

Rivero L.Encyclopedia of database technologies and applications.2006
.pdfon top of it. By layering, we mean creating a language that uses the RDF syntax but also adds new classes and properties that have specific semantics.
A recent W3C working draft proposes OWL (Bechhofer et al., 2004) as an ontology language for the Semantic Web. From a formal point of view, OWL can be seen as an equivalent of a very expressive description logic, with an OWL ontology corresponding to a DL Tbox. Figures 3 and 4 show OWL constructors and OWL axioms and their equivalence with description logics. OWL is developed as a vocabulary extension of RDF Schema and is derived from DAML+OIL Web ontology language. This equivalence allows OWL to exploit the considerable existing body of description logics research.
OWL provides two sublanguages: OWL Lite for easy implementations and OWL DL to support the existing description logic business segment. OWL DL has desirable computational properties for reasoning systems. The complete language is called OWL Full.
DATABASE TECHNOLOGY FOR THE SEMANTIC WEB
Description logic systems have been designed to deal with ontologies that are completely processable within a computer’s primary memory. For real applications on the Semantic Web, we expect very large ontologies with very large amounts of instances. Therefore, current DL systems are not valid in this environment. Database technology is necessary in order to be able to deal with ontologies of this size.
Since RDF is the first XML syntax-based language to define ontologies, there are some approaches for storing RDF. These systems use a query language to query RDF schema and data information. ICS-FORTH RDFSuite (Alexaki, Christophides, Karvounarakis, Plexousakis, & Trolle, 2001) is a tool for RDF management. It has a tool for storing and querying RDF descriptions. This tool loads both the RDF schema and metadata defined according to the schema in an object-relational database. Furthermore, the tool distinguishes between unitary and binary relations holding the instances of classes and properties. Four tables are used to represent the RDF schemas, namely, Class, Property, SubClass, and SubProperty.
Sesame (Broekstra, Kampman, & Harmelen, 2002) is a system consisting of a repository, a query engine, and an administration module for adding and deleting RDF data and schema information. The system provides a generic API that allows using any storage device depending on the application domain. Two storage proposals in a relational database using PostgreSQL and MySQL are provided. They use the domain and range tables in addition to the
Applying Database Techniques to the Semantic Web
tables used by ICS-FORTH RDFSuite. The main difference between both proposals is that while in MySQL implementation of the database schema does not change when the RDF schema changes, PostgreSQL adds new tables to represent these changes. Both ICS-FORTH RDFSuite and Sesame use RQL (Karvounarakis, Alexaki, Christophides, Plexousakis, & Scholl, 2002) as the query language.
DLDB (Pan & Heflin, 2003) is a knowledge base that extends a relational database management system (RDBMS) with additional capabilities for DAML+OIL inference. Making use of the FaCT reasoner and Microsoft Access as a RDBMS, DLDB can process, store, and query DAML+OIL formatted semantic content. The system stores RDF in the relational database, and the reasoner is used to precompute the subsumption hierarchy. However, it does not support features that are not related to subsumption.
Logical databases provide a declarative representation language as well as efficient and persistent data storage. Grosof, Horrocks, Volz, and Decker (2003) propose a mapping of a DL subset into logic programs (LP) suitable for evaluation with Prolog. This intersection of DL with LP, called DLP, completely covers RDF Schema and a fraction of OWL. It allows “building ontologies on top of rules” (Grosof et al., 2003). An immediate result of this work is that LP engines could be used for reasoning with these ontologies and for reasoning with (possibly very large numbers of) facts. In Weithoener, Liebig, and Specht (2003), an alternative mapping, resulting in lower computational complexity and more representational flexibility, is presented. For the implementation, they have chosen the deductive database CORAL.
In Roldán and Aldana (2003), an approach using relational databases is presented. The knowledge representation, that is, ontologies, is expressed by the ALC DL (Schmidt-Schauß & Smolka, 1991). Queries are conjunctive queries defined for the ALC DL. A mapping between the ALC DL and the EER model is defined in such a way as to enable us to store our ontologies in the relational database in the most efficient manner. Two database schema levels are distinguished, because it is necessary not only to store the structure of the concrete knowledge base (called instance schema) but also the structure of any ALC knowledge base (called ontology schema) in order to store, for example, the IS-A hierarchy. On the other hand, a mapping between the query language (for conjunctive queries) and SQL is defined. Finally, the semantics of the functions that encapsulate the reasoning mechanisms must be defined. Once the functions that encapsulate the reasoning mechanisms are described, the access pattern defined for each of these functions must be analyzed in order to classify them in different
20
TEAM LinG
Applying Database Techniques to the Semantic Web
categories: (1) functions that have to be evaluated by the DL reasoner; (2) functions that have to be evaluated by the SQL reasoner; (3) functions that can be evaluated by both the DL and SQL reasoners; and (4) functions that have to be evaluated by both the DL and SQL reasoners.
