

Подходы к разработке кода ос по отношению к процессам.
Ядро вне процессов (автономное ядро)
Используется во многих ранних ОС. Концепция процесса применяется только к пользовательским программам. Код ОС выполняется как некий отдельный объект, работающий в привилегированном режиме (рис. 3.3, а).
Ядро в составе пользовательских процессов
Используется в небольших ЭВМ (ПК, рабочих станциях). Почти все программы ОС выполняются в контексте пользовательского процесса (рис. 3.3, б). Типичный образ процесса также показан на рис. 3.3, б. При вызове системных процедур, работающих в режиме ядра, и возврата из них используется отдельный стек ядра. Код и данные ОС находятся в совместно используемом адресном пространстве и доступны для использования всеми пользовательскими процессами. Таким образом, при прерывании, включая системный вызов, переключения процессов не происходит, переключается только режим работы процессора (пользовательский <-> ядра) в рамках одного и того же процесса. В ходе процесса могут выполняться и пользовательские программы, и программы ОС. Программы ОС, выполняемые в разных пользовательских процессах, являются идентичными.
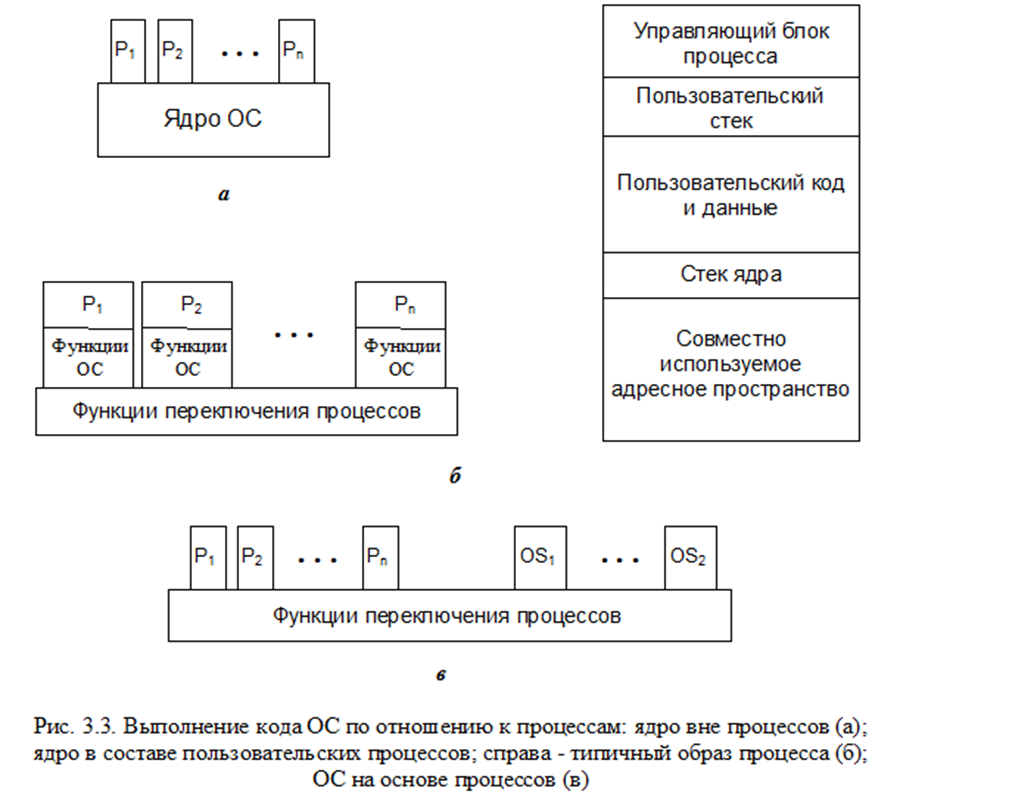
ОС на основе процессов
На рис. 3.3, в показана структура ОС на основе процессов. Преимущества такого подхода:
1) способствует разработке модульных ОС с простыми межмодульными интерфейсами;
2) некоторые второстепенные функции ОС удобно реализовывать в виде отдельных процессов; эти функции может вызывать только ОС, и такие процессы могут чередоваться с пользовательскими; в многопроцессорных и многокомпьютерных ВС отдельные службы ОС могут выполняться на разных процессорах и, соответственно, будет выше производительность системы.
