

Расчет средней скорости загрузки
В двух из трёх рассмотренных способов используется значение средней скорости загрузки -ым АБ к -ому слоту. Существует 2 основных способа расчета данного значения:
Первый способ
Фиксируется
интервал времени
 на котором рассчитывается средняя
скорость. Определяем количество слотов:
на котором рассчитывается средняя
скорость. Определяем количество слотов:

Средняя скорость, с которой абонент загружал данные может быть рассчитана как:
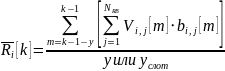
В данной формуле
сумма
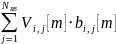 - показывает объем данных, переданный
-ому
АБ в
-ом
слоте.
- показывает объем данных, переданный
-ому
АБ в
-ом
слоте.
Далее, в листинге 7, следует реализация данного метода в виде функции:
Листинг 7. Первый способ расчета средней скорости
def calc_R_mean(slot_id: int, sub_id: int, resources: list, subs: pd.DataFrame) -> float: # Объём данных, который передан абоненту sub_id packs_sum = 0 result = .0
# Цикл по слотам: for slot_i in range(max(0, slot_id - 1 - y_slot), slot_id):
# Кол-во ресурсных блоков в слоте slot_id, которые принадлежат АБ с индексом sub_id resource_blocks = 0
# Цикл по ресурсным блокам for res_sub_i in resources[slot_i]: # Проверка принадлежности ресурсного блока в слоте АБ sub_idx if res_sub_i == sub_id: resource_blocks += 1
# Находим объём данных, который передан абоненту sub_idx в ресурсных блоках в слоте slot_idx packs_sum += subs.iloc[slot_i, sub_id] * resource_blocks result = packs_sum / y_slot return result |
Второй способ
Второй способ - сглаживающий фильтр - заключается в том, что средняя скорость, с которой абонент загружал, может быть записана как:
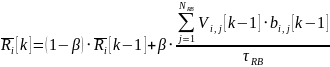
где
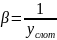
Далее, в листинге 8, следует реализация данного метода в виде функции:
Листинг 8. Второй способ расчета средней скорости
def calc_smooth_R_mean(slot_id: int, sub_id: int, resources: list, subs: pd.DataFrame, R_mean_list: list) -> float: # Расчет результата result = (1-beta) * R_mean_list[sub_id] + beta * (np.sum([subs.iloc[sub_id, slot_id] for res_id in resources[-1] if res_id == sub_id]) / tau) return result |
Расчет среднего суммарного объема
Для сравнения
между собой приведённых выше алгоритмов
распределения ресурсов, необходимо
ввести переменную
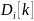 - объем данных, находящихся в буфере
-ого
абонента на конец
-ого
слота. Для определения объема используется
следующее выражение:
- объем данных, находящихся в буфере
-ого
абонента на конец
-ого
слота. Для определения объема используется
следующее выражение:
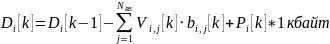
Для оценки
эффективности рассмотренных алгоритмов
необходимо построить график зависимости
(средний суммарный объем буфера) от
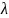 (параметр распределения входящего
потока заявок) при различном количестве
абонентов в БС.
(параметр распределения входящего
потока заявок) при различном количестве
абонентов в БС.
Далее, в листинге 9, следует реализация данного метода в виде функции:
Листинг 9. Расчет среднего суммарного объема данных
def calc_D_mean(subs: pd.DataFrame, lambda_: float, algorithm: str) -> float: # Генерация входящего потока пакетов P = generate_P(lambda_, subs)
# Отправляем в буфер первый слот buffer = [P[0].to_list()]
# Массив ресурсных блоков слотов resources = [[]]
# Список средних скоростей (в начале 0.0 у всех) R_mean_list = [[calc_R_mean(0, sub_id, resources, subs) for sub_id in range(len(subs.index))]]
# ID рассматриваемого пользователя current_sub_id = 0 R_buffered_subs = []
# Цикл по слотам for slot_id in range(1, len(P.columns)): # Рассчитываем среднюю скорость только для EB и PF if algorithm in ["EB", "PF"]: # R_mean_list.append( # [calc_R_mean(slot_id, sub_id, resources, subs) for sub_id in range(len(subs.index))] # ) R_mean_list.append( [calc_smooth_R_mean(slot_id, sub_id, resources, subs, R_mean_list[-1]) for sub_id in range(len(subs.index))] )
# Ищем пользователей с заполненным буфером subs_with_buffer = [i % len(subs.index) for i in range(current_sub_id, current_sub_id + len(subs.index)) if buffer[-1][i % len(subs.index)] != 0] current_sub_id = (current_sub_id + 1) % len(subs.index)
# Расчет нового буфера для текущего слота buffer.append(buffer[-1].copy())
# Если есть АБ с заполненным буфером if subs_with_buffer: # Выбираем параметры АБ из списка R_buffered_subs = [] C_buffered_subs = [] for i in subs_with_buffer: R_buffered_subs.append(R_mean_list[-1][i]) C_buffered_subs.append(subs.iloc[i, slot_id])
# Создаём список приоритета АБ priority_list = calc_priority(algorithm, R_buffered_subs, C_buffered_subs) subs_priority = [sub for _, sub in sorted(zip(priority_list, subs_with_buffer))]
# Сколько ресурсов нужно каждому АБ slots_res_block = [int(np.ceil(buffer[-1][sub_id] / subs.iloc[sub_id, slot_id])) for sub_id in subs_priority] if np.sum(slots_res_block) > N_rb: cut_off = np.sum(slots_res_block) - N_rb slots_res_block[-1] -= cut_off while slots_res_block[-1] <= 0: cut_off = slots_res_block.pop() slots_res_block[-1] += cut_off
resources.append([id for id, count in zip(subs_priority, slots_res_block) for _ in range(count)]) # Удаляем АБ, без ресурсов в слоте if len(slots_res_block) != len(subs_priority): difference = len(slots_res_block) - len(subs_priority) subs_priority = subs_priority[:difference]
# Обработка АБ с выделенными ресурсами (уменьшаем буфер АБ) for id, sub_id in enumerate(subs_priority): buffer[-1][sub_id] = max(0, buffer[-1][sub_id] - subs.iloc[sub_id, slot_id] * slots_res_block[id]) # Если нет АБ с заполненным буфером else: resources.append([])
# Добавляем новые пакеты buffer[-1] = [buff + pack for buff, pack in zip(buffer[-1], P[slot_id])]
# Расчет среднего суммарного объема буфера по слотам return np.mean([sum(slot_buff) for slot_buff in buffer]) |