FUTURE TRENDS
The Semantic Web’s aim is to be “machine understandable.” This understanding is close to reasoning. We want to query classes and instances with respect to ontologies. We expect to find very large knowledge bases that entail reasoning with (a very large number of) instances. It is unlikely that standard Abox techniques will be able to cope with it. Therefore, we have to make reasoning scalable (both in the Tbox and in the Abox) in the context of the Semantic Web. It is very important that the Semantic Web become viable in a practical way. In order to achieve this, database technologies are fundamental; in fact, database technologies are a key issue to efficiently manage large amounts of knowledge.
Database technology is a natural branch of computer science that has demonstrated that it is able to cope with efficient and scalable queries over (possibly distributed) persistent data stored in a secondary memory.
In the Semantic Web context we are going to need all the knowledge developed by database research. This technology should be revised, adapted, or maybe redesigned, but we strongly believe that it is the only foundation that could lead to a Semantic Web that is usable in practice and beyond theoretical experiments.
In summary, persistence (structures for representation in secondary memory), access paths (indexes, maybe ad hoc indexing), and efficient and scalable queries (over data in mass storage and maybe distributed) are the successful technological issues that have to be adapted to the Semantic Web.
CONCLUSION
The problem of combining the Semantic Web and database technology is not that simple nor that easy. We should still allow for reasoning in both the Tbox and (very specially) in the Abox. Furthermore, we have to combine queries and both types of reasoning in new query/reasoning languages.
There is still a great deal of work to be done, but this is the way to the future, not only for the Semantic Web but also for database technology.
To guarantee scalability we must merge artificial intelligence and database technology in the Semantic Web. It is necessary to define storage methods for knowledge,
that is, both representation methods and access paths |
|
|
A |
||
(e.g., index). Furthermore, it is necessary to take into |
||
account that knowledge is not centralized in this context. |
|
|
|
Nevertheless, we believe that there is not a unique representation and that a specific physical representation of the Abox and an ad hoc indexes structure will be necessary. Both representation and indexes will depend on the expressivity of the query language and the implemented reasoning. Therefore, the solution will not be unique, but a trade-off, and we will have hierarchies of ontology definition languages, each one with a representation trade-off (a best physical mapping) regarding both structural and query (generated by reasoning) patterns.
REFERENCES
Alexaki, S., Christophides, V., Karvounarakis, G., Plexousakis, D., & Trolle, K. (2001). The ICS-FORTH RDFSuite: Managing voluminous RDF description bases.
Secondnd International Workshop on the Semantic Web (SemWeb’01), CEUR Workshop Proceedings, (Vol. 40).
Berners-Lee, T., Hendler, J., & Lassila, O. (2001, May). The Semantic Web. Scientific American. Retrieved August 9, 2004, from http://www.sciam.com/ article . cfm?articleID=00048144 - 10D2 - 1C70 - 84A9809EC588EF21
Brickley, D., & Guha, R. V. (2002). RDF vocabulary description language 1.0: RDF Schema (W3C Working Draft 30 April 2002). Retrieved August 9, 2004, from http://www.w3.org/TR/rdf-schema/
Broekstra, J., Kampman, A., & Harmelen, F. (2002). Sesame: A generic architecture for storing and querying RDF and RDF Schema. First International Semantic Web Conference (ISWC2002), Lecture Notes in Computer Science, (Vol. 2342).
Grosof, B. N., Horrocks, I., Volz, R., & Decker, S. (2003). Description logic programs: Combining logic programs with description logic. In Proceedings of the 12th International World Wide Web Conference. New York: ACM Press.
Haarslev, V., & Möller, R. (2001). RACER system description. In R. Goré, A. Leitsch, & T. Nipkow (Eds.), Proceedings of International Joint Conference on Automated Reasoning, IJCAR’2001 (pp. 701-705). Berlin, Germany: Springer-Verlag.