Понятие потока. Сравнение процессов и потоков. Понятие, преимущества многопоточности.
Поток (thread) – это запускаемый из некоторого процесса особого рода параллельный процесс, выполняемый в том же адресном пространстве, что и процесс-родитель. Схема организации однопоточного и многопоточного процессов изображена на рис. 10.1.
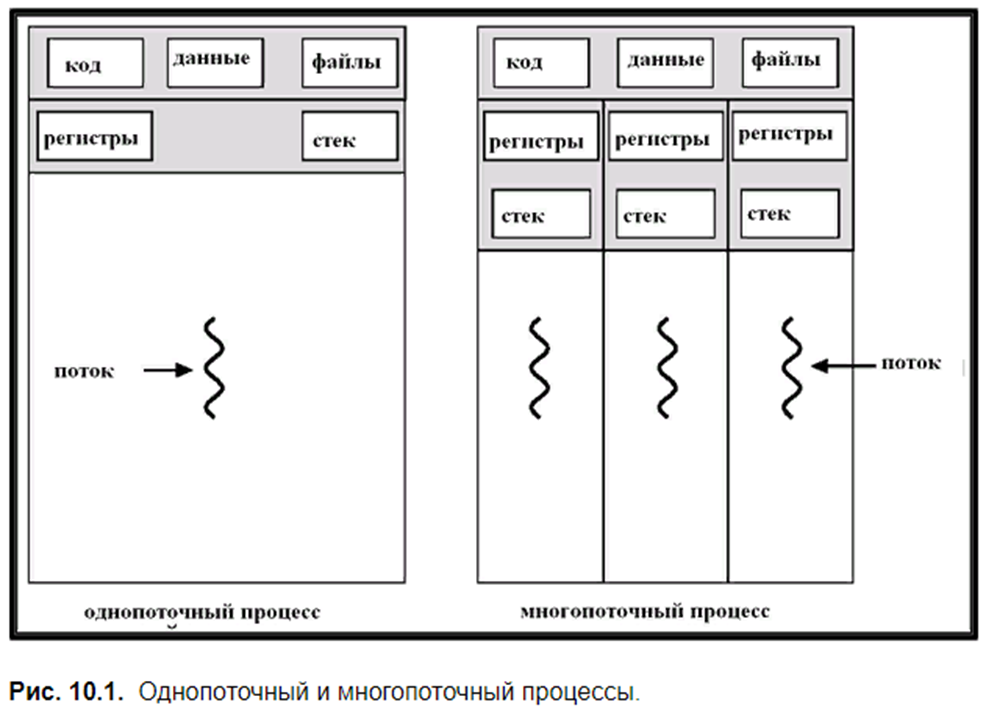
Как видно из схемы, однопоточный процесс использует, как обычно, код, данные в основной памяти и файлы, с которыми он работает. Процесс также использует определенные значения регистров и стек, на котором исполняются его процедуры.
Многопоточный процесс организован несколько сложнее. Он имеет несколько параллельных потоков, для каждого из которых ОС создает свой стек и хранит свои собственные значения регистров. Потоки работают в общей основной памяти и используют то же адресное пространство, что и процесс-родитель, а также разделяют код процесса и файлы.
Многопоточность имеет большие преимущества:
Увеличение скорости (по сравнению с использованием обычных процессов). Многопоточность основана на использовании облегченных процессов (lightweight processes), работающих в общем пространстве виртуальной памяти.
Использование общих ресурсов. Потоки одного процесса используют общую память и файлы.
Экономия. Благодаря многопоточности, достигается значительная экономия памяти, по причинам, объясненным выше. Также достигается и экономия времени, так как переключение контекста на облегченный процесс, для которого требуется только сменить стек и восстановить значения регистров, значительно быстрее, чем на обычный процесс.
Использование мультипроцессорных архитектур. Это особенно важно в настоящее время, в период широкого использования многоядерных гибридных и многопроцессорных систем. Именно многопоточность программ, основанная на многоядерности процессора, дает возможность, наконец, почувствовать реальные преимущества параллельного выполнения.
Проблемы многопоточности
Многопоточность – весьма сложная, еще не полностью изученная и, тем более, не полностью формализованная область, в которой имеется много интересных проблем. Рассмотрим некоторые из них.
