
pass
proceed
Книги для программистов: https://t.me/booksforits

68 Грамматика и язык Python
Соберите заново файлы грамматики. В поставку CPython включаются скрипты для автоматизации повторного генерирования грамматики.
В macOS и Linux выполните цель make regen-pegen:
$ make regen-pegen
В Windows откройте командную строку из каталога PCBuild и выполните build. bat с флагом --regen:
> build.bat --regen
Должно появиться сообщение о том, что новый файл Parser pegen parse.c был сгенерирован заново.
С заново сгенерированной таблицей парсера при перекомпиляции Python будет использоваться новый синтаксис. Выполните тот же алгоритм компиляции, который был приведен для вашей операционной системы в предыдущей главе.
Если код был скомпилирован успешно, вы можете выполнить новый двоичный файл CPython и запустить REPL.
Теперь попробуйте определить функцию в REPL. Вместо команды pass используйте альтернативное ключевое слово proceed, которое было скомпилировано в грамматике Python:
$ ./python
Python 3.9 (tags/v3.9:9cf67522, Oct 5 2020, 10:00:00) [Clang 10.0.1 (clang-1001.0.46.4)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>def example():
... proceed
...
>>>example()
Поздравляю — вы изменили синтаксис CPython и скомпилировали собственную версию CPython!
На следующем этапе будут рассмотрены лексемы и их отношение к грамматике.
Книги для программистов: https://t.me/booksforits

Повторное генерирование грамматики 69
Лексемы
Наряду с файлом грамматики в папке Grammar содержится файл Grammar To kens, в котором хранятся все уникальные типы, присутствующие в листовых узлах (leaf node) в дереве синтаксического разбора. Каждая лексема обладает именем и сгенерированным уникальным идентификатором. Имена упрощают обращения к лексемам в tokenizer.
ПРИМЕЧАНИЕ
Файл Grammar Tokens — одна из новых возможностей Python 3.8.
Например, левая круглая скобка называется LPAR, а символ «точка с запятой» — SEMI. Эти лексемы будут разбираться далее в книге:
LPAR |
'(' |
RPAR |
')' |
LSQB |
'[' |
RSQB |
']' |
COLON |
':' |
COMMA |
',' |
SEMI |
';' |
Как и в случае с файлом Grammar, при изменении файла Grammar Tokens необходимо заново запустить pegen.
Чтобы увидеть лексемы в действии, можно воспользоваться модулем tokenizer в CPython.
ПРИМЕЧАНИЕ
Модуль tokenizer, написанный на Python, является служебным моду лем.Реальный парсер Python использует другой способ распознавания лексем.
Создайте простой Python-скрипт с именем test_tokens.py:
Книги для программистов: https://t.me/booksforits

70 Грамматика и язык Python
cpython-book-samples 13 test_tokens.py
# Demo application def my_function():
proceed
Передайте файл test_tokens.py модулю стандартной библиотеки с именем tokenize. На экран выводится список лексем с указанием их позиции (строк и столбцов). Используйте флаг -e для вывода имен конкретных лексем:
$ ./python -m tokenize -e test_tokens.py
0,0-0,0: |
ENCODING |
'utf-8' |
1,0-1,14: |
COMMENT |
'# Demo application' |
1,14-1,15: |
NL |
'\n' |
2,0-2,3: |
NAME |
'def' |
2,4-2,15: |
NAME |
'my_function' |
2,15-2,16: |
LPAR |
'(' |
2,16-2,17: |
RPAR |
')' |
2,17-2,18: |
COLON |
':' |
2,18-2,19: |
NEWLINE |
'\n' |
3,0-3,3: |
INDENT |
' ' |
3,3-3,7: |
NAME |
'proceed' |
3,7-3,8: |
NEWLINE |
'\n' |
4,0-4,0: |
DEDENT |
'' |
4,0-4,0: |
ENDMARKER |
'' |
Впервой колонке выводится интервал с номерами строк и столбцов. Вторая содержит имя лексемы, а в последней выводится значение лексемы.
Ввыводе модуль tokenize подставил ряд подразумеваемых лексем:
zz ENCODING для utf-8;
zz DEDENT для закрытия объявления функции; zz ENDMARKER для завершения файла;
zz пустую строку в конце.
В конце исходных файлов Python рекомендуется оставлять пустую строку. Если не сделать этого, то CPython добавит ее за вас.
Модуль tokenize написан на чистом Python и находится в файле Lib tokenize.py.
Чтобы увидеть подробный вывод парсера C, можно запустить отладочную версию Python с флагом -d. Запустите скрипт test_tokens.py, созданный ранее, следующей командой:
Книги для программистов: https://t.me/booksforits