Horrocks, I. (1998). The FaCT system. In H. de Swart (Ed.),
Lecture notes in artificial intelligence: Vol. 1397. Automated reasoning with analytic tableaux and related
21
TEAM LinG
methods: International Conference Tableaux ’98 (pp. 307-312). Berlin, Germany: Springer-Verlag.
Karvounarakis, G., Alexaki, S., Christophides, V., Plexousakis, D., & Scholl, M. (2002). RQL: A declarative query language for RDF. WWW2002, May 7-11, 2002, Honolulu, Hawaii.
Nardi, D., & Brachman, R. J. (2003). An introduction to description logics. In The description logic handbook: Theory, implementation and applications (pp. 1-40). Cambridge, UK: Cambridge University Press.
Bechhofer, S., Harmelen, F., Hendler, J., Horrocks, U. McGuinness, D., Patel-Schneider, P.F., & Stein, L.A. (2004).
OWL Web ontology language reference (W3C Working Draft 10 February 2004). (2004). Retrieved August 9, 2004, from http://www.w3.org/TR/owl-ref/
Pan, Z., & Heflin, J. (2003). DLDB: Extending relational databases to support Semantic Web queries. In
Workshop on Practical and Scaleable Semantic Web Systems, ISWC 2003, (pp. 109-113). Lehigh University: Dept. of Computer Science and Engineering.
Roldán, M. M., & Aldana J. F. (2003). Storing and querying knowledge in the deep Semantic Web. 1ère Conferénce en Sciences et Techniques de I’Information et de la Communication (CoPSTIC’03). Morocco: Rabat.
Schmidt-Schauß, M., & Smolka, G. (1991). Attributive concept descriptions with complements. Artificial Intelligence, 48, 1-26.
Weithoener, T., Liebig, T., & Specht, G. (2003). Storing and querying ontologies in logic databases. In First International Workshop on Semantic Web and Databases (pp. 329-348). Berlin, Germany.
KEY TERMS
Assertional Reasoning: A description logic knowledge base is made up of two parts, a terminological part (the terminology or Tbox) and an assertional part (the Abox), each part consisting of a set of axioms. The AbBox contains extensional knowledge that is specific to the individuals of the domain of discourse. There has been a great deal of work on the development of reasoning algorithms for expressive DLs, but in most cases these only consider Tbox reasoning. Reasoning mechanisms for the Abox (i.e., instance checking) isare called assertional reasoning. Assertional reasoning is important for real Semantic Web applications.
Applying Database Techniques to the Semantic Web
Description Logics: Description lLogics are considered the most important knowledge representation formalism unifying and giving a logical basis to the wellknown traditions of fFrame-based systems, Ssemantic Nnetworks and KL-ONE-like languages, oObjectOoriented representations, Ssemantic data models, and Ttype systems.
Knowledge Representation: It is a fragmentary theory of intelligent reasoning, expressed in terms of three components: (1) the representation’s fundamental conception of intelligent reasoning; (2) the set of inferences the representation sanctions; and (3) the set of inferences it recommends.
Ontology: An ontology is a logical theory accounting for the intended meaning of a formal vocabulary, i.e., its ontological commitment to a particular conceptualization of the world. The intended models of a logical language using such a vocabulary are constrained by its ontological commitment. An ontology indirectly reflects this commitment (and the underlying conceptualization) by approximating these intended models.
Query/Reasoning: A query means retrieving instances of both concepts and relationships between concepts, that satisfy certain restrictions or qualifications and hence are interesting for a user. Querying instances of ontologies involves making use of reasoning (both Abox and Tbox) mechanisms in order to obtain the corrected and completed results.
Reasoning: The ability of a system to find implicit consequences of its explicitly represented knowledge. Such systems are therefore characterized as knowl- edge-based systems.
Semantic Web: The Semantic Web is a mesh of information linked up in such a way as to be easily processable by machines, on a global scale. You can think of it as being an efficient way of representing data on the World Wide Web, or as a globally linked database.
