

672
.pdfПроведем регрессионный анализ первых и последних семи наблюдений отдельно, рассчитаем квадраты остатков, таблица 3.
Таблица 3
Расчет квадратов остатков по группам, упорядоченным по Х
Наблюдения |
У |
Х |
|
Ɛi |
RSSi (Ɛi 2) |
1 |
315,63 |
286,56 |
|
17,7297 |
314,3422 |
2 |
259,33 |
403,3333 |
|
-63,8402 |
4075,573 |
3 |
333,97 |
442,6133 |
|
2,297297 |
5,277576 |
4 |
355,28 |
446,56 |
|
22,74967 |
517,5477 |
5 |
306,08 |
454,3467 |
|
-28,1358 |
791,6241 |
6 |
396,16 |
459,04 |
|
60,92827 |
3712,254 |
7 |
329,20 |
485,36 |
|
-11,7289 |
137,5674 |
Итого по первой группе (верхняя выборка) |
9554,186 |
||||
14 |
842,08 |
635,2 |
|
113,4883 |
12879,6 |
15 |
689,60 |
647,44 |
|
-44,1147 |
1946,11 |
16 |
732,21 |
664 |
|
-8,43263 |
71,10919 |
17 |
692,99 |
669,9467 |
|
-50,1483 |
2514,85 |
18 |
715,57 |
675,1467 |
|
-29,7381 |
884,3537 |
19 |
826,85 |
830,6667 |
|
16,44872 |
270,5603 |
20 |
814,59 |
834,6933 |
|
2,496681 |
6,233416 |
Итого по второй группе (нижняя выборка) |
|
18572,82 |
|||
Согласно тесту Гольдфельда-Квандта получаем:
F факт = 18572,82/9554,186 = 1,94 Fкр = 6,3
В результате F факт Fкр, на уровне значимости в 5% гипотеза об отсутствии гетероскесдастичности принимается, предпосылка о равенстве дисперсий остаточных величин не нарушается.
Аналогичный результат расчета получился с использованием Excel (таблицы 4 и 5).
Таблица 4
Дисперсионный анализ по верхней выборке
Показатель |
df |
SS |
MS |
Регрессия |
1 |
1221,598 |
1221,598 |
Остаток |
5 |
9554,186 |
1910,837 |
Итого |
6 |
10775,78 |
- |
|
80 |
|
|
Таблица 5
Дисперсионный анализ по верхней выборке
Показатель |
df |
SS |
MS |
Регрессия |
1 |
7800,826 |
7800,826 |
Остаток |
5 |
18572,82 |
3714,564 |
Итого |
6 |
26373,65 |
- |
Таким образом, согласно тесту Гольдфельда-Квандта и тесту Спирмена получаем идентичные результаты.
Вопросы для проверки и закрепления знаний
1. Дайте определение гетероскедастичности и укажите, какие стандартные предположения нарушаются?
2.Каковы причины возникновения гетероскедастично-
сти?
3.Какие могут быть последствия гетероскедастичности для оценок параметров регрессии методом наименьших квадратов и проверки статистических гипотез?
4.Какие существуют тесты для определения гетероскедастичности?
5. Какими способами можно получить корректные статистические выводы при наличии гетероскедастичности?
6.Какова методика использования в расчетах теста Спирмена?
7.Какова методика использования в расчетах теста Гольдфельда-Квандта?
Задания для проверки и закрепления знаний
Задание 1. Тестирование гетероскедастичности по Спирмену и Гольдфельду-Квандту
Исходные данные:
Имеются следующие данные, представленные в таблице 6.
81
|
|
|
Таблица 6 |
|
|
Исходные данные |
|
|
|
|
|
|
|
|
Наблюдения |
|
У |
Х |
|
1 |
|
199,49 |
310,26 |
|
2 |
|
234,15 |
400,10 |
|
3 |
|
242,79 |
220,43 |
|
4 |
|
253,23 |
373,35 |
|
5 |
|
256,90 |
340,47 |
|
6 |
|
235,45 |
349,50 |
|
7 |
|
304,74 |
353,11 |
|
8 |
|
273,29 |
343,51 |
|
9 |
|
384,70 |
401,62 |
|
10 |
|
440,27 |
408,31 |
|
11 |
|
448,57 |
405,25 |
|
12 |
|
322,65 |
417,52 |
|
13 |
|
533,07 |
515,34 |
|
14 |
|
563,24 |
510,77 |
|
15 |
|
550,44 |
519,34 |
|
16 |
|
530,46 |
498,03 |
|
17 |
|
636,86 |
461,52 |
|
18 |
|
626,61 |
642,07 |
|
19 |
|
647,75 |
488,62 |
|
20 |
|
636,04 |
638,97 |
|
Задание
1.Требуется: проверить гипотезу о наличии гетероскесдастичности в линейной регрессии с помощью теста Спирмена на уровне значимости 0,05 и 0,01.
