

МИНИСТЕРСТВО НАУКИ И ВЫСШЕГО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
федеральное государственное автономное образовательное учреждение высшего образования
«САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ АЭРОКОСМИЧЕСКОГО ПРИБОРОСТРОЕНИЯ»
ИНСТИТУТ НЕПРЕРЫВНОГО И ДИСТАНЦИОННОГО ОБРАЗОВАНИЯ
КАФЕДРА 41
|
ОЦЕНКА
ПРЕПОДАВАТЕЛЬ
канд. физ-мат наук, доцент |
|
|
|
Е. А. Яковлева |
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
КОНТРОЛЬНАЯ РАБОТА
|
ПРИМЕНЕНИЕ СТАТИСТИЧЕСКИХ МЕТОДОВ ОБРАБОТКИ ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
|
по дисциплине: СТАТИСТИЧЕСКАЯ ОБРАБОТКА ИНФОРМАЦИИ |
РАБОТУ ВЫПОЛНИЛ
СТУДЕНТ ГР. № |
Z9411 |
|
|
|
Р. С. Кафка |
|
номер группы |
|
подпись, дата |
|
инициалы, фамилия |
Студенческий билет № |
2019/3603 |
|
|
|
|
Шифр ИНДО |
|
Санкт-Петербург 2023
Исходные данные для задания 2 и 3.
m=1
n=4
Выполнения задания 2.
В программной среде Excel заполняется столбец исходных данных рис. 1. Имеются следующие выборочные данные (выборка 10%-ная, механическая) о выпуске продукции и сумме прибыли, млн. руб.:
 Рисунок
1 – Данные о выпуске продукции и сумме
прибыли
Рисунок
1 – Данные о выпуске продукции и сумме
прибыли
Выполняется сортировка столбца C - прибыль ряда в порядке возрастания. В результате получен новый интервальный ранжированный ряд рис.2.
 Рисунок
2 – Сортировка данных по прибыли
Рисунок
2 – Сортировка данных по прибыли
Определяются частоты и частости нового ряда. Для этого используется данные об объеме совокупности исследуемых предприятий N = 25. Дискретный вариационный ряд разбивается на интервалы, число которых подсчитывается по формуле Стержесса

в которой квадратные скобки означают округление числа 5,91, тогда k = 5. Длина частичного интервала определяется по формуле

Размах =
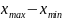
Среднее значение = сумма x / кол-во измерений (25). Воспользовался функцией Excel «СРЗНАЧ()» чтобы найти его.
Медиану нашли по значению по середине таблицы. При этом на середине лежало 2 числа: 16,2 и 16,3. В этом случае их сложил и разделил на 2.
Мода – в результатах встречается 3 раза повторяющиеся значения по 2 раза (3 дублета).
 Рисунок
3 – Данные, полученные из таблицы
Рисунок
3 – Данные, полученные из таблицы
 Тогда границы
интервалов будут такими:
Тогда границы
интервалов будут такими:
x0= =10
=10
x1=
x2=
x3=
x4=
x5=
Подсчитывается количество предприятий, принадлежащих каждому из интервалов. Вычисляется накопленная частота и процентное отношение частоты к общему объему всей совокупности N = 30 или частость.
 Рисунок
3 – Статистический ряд распределения
предприятий
Рисунок
3 – Статистический ряд распределения
предприятий
Значения были найдены следующим образом:
Частность: Кол-во предприятий (n) / общее количество предприятий (N) * 100%
Середина интервала: (Начало интервала + Конец интервала) / 2
По данной таблице построил следующие графики (рис.4-6)
 Рисунок
4 – Кривая ненормированной плотности
распределения
Рисунок
4 – Кривая ненормированной плотности
распределения
 Рисунок
5 – Кумулятивная кривая накопленных
частот
Рисунок
5 – Кумулятивная кривая накопленных
частот
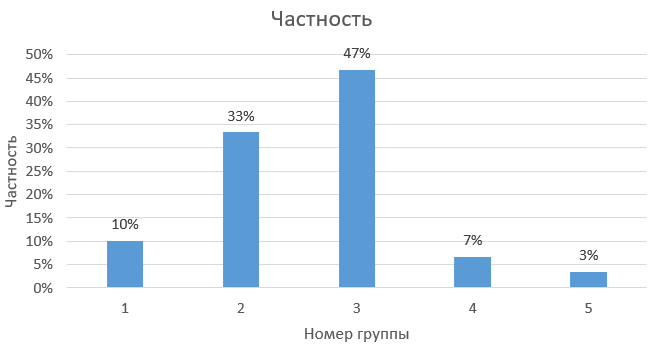 Рисунок
6 – Гистограмма
Рисунок
6 – Гистограмма
Используя χ2-критерий Пирсона, при уровне значимости α=0,05 проверил гипотезу о том, что случайная величина X – сумма прибыли – распределена по нормальному закону.
Сначала рассчитаем среднее значение сгруппированного ряда, дисперсию и среднее квадратичное отклонение.
Среднее значение
сгруппированного ряда =