ENDNOTES
1http://www.w3.org/XML/Schema/
2http://www.w3c.org/RDF/
22
TEAM LinG

23
Benchmarking and Data Generation in Moving B
Objects Databases
Theodoros Tzouramanis
University of the Aegean, Greece
INTRODUCTION
Moving objects databases (MODs) provide the framework for the efficient storage and retrieval of the changing position of continuously moving objects. This includes the current and past locations of moving objects and the support of spatial queries that refer to historical location information and future projections as well. Nowadays, new spatiotemporal applications that require tracking and recording the trajectories of moving objects online are emerging. Digital battlefields, traffic supervision, mobile communication, navigation systems, and geographic information systems (GIS) are among these applications. Towards this goal, during recent years many efforts have focused on MOD formalism, data models, query languages, visualization, and access methods (Guting et al., 2000; Saltenis & Jensen, 2002; Sistla, Wolfson, Chamberlain, & Dao, 1997). However, little work has appeared on benchmarking.
BACKGROUND
The role of benchmarking in MODs is to compare the behavior of different implementation alternatives under the same settings. It is important that the results must hold not only for a specific environment but in more general settings as well. Thus, the user is able to repeat the experiments and come to similar conclusions (Zobel, Moffat, & Ramamohanarao, 1996).
An example of a benchmark is the comparison of space requirements and query execution time of access methods for MODs. In order to compare the behavior of different indexing schemes under the same platform, there must be a flexible performance benchmarking environment. The general architecture of such a benchmarking toolkit is presented in Figure 1, and according to Theodoridis, Silva, and Nascimento (1999) and Tzouramanis, Vassilakopoulos, and Manolopoulos (2002), it consists of the following components:
•a collection of access methods for MODs,
•a module that generates synthetic data sets which cover a variety of real-life applications,
•a set of real data that also represents various reallife examples,
•a query processor capable of handling a large set of queries for extensive experimentation purposes,
•a reporter to collect all relevant output report logs, and
•a visualization tool to visualize data sets for illustrative purposes.
Good benchmarking must correspond to a recognizable, comprehensible real-life situation. In case large real data sets are not available, benchmarking requires the generation of artificial data sets following the realworld behavior of spatial objects that change their locations, shapes, and sizes over time and cover a variety of real-life applications. Thus one of the most important components of a benchmarking tool is the module that
Figure 1. A simplified benchmarking environment for access methods for MODs
a collection of |
a visualization |
a generator of |
|||||
Access Methods (AMs) |
|
tool |
synthetic data |
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i-th Access Method |
|
user-defined settings |
index |
||
(AMi) |
|
(for buffer, page size |
|
|
construction |
|
and additional gauges) |
||||
|
|
|
|||
|
|
|
|
|
|
a set of |
a set of |
performance evaluation |
|
||
and comparison of log reports |
|
||||
real data |
queries |
|
|||
|
|
|
|
||
|
R e p o r t |
|
|
for AM i |
|
|
R e p o r t |
|
|
for AM i |
|
|
R e p o r t |
|
R e p o r t |
for AM i |
|
R e p o r t |
||
for AM i |
||
for AM4 |
||
query |
||
|
||
processing |
|
Copyright © 2006s, Idea Group Inc., distributing in print or electronic forms without written permission of IGI is prohibited.
TEAM LinG
Benchmarking and Data Generation in Moving Objects Databases
generates synthetic data sets. In MODs, the work on the generation of synthetic data is limited, and only a few pioneering articles have recently addressed the topic of moving objects data generators.
MAIN THRUST
Synthetic Data Generators
A data set generator for MODs, called generator spatiotemporal data (GSTD), has been proposed by Theodoridis, Silva, and Nascimento (1999). It can generate moving points or rectangles and starts by distributing their centers in the workspace according to certain distributions. After the initialization phase, there are three main parameters to control the evolution of the objects throughout time, according to a desired distribution. These parameters are: (a) the duration of object instances, which involves time-stamp changes between consecutive instances; (b) the shift of the objects, which involves changes of spatial locations of the object centers; and (c) the resizing of objects, which involves changes of object sizes (only applicable to rectangular objects).
The GSTD supports three alternative approaches for the manipulation of invalid object instances in cases where an object leaves the spatial data space. However, a limitation of the GSTD approach is that the objects are moving almost freely in the workspace without taking into consideration the interaction between other objects or any potential restrictions. In particular, it could be argued that in any possible scenario, the objects are scattered all over the data space, or are moving in groups and the whole scene has the appearance of an unob-
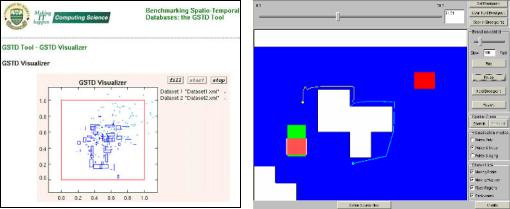
structed polymorphic cloud movement. In the left part of Figure 2, a snapshot of an example of two synthetic data sets being displayed concurrently is illustrated.