2.Построить график зависимости остатков от фактора
Х.
3.Требуется: проверить гипотезу о наличии гетероскесдастичности в линейной регрессии с помощью теста Гольдфельда-Квандта на уровне значимости 0,05 и 0,01.
Задание 2. Тестирование гетероскедастичности по Спирмену и Гольдфельду-Квандту
Исходные данные:
Имеются данные о дисперсионном анализе выборки (всего наблюдений 20), представленном в таблицах 7 и 8.
82
Таблица 7
Дисперсионный анализ по верхней выборке
Показатель |
|
df |
SS |
MS |
|
Верхняя выборка |
|
||
Регрессия |
|
2 |
1157,837 |
578,9187 |
Остаток |
|
4 |
357,5073 |
89,37682 |
Итого |
|
6 |
1515,345 |
|
|
Нижняя выборка |
|
||
Регрессия |
|
2 |
1884,397 |
942,1986 |
Остаток |
|
4 |
1824,397 |
456,0992 |
Итого |
|
6 |
3708,794 |
|
Имеются также данные по регрессионной статистике, таблица 8.
Таблица 8
Результаты регрессионной статистики по выборкам
Переменные |
Коэффициенты |
Стандартная ошибка |
t-статистика |
P-Значение |
Нижние 95% |
Верхние 95% |
Нижние 95,0% |
Верхние 95,0% |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Верхняя выборка |
|
|
|
|||
Y- |
|
|
|
|
|
|
|
|
|
пере- |
-34,303 |
44,710 |
-0,767 |
0,486 |
-158,437 |
89,831 |
-158,437 |
89,831 |
|
сече- |
|||||||||
|
|
|
|
|
|
|
|
||
ние |
|
|
|
|
|
|
|
|
|
X1 |
0,641 |
0,202 |
3,177 |
0,034 |
0,081 |
1,202 |
0,081 |
1,202 |
|
X2 |
1132,054 |
340,824 |
3,322 |
0,029 |
185,775 |
2078,334 |
185,775 |
2078,334 |
|
|
|
|
Нижняя выборка |
|
|
|
|||
Y- |
|
|
|
|
|
|
|
|
|
пере- |
213,602 |
78,308 |
2,728 |
0,053 |
-3,817 |
431,021 |
-3,817 |
431,021 |
|
сече- |
|||||||||
|
|
|
|
|
|
|
|
||
ние |
|
|
|
|
|
|
|
|
|
X1 |
0,577 |
0,296 |
1,952 |
0,123 |
-0,244 |
1,398 |
-0,244 |
1,398 |
|
|
-1106,870 |
842,418 |
-1,314 |
0,259 |
- |
1232,055 |
- |
1232,055 |
|
X2 |
3445,800 |
3445,800 |
|||||||
|
|
|
|
|
|
||||
Задание
1.Требуется: определить по каким уравнениям линейной регрессии осуществляется дисперсионный анализ.
2.Требуется: проверить гипотезу о наличии гетероскесдастичности в линейной регрессии с помощью теста Гольдфельда-Квандта на уровне значимости 0,05.
83
Задание 3. Тестирование гетероскедастичности по Спирмену и Гольдфельду-Квандту
Исходные данные:
Имеются следующие данные, представленные в таблице 9.
