

Chapter 3. Processing YAML Information
YAML is both a text format and a method for presenting any data structure in this format. Therefore, this specification defines two concepts: a class of data objects called YAML representations, and a syntax for presenting YAML representations as a series of characters, called a YAML stream. A YAML processor is a tool for converting information between these complementary views. It is assumed that a YAML processor does its work on behalf of another module, called an application. This chapter describes the information structures a YAML processor must provide to or obtain from the application.
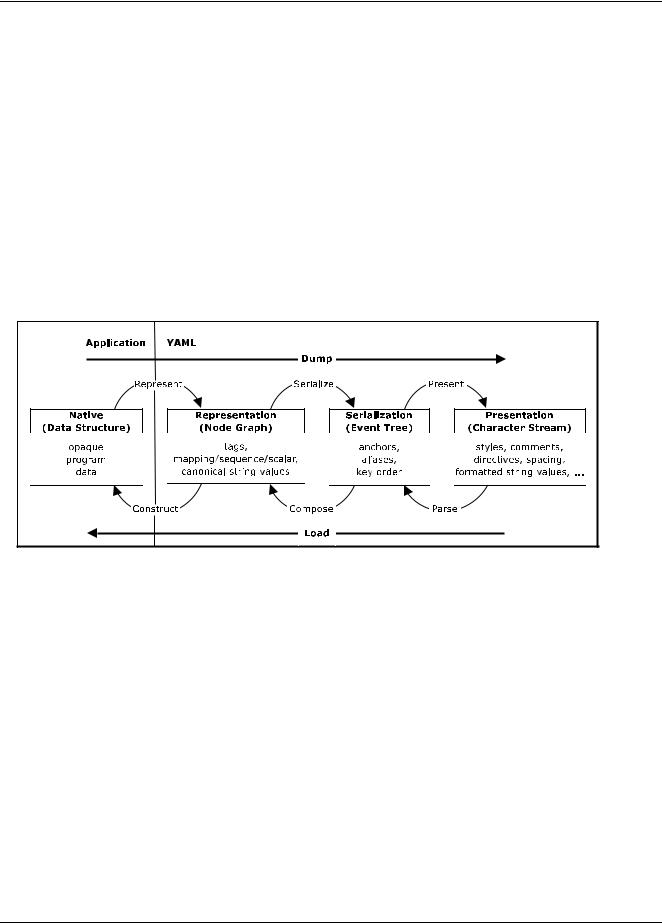
YAML information is used in two ways: for machine processing, and for human consumption. The challenge of reconciling these two perspectives is best done in three distinct translation stages: representation, serialization, and presentation. Representation addresses how YAML views native data structures to achieve portability between programming environments. Serialization concerns itself with turning a YAML representation into a serial form, that is, a form with sequential access constraints. Presentation deals with the formatting of a YAML serialization as a series of characters in a human-friendly manner.
Figure 3.1. Processing Overview
A YAML processor need not expose the serialization or representation stages. It may translate directly between native data structures and a character stream (dump and load in the diagram above). However, such a direct translation should take place so that the native data structures are constructed only from information available in the representation.
3.1. Processes
This section details the processes shown in the diagram above. Note a YAML processor need not provide all these processes. For example, a YAML library may provide only YAML input ability, for loading configuration files, or only output ability, for sending data to other applications.
3.1.1. Represent
YAML represents any native data structure using three node kinds: the sequence, the mapping and the scalar. By sequence we mean an ordered series of entries, by mapping we mean an unordered association of unique keys to values, and by scalar we mean any datum with opaque structure presentable as a series of Unicode characters. Combined, these primitives generate directed graph structures. These primitives were chosen because they are both powerful and familiar: the sequence corresponds to a Perl array and a Python list, the mapping corresponds to a Perl hash table and a Python dictionary. The scalar represents strings, integers, dates and other atomic data types.
10
XSL• FO
RenderX