In order to create more realistic scenarios, Pfoser and Theodoridis (2003) have extended the latter approach. They introduced an additional GSTD parameter to control the change of direction, and they used static rectangles for simulating an infrastructure, where the scenario indicates that each moving object has to be outside of these rectangles.
Saglio and Moreira (2001) propose the Oporto generator for time-evolving points and rectangles. It uses the modeling of fishing ships as a motivation. Ships are attracted by shoals of fish, while at the same time they are repulsed by storm areas. The fish themselves are attracted by plankton areas. Ships are moving points, whereas shoals, plankton, and storm areas are moving regions. Although useful for testing access methods, the original algorithm is highly specialized and turns out to be of limited use with respect to the demands of other real-world applications. In the right part of Figure 2, an example of the use of the Oporto generator is presented. The snapshot illustrates the motion of two ships being attracted by a gray shoal of fish.
Brinkhoff (2002) demonstrates a generator for “net- work-based” moving objects. It combines a real network with user-defined properties of the resulting data set. The driving application is the field of traffic telematics, and the presented generator satisfies exactly the requirements of this field. Important concepts of the generator are the maximum speed and the maximum edge capacity, the maximum speed of the object classes, the interaction between objects, the different approaches for determining the starting and the destination point of a moving object, and the recomputation of a route initiated by a
Figure 2. A snapshot of GSTD’s Web-based interface (left) and a snapshot of Oporto’s interface (right)
24
TEAM LinG

Benchmarking and Data Generation in Moving Objects Databases
Figure 3. A snapshot of the network-based generator’s interface (left) and a snapshot of the City Simulator’s |
B |
interface (right) |
reduced speed on an edge and by external events. A framework for preparing the network, for defining functions and parameters by the users, and for data generation reporting are also presented. However, a disadvantage of the method is that it requires a significant computing power for the generation of moving objects. Nevertheless, although the author claims that the approach allows considering the characteristics of a wide range of applications (mostly network-based), it is clear that many other interesting real-world application examples such as meteorological phenomena, faunal phenomena, natural catastrophes, etc. cannot be simulated using this tool. In the left
part of Figure 3, an example of the use of the generator is illustrated. The points are moving objects and the lines are the roads.
The City Simulator (Kaufman, Myllymaki, & Jackson, 2001; Myllymaki & Kaufman, 2002) is another generator specifically designed for applications of the field of location-based services, i.e., for applications that must continuously track mobile users. It models the motion of large populations of people in a city. The data space of the city consists of roads, lawns, and buildings that affect the motion of the objects. Each building has an individual number of floors. Moving objects on a road
Figure 4. Snapshots of the G-TERD’s interface
25
TEAM LinG
Benchmarking and Data Generation in Moving Objects Databases
enter with a user-defined probability the first floor of a building. They perform random walks on this floor and may leave the building if they are near a door, or they may move up or move down to another floor, depending on user-defined probabilities, if they are near to the stairs. The number of objects, the number of time stamps, and many other parameters can be controlled by the user’s interface. New city models can be imported as XML documents, which describe the layout of the city, including roads, buildings, and vacant space. In the right part of Figure 3 are shown the implemented city plan and an example of generated moving objects on the roads or on different floors of building.
Both the network-based generator and the City Simulator assume that the movement of objects is constrained to a transportation network. However, while the networkbased generator is limited to two-dimensional data sets, the City Simulator supports the movement of objects in a three-dimensional workspace. Another difference is that in the case of the City Simulator, the movement of the objects is influenced by the surrounding place where they walk, while in the case of the network-based generator, their movement is influenced by other moving objects as well.
Finally, Tzouramanis et al. (2002) present another elaborate approach for synthetic data generation, which does not constrain movement to a network. It is called the generator of time-evolving regional data (G-TERD), and its basic concepts include the structure of complex twodimensional regional objects, their color, maximum speed, zoom and rotation angle per time slot, the influence of other moving or static objects on the speed and on the moving direction of an object, the position and movement
of the scene observer, the statistical distribution of each changing factor, and, finally, the time.