Таблица 9
Исходные данные
№ |
Y |
Х1 |
Х2 |
1 |
280,51 |
254,68 |
0,17 |
2 |
230,48 |
358,46 |
0,09 |
3 |
296,82 |
393,37 |
0,09 |
4 |
315,76 |
396,88 |
0,14 |
5 |
272,03 |
403,80 |
0,09 |
6 |
352,09 |
407,97 |
0,14 |
7 |
292,58 |
431,36 |
0,07 |
8 |
270,54 |
462,27 |
0,12 |
9 |
444,47 |
464,02 |
0,17 |
10 |
518,27 |
468,22 |
0,14 |
11 |
508,67 |
471,75 |
0,21 |
12 |
372,78 |
482,39 |
0,07 |
13 |
735,81 |
533,23 |
0,17 |
14 |
748,40 |
564,53 |
0,14 |
15 |
612,88 |
575,41 |
0,19 |
16 |
650,75 |
590,13 |
0,14 |
17 |
615,89 |
595,42 |
0,17 |
18 |
635,97 |
600,04 |
0,21 |
19 |
734,87 |
738,26 |
0,19 |
20 |
723,96 |
741,83 |
0,19 |
Задание
3.Требуется: проверить гипотезу о наличии гетероскесдастичности в линейной регрессии с помощью теста Спирмена на уровне значимости 0,05 и 0,01.
4.Построить график зависимости остатков от фактора Х.
5.Требуется: проверить гипотезу о наличии гетероскесдастичности в линейной регрессии с помощью теста Гольдфельда-Квандта на уровне значимости 0,05 и 0,01.
84
7. Учет автокоррелированности ошибок
7.1. Понятия и последствия автокорреляции
Для статистических данных, развернутых во времени (временные ряды) возможно наличие нарушений стандартных предположений в виде автокоррелированности (сери-
альной корреляции) ошибок (autocorrelation, serial correlation).
Взаимная независимость возмущений также является условием успешного проведения регрессионного анализа и получения качественной модели. Для этого необходима независимость возмущений, т. е. r (Ɛi, Ɛj) = cov (Ɛi, Ɛj) =0, i≠j.
Под автокорреляцией понимается корреляция между наблюдаемыми показателями. Такое явление связано с использованием данных временных рядов. Поэтому, как привило используется символ t, вместо i, для отражения периода наблюдения.
Ожидаемые последствия наличия автокорреляции, следующие:
1.Метод наименьших квадратов обеспечивает несмещенные оценки параметров;
2.Следствием заниженности оценок стандартных отклонений коэффициентов является завышенность t – статистик;
3.Оценки МНК для стандартных отклонений будут заниженными;
4.Оценка дисперсии возмущений смещена, следовательно, параметры регрессии не эффективны.
Если автокорреляция присутствует, то наибольшее влияние на наблюдение оказывает результат предыдущего наблюдения, это называется автокорреляцией первого порядка. Если корреляция между соседними наблюдениями отсутствует, то МНК даст адекватные и эффективные результаты.
85
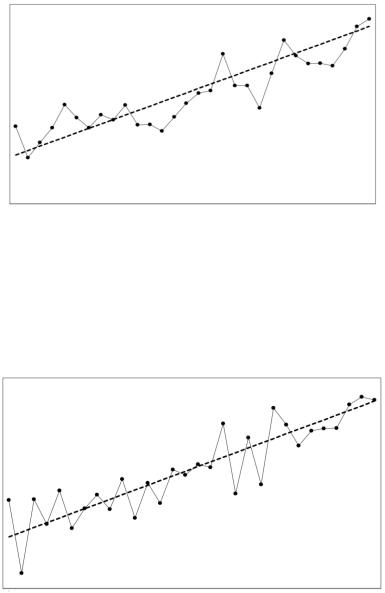
Положительная автокорреляция сопровождается записью r (Ɛt-1, Ɛt)>0. Графически положительная автокореляция выглядит так, как представлено на рисунке 1.
Рисунок 1. Положительная автокорреляция
Отрицательная автокорреляция характеризуется записью r (Ɛt-1, Ɛt) 0. Это значит, что за положительным возмущением следует отрицательное и наоборот. Графически это представлено рисунком 2.
Рисунок 2. Отрицательная автокорреляция
Основными причинами автокорреляции можно назвать следующие:
1. Ошибки спецификации. Неправильный выбор формы зависимости или невключение в состав объясняющих переменных какого-либо важного фактора может привести к систематическим отклонениям наблюдаемых значений показателя от линии регрессии. Неправильный выбор модели, либо
86
как отбрасывание значимой переменной также приводит к такому результату.