Семантика системных вызовов fork() и exec(). Как уже отмечалось, в классической ОС UNIX системный вызов fork создает новый "тяжеловесный" процесс со своим адресным пространством, что значительно "дороже", чем создание потока. Однако, с целью поддержания совместимости программ снизу вверх, приходится сохранять эту семантику, а многопоточность вводить с помощью новых системных вызовов.
Прекращение потоков. Важной проблемой является проблема прекращения потоков: например, если родительский поток прекращается, то должен ли при этом прекращаться дочерний поток? Если прекращается стандартный процесс, создавший несколько потоков, то должны ли прекращаться все его потоки? Ответы на эти вопросы в разных ОС неоднозначны.
Обработка сигналов. Сигналы в UNIX – низкоуровневый механизм обработки ошибочных ситуаций. Примеры сигналов: SIGSEGV - нарушение сегментации (обращение по неверному адресу, чаще всего по нулевому); SIGKILL – сигнал процессу о выполнении команды kill его уничтожения. Пользователь может определить свою процедуру-обработчик сигнала системным вызовом signal. Проблема в следующем: как распространяются сигналы в многопоточных программах и каким потоком они должны обрабатываться? В большинстве случаев этот вопрос решается следующим образом: сигнал обрабатывается потоком, в котором он сгенерирован, и влияет на исполнение только этого потока. В более современных ОС (например, Windows 2000 и более поздних версиях Windows), основанных на объектно-ориентированной методологии, концепция сигнала заменена более высокоуровневой концепцией исключения (exception). Исключение распространяется по стеку потока в порядке, обратном порядку вызовов методов, и обрабатывается первым из них, в котором система находит подходящий обработчик. Аналогичная схема обработки исключений реализована в Java и в .NET.
Группы потоков. В сложных задачах, например, задачах моделирования, при числе разнородных потоков, возникает потребность в их структурировании и помощью концепции группы потоков – совокупности потоков, имеющей свое собственное имя, над потоками которой определены групповые операции.
Локальные данные потока (thread-local storage - TLS) – данные, принадлежащие только определенному потоку и используемые только этим потоком. Необходимость в таких данных очевидна, так как многопоточность – весьма важный метод распараллеливания решения большой задачи, при котором каждый поток работает над решением порученной ему части. Все современные операционные системы и платформы разработки программ поддерживают концепцию локальных данных потока.
Синхронизация потоков. Поскольку потоки, как и процессы (см. "Методы взаимодействия процессов ") могут использовать общие ресурсы и реагировать на общие события, необходимы средства их синхронизации.
Тупики (deadlocks) и их предотвращение. Как и процессы (см. "Методы взаимодействия процессов "), потоки могут взаимно блокировать друг друга (т.е. может создаться ситуация deadlock), при их неаккуратном программировании
Сходства
• Оба имеют идентификационный номер (id), состояние, набор регистров, приоритет и привязку
к определенной стратегии планирования
• И поток, и процесс имеют атрибуты, которые описывают их особенности для операционной системы
• Как поток, так и процесс имеют информационные блоки
• Оба разделяют ресурсы с родительским процессом
• Оба функционируют независимо от родительского процесса
• Их создатель может управлять потоком или процессом
• И поток, и процесс могут изменять свои атрибуты
• Оба могут создавать новые ресурсы
• Как поток, так и процесс не имеют доступа к ресурсам другого процесса
Различия
• Потоки разделяют адресное пространство процесса, который их создал; процессы имеют собственное адресное пространство
• Потоки имеют прямой доступ к разделу данных своего процесса; процессы имеют собственную копию раздела данных родительского процесса
• Потоки могут напрямую взаимодействовать с другими потоками своего процесса; процессы должны использовать специальный механизм межпроцессного взаимодействия для связи с «братскими» процессами
• Потоки почти не требуют системных затрат .На поддержку процессов требуются значительные затраты системных ресурсов
• Новые потоки создаются легко; новые процессы требуют дублирования родительского процесса
• Потоки могут в значительной степени управлять потоками того же процесса; процессы управляют только сыновними процессами
• Изменения, вносимые в основной поток (отмена, изменение приоритета и т.д.), могут влиять на поведение других потоков процесса; изменения, вносимые в родительский процесс, не влияют на сыновние процессы