G-TERD is very parametric and flexible in the simulation of a variety of real-world scenarios. Users can specify the time domain and the workspace extent, the maximum number of objects in the sample, their minimum and maximum speed, zoom and rotation angle per time slot, the percentage of static and moving objects, the sceneobserver’s window size, and, finally, the number of colors supported. Users may also decide on the statistical model of the cardinality of the new objects and sub-objects per time slot, the deletion time slot of an object or sub-object, their speed, zoom, and rotation angle, and, finally, the time period that must elapse before the next computation of an attribute (speed, zoom, color of an object or sub-object, etc). Various statistical distributions are supported for that purpose. Figure 4 presents some snapshots of a realistic scenario produced by G-TERD. The snapshots show regional static objects that live for the whole scene lifetime and moving objects that are generated along the y-axis and cross the workspace but each at a different speed.
Benchmarking Toolkits
In the sequel, we give a brief overview of two known benchmarking toolkits that have been designed for the evaluation of access methods for MODs (for more details, see Brinkhoff & Weitkamper, 2001; Myllymaki & Kaufman, 2002).
A benchmarking tool for querying XML-represented moving objects has been proposed by Brinkhoff and
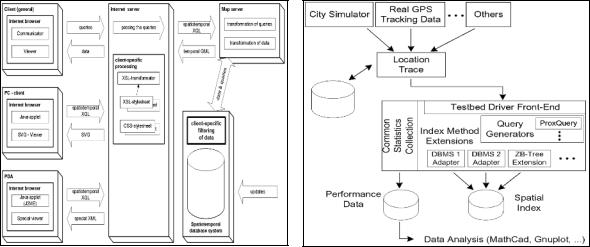
Figure 5. The architectures of MOX (left) and LOCUS (right), as they have been proposed in Brinkhoff and Weitkamper (2001) and Myllymaki and Kaufman (2002), respectively
26
TEAM LinG

Benchmarking and Data Generation in Moving Objects Databases
Weitkamper (2001). It is called MOX and its architecture is illustrated in the left part of Figure 5. An important requirement of applications using such an architecture is to be updated about new, reloaded, or removed objects fulfilling a given query condition. Such queries are called continuous queries. For testing the system and for investigating continuous queries, the network-based generator has been integrated into MOX. The objects produced by the generator are inserted into the database, which triggers the affected continuous queries.
LOCUS (Myllymaki & Kaufman, 2002) is another benchmarking environment for dynamic spatial indexing. The City Simulator is a component of its architecture for generating location trace files. These benchmark data are used as input for the construction of the indices of the access methods, the performance characteristics of which are tested by LOCUS. After the index construction, m spatiotemporal queries, such as proximity queries, k-nearest neighbor queries, and sorteddistance queries, are executed in respect to the location of a user. The architecture of LOCUS is depicted in the right part of Figure 5.
FUTURE TRENDS
With the variety of spatiotemporal access methods for MODs, it becomes essential to have a framework to support the evaluation and fair comparison of these access methods. One approach is to use the already existing benchmark tools, i.e., the MOX and the LOCUS. Another approach is to develop a more general and extensive platform to capture the special needs of each class of the modeled application (e.g., the type of timeevolving spatial objects, the type of queries, and the frequency of updates). Much research work still needs to be carried out in this field in order to help the MOD research community to move in the right rigorous and experimental direction.
CONCLUSION
This short survey has focused on the issue of benchmarking in MODs. For experimental evaluation of access methods and query processing techniques, real as well as synthetic data sets are important. The former is useful for ensuring that a technique under study is subject to realistic scenarios. For an interesting survey that covers several real data sets that are publicly available through the Web, the reader is referred to Nascimento, Pfoser, and Theodoridis (2003). However, the desired real data sets may not be available or they may
not be useful for testing extreme conditions. In contrast
to the real data sets, synthetic data generators allow the B generation of data sets with specific properties, thus making it possible to subject a technique to a wide variety
of applications. We have briefly described five realistic data generators for MODs: the GSTD, the Oporto, the network-based generator, the City Simulator, and the G- TERD.
The network-based generator and the City Simulator have been integrated into the environment of the benchmarking toolkits MOX and LOCUS, respectively. In this process we have also described the general architecture of both these flexible tools, which have been specifically designed for the performance evaluation of access methods for MODs.