2.Сглаживание данных. Данные по продолжительному временному периоду времен рассчитаны усреднением по интервалам, что приводит к сглаживанию возникших колебаний внутри исследуемого периода.
3.Инерция. Зачастую экономические показатели имеют свойство цикличности или их реакция на изменение условий имеет определенный временной лаг.
Простейшей моделью автокорреляции ошибок является следующая:
Ɛt = r Ɛt-1+ut, i=1,….,n,
где |r | 1, а ut, i=1,2….,n – независимые в совокупности случайные величины, имеющие одно и то же нормальное распределение.
Следовательно, r - коэффициент корреляции между двумя соседними случайными величинами Ɛt и Ɛt-1.
Тогда можно сделать следующую интерпретацию полученных значений r:
r>0 – автокорреляция положительная; r 0 - автокорреляция отрицательная; r =0- автокорреляция отсутствует.
Коэффициент автокорреляции остатков первого порядка рассчитывается по формуле:
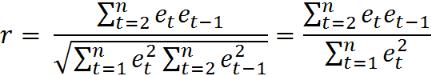 .
.
7.2. Методы обнаружения автокорреляции
Существует несколько вариантов обнаружения автокорреляции.
1. Графический метод. Для этого необходимо построить
87
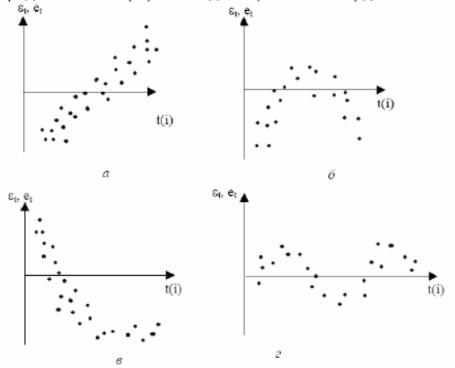
график остатков, в которых по оси абсцисс откладываются моменты (или порядковые номера) наблюдений, а по оси ординат — остатки (рисунок 3).
Рисунок 3. Варианты поведения данных в зависимости от периода
Согласно изображенным данным на рисунке, видно, что
ввариантах а, б, в возможно наличие автокорреляции.
2.Критерий Дарбина-Уотсона. Статистика ДарбинаУотсона (DW) предусмотрена во многих программных продуктах, как важнейшая характеристика качества регрессионной модели. Для установления автокорреляции используется следующая формула:
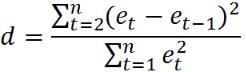 .
.
Эта статистика тесно связана с выборочным коэффициентом корреляции между соседними остатками (коэффициен-
88
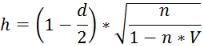
том автокорреляции первого порядка, т е. парного коэффициента корреляции между рядами):
d 2 (1-r).
Интерпретация полученных значений следующая:
1.Если автокорреляция отсутствует, то d 0;
2.Если автокорреляция положительная, то 0 d ≤ 2;
3.Если автокорреляция отрицательная, то 2 d ≤ 4. Величину критерия вычислим по формуле:
где n - число наблюдений в модели;
V - квадрат стандартной ошибки при лаговой результативной переменной У t-1.
Проверка гипотезы осуществляется с помощью таблицы критических значений Дарбина -Уотсона: dU = dU (α, k, n) и d1 = d1 (α, k, n), которые определяются по значениям входных параметров α, k, n (приложение 4)
При проверке гипотезы Н0:r = 0 против гипотезы H1*: r > 0 гипотеза об отсутствии автокорреляции первого порядка принимается, если выполняется неравенство dвыч > dU (α, k, n) и гипотеза отклоняется в пользу альтернативной, если dвыч dL (α, k, n).
При проверке гипотезы Н0:r = 0 против гипотезы H1*: r <0 гипотеза об отсутствии автокорреляции первого порядка принимается, если выполняется неравенcтво dвыч 4- dU (α, k, n); гипотеза отклоняется, если dвыч> 4- dU (α, k, n).
При проверке гипотезы Н0:r = 0 против гипотезы H1*: r ≠ 0 гипотеза об отсутствии автокорреляции первого порядка принимается, если выполняется неравенcтво 4- dU (α/2, k, n) > dвыч > dU (α/2, k, n); гипотеза отклоняется, если dвыч> 4- dL (α/2, k, n) или dвыч dL (α/2, k, n).
89