REFERENCES
Brinkhoff, T. (2002). A framework for generating net- work-based moving objects. GeoInformatica, 6(2), 155182.
Brinkhoff, T., & Weitkamper, J. (2001). Continuous queries within an architecture for querying XML-represented moving objects. In Proceedings of the seventh International Symposium on Spatial and Temporal Databases
(Vol. 1, pp. 136-154). Berlin, Germany: Springer-Verlag.
Guting, R. H., Bohlen, M. H., Erwig, M., Jensen, C. S., Lorentzos, N. A., Schneider, M., & Vazirgiannis, M. (2000). A foundation for representing and querying moving objects. ACM Transactions on Database Systems, 25(1), 1-42.
Kaufman, J., Myllymaki, J., & Jackson, J. (2001). City Simulator. alphaWorks Emerging Technologies. New York: IBM Corporation.
Myllymaki, J., & Kaufman, J. (2002). LOCUS: A testbed for dynamic spatial indexing. Bulletin of the Technical Committee on Data Engineering, 25(2), 48-55.
Nascimento, M. A., Pfoser, D., & Theodoridis, Y. (2003). Synthetic and real spatiotemporal datasets. Bulletin of the Technical Committee on Data Engineering, 26(2), 2632.
Pfoser, D., & Theodoridis, Y. (2003). Generating seman- tics-based trajectories of moving objects. International Journal of Computers, Environment and Urban Systems,
27(3), 243-263.
Saglio, J.-M., & Moreira, J. (2001). Oporto: A realistic scenario generator for moving objects. GeoInformatica, 5(1), 71-93.
27
TEAM LinG
Benchmarking and Data Generation in Moving Objects Databases
Saltenis, S., & Jensen, C. S. (2002). Indexing of moving objects for location-based services. In Proceedings of International Conference on Data Engineering (pp. 463472).
Sistla, A. P., Wolfson, O., Chamberlain, S., & Dao, S. (1997). Modeling and querying moving objects. In Proceedings of International Conference on Data Engineering, IEEE Computer Society, Los Alamitos, CA (pp. 422432).
Theodoridis, Y., Silva, J. R. O., & Nascimento, M. A. (1999). On the generation of spatiotemporal datasets. In
Proceedings of the sixth Symposium on Spatial Databases (pp. 147-164).
Tzouramanis, T., Vassilakopoulos, M., & Manolopoulos, Y. (2002). On the generation of time-evolving regional data. GeoInformatica, 6(3), 207-231.
Zobel, J., Moffat, A., & Ramamohanarao, K. (1996). Guidelines for presentation and comparison of indexing techniques. ACM SIGMOD Record, 25(3), 10-15.
KEY TERMS
Access Method: A data structure that enables fast access over the records of a database file. Careful tuning or selection of the appropriate access method is very important in database performance.
Benchmark Toolkit: A tool that has been proposed for fair comparisons of different implementation alternatives, mostly of access methods. Its main components are: a synthetic data generator and/or some sets of real data, a query processor, and a set of access methods whose behavior has to be investigated. The output of a benchmark is a set of values describing the performance of each access method for a given data set and a set of queries which were executed iteratively by the query processor. Often these values describe separately the input/output time and CPU time needed for the index construction and for the computation of the queries.
Location-Based Services: Can be described as applications, which react according to a geographic trigger. A geographic trigger might be the input of a town name, zip code, or street into a Web page, the position of a mobile phone user, or the precise position of someone’s car as s/he is driving home from the office. Using the knowledge of where someone is or where s/he
intends to go is the essence of location-based services. The arrival of high bandwidth mobile networks has highlighted the potential development of location-based services.
Moving Objects Database: A spatiotemporal database that represents the dynamic attributes of continuously moving objects, including their past, current, and anticipated future location information.
Spatial Database: A database that represents, stores, and manipulates static spatial data types, such as points, lines, surfaces, volumes, and hyper-volumes in multidimensional space.
Spatiotemporal Database: A database that manipulates spatial data, the geometry of which changes dynamically. It provides the chronological framework for the efficient storage and retrieval of all the states of a spatial database over time. This includes the current and past states and the support of spatial queries that refer to present and past time-points as well.
Spatiotemporal Query: A query that specifies spatial/temporal predicates and retrieves all objects that satisfy them. A spatial predicate is defined in terms of a point or an extent while a temporal predicate can involve a time instant or a time interval. For example, the query “Find all vehicles that will intersect the polygon S within the next five minutes” is a spatiotemporal range query. The spatial range is the polygon S and the temporal range is the time interval between now and 5 minutes from now.
Synthetic Data Generator: A tool able to generate a variety of synthetic data sets, according to statistical distributions. A fundamental issue in the generation of the synthetic data sets is the availability of a rich set of parameters that control their generation. Different statistical distributions and parameter settings correspond to different data sets and scenarios of real-world behavior.
Synthetic Data Set: A data set that is generated by some artificial specifications. Synthetic data are of high importance for the evaluation of the performance behavior of access methods in exactly specified or extreme situations, where real data are not available.
Temporal Database: A database that supports the maintenance of time-evolving data and the satisfaction of specialized queries that are related to three notions of time for these data: the past, the present, and the future.
28
TEAM LinG
|
29 |
|
Bioinformatics Data Management and Data |
|
|
|
B |
|
Mining |
|
|
|
|
|
|
|
Boris Galitsky
Birbeck College University of London, UK
INTRODUCTION
Bioinformatics is the science of storing, extracting, organizing, analyzing, interpreting, and utilizing information from biological sequences and molecules. The focus of bioinformatics is the application of computer technology to the management of biological information. Specifically, it is the science of developing computer databases and algorithms to facilitate and expedite biological research, particularly in genomics. It has been mainly stimulated by advances in DNA sequencing and genome mapping techniques (Adams, Fields & Venter, 1994). Genomics is the discipline that studies genes and their functions, including the functional study of genes, their resulting proteins, and the role played by the proteins in the biochemical processes, as well as the study of human genetics by comparisons with model organisms such as mice, fruit flies, and the bacterium E. coli
The Human Genome Project has resulted in rapidly growing databases of genetic sequences. Genome includes all the genetic material in the chromosomes (loci of genetic information) of a particular organism; its size is generally given as its total number of base pairs. New techniques are needed to analyze, manage, and discover sequence, structure, and functional patterns or models from these large sequence and structural databases. High performance data analysis algorithms are also becoming central to this task (Pevsner, 2000; Wilkins et al., 1997).
Bioinformatics provides opportunities for developing novel data analysis methods. Some of the grand challenges in bioinformatics include protein structure prediction, homology search, multiple alignment, and phylogeny construction (the evolutionary relationships among organisms; the patterns of lineage branching produced by the true evolutionary history of the organisms being considered). Proteins are defined as large molecules composed of one or more chains of amino acids in a specific order; the order is determined by the base sequence of nucleotides in the gene that codes for the protein. Proteins are required for the structure, function, and regulation of the body’s cells, tissues, and organs; and each protein has unique functions. Examples
are hormones, enzymes, and antibodies. Amino acids are the building blocks of proteins; only about 20 amino acids are used to build the thousands of kinds of proteins needed by living cells. Nucleotides are the building blocks of DNA and RNA, consisting of a nitrogenous base, a five-carbon sugar, and a phosphate group. Together, the nucleotides form codons (groups of three nucleotides), which when strung together, form genes that link to form chromosomes.
The other challenges of bioinformatics include genomic sequence analysis and gene finding, as well as applications in the data analysis of gene expression (transcriptional activity of a gene resulting in one or more RNA products and, usually following translation, one or more protein products), drug discovery in the pharmaceutical industry, and so forth (Waterman, 1995). For example, in protein structure prediction, the problem is in determining the secondary (division of sequence into fragments), tertiary (3D space), and quaternary structure of proteins, given their amino acid sequence (Figure 1) (Protein Structure).
Homology search aims at detecting increasingly distant homologues, that is, proteins related by evolution from a common ancestor. Multiple alignment and phylogenetic tree construction are interrelated problems. Multiple alignment aims at aligning a whole set of sequences to determine which subsequences are conserved. This works best when a phylogenetic tree of related proteins (illustration of how some of these proteins were inherited by others) is available. Finally, gene finding aims at locating the genes in a DNA sequence.
The following database-related problems are arising in bioinformatics:
•Data mining and warehousing as applied to biology;
•Data types and modeling needed for biological analysis;
•Interactive exploration and visualization for biology; and
•New indexing and search structures with applications to biology.
Copyright © 2006, Idea Group Inc., distributing in print or electronic forms without written permission of IGI is prohibited.
TEAM LinG