Дисперсия =
 ;
;
Среднее квадратичное
отклонение =

Результат расчётов представлен на рисунке 7.
 Рисунок
7 – Расчёт среднего значения сгруппированного
ряда, дисперсии и сигмы
Рисунок
7 – Расчёт среднего значения сгруппированного
ряда, дисперсии и сигмы
Затем была создана новая таблица, в которую перенесли из предыдущей номера групп и количество элементов(предприятий) в каждой группе.
Опираясь на данные сведения, вычислим следующие характеристики:
-
 ,
где
,
где
 и σ = 2,638;
и σ = 2,638;
- функция Гаусса:
 ;
;
-
 ,
где N = 30 и h
= 3;
,
где N = 30 и h
= 3;
-
 .
.
Получим таблицу, представленную на рисунке 8.
 Рисунок
8 – Таблица для проверки распределения
по нормальному закону
Рисунок
8 – Таблица для проверки распределения
по нормальному закону
Сравним полученные результаты с теоретическими, используя критерий Пирсона:
 .
.
По таблице критических точек распределения χ2 по уровню значимости α = 0,05 и числу степеней свободы k = 5 - 2 - 1 = 2, находим χ2кр = 6.
Так как:
χ2набл = 2,61094,
χ2кр = 6,
χ2набл < χ2кр
то выходит, что наша гипотеза о нормальном распределении выполняется с данными результатами.
Установил наличие и характер корреляционной связи между стоимостью произведённой продукции (X) и суммой прибыли на одно предприятие (y). Построил диаграмму рассеяния и линию регрессии.
Используя изначальные данные для 2-го задания – отсортировал значения по выпуске продукции и обозначил их за «x», прибыль обозначил за «y».
С помощью стандартной надстройки Excel «Пакет анализа» построил точечную диаграмму по x и y, построил линейную линию тренда, включил показ уравнения на диаграмме и поместил на диаграмму величину достоверности аппроксимации (R2). Результат представлен на рисунке 9.
 Рисунок
9 – Поле корреляции
Рисунок
9 – Поле корреляции
Получилось выборочное уравнение регрессии: y=0,0539x+12,589. R2=0.1393.
Коэффициент детерминации показывает, какая доля дисперсии результативного признака объясняется влиянием независимых переменных.
Коэффициент детерминации получился довольно слабым. Для того чтобы улучшить результаты удалим сильно отдалённые результаты от линии тренда – так называемые «выбросы», которые портят график. В результате получилась таблица, представленная на рисунке 10.
 Рисунок
10 – Поле корреляции после удаления
выбросов
Рисунок
10 – Поле корреляции после удаления
выбросов
Теперь выборочное уравнение регрессии: y = 0,1116x+8,2421. Коэффициент детерминации R2=0,8821.
a = 8,2421
b = 0,1116
Коэффициент детерминации объясняет 88,21% переменных, объясняемые рассматриваемым уравнением.
Рассчитал линейный коэффициент корреляции.
Линейный коэффициент
корреляции:

Таким образом,
линейная связь между выпуском продукции
и величиной прибыли весьма сильная,
т.к.
 .
.
Благодаря
вычислительным возможностям функции
Анализ данных, в программе были найдены
предсказанные значения
 и остатки (y-
).
На основе этих сведений были построены
следующие графики:
и остатки (y-
).
На основе этих сведений были построены
следующие графики:
 Рисунок
11 - Распределение заданных значений y
и предсказанных значений
Рисунок
11 - Распределение заданных значений y
и предсказанных значений
 Рисунок
12 - Распределение остаточных значений
(y-
)
Рисунок
12 - Распределение остаточных значений
(y-
)
Охарактеризуем статистическую надежность результатов регрессионного анализа с использованием F-критерия Фишера при уровне значимости α = 0,05.
Найдём расчетное значение критерия:
 .
.
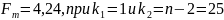
Сравнив это значение с табличным получается, что:

Следовательно, уравнение регрессии является статистически значимым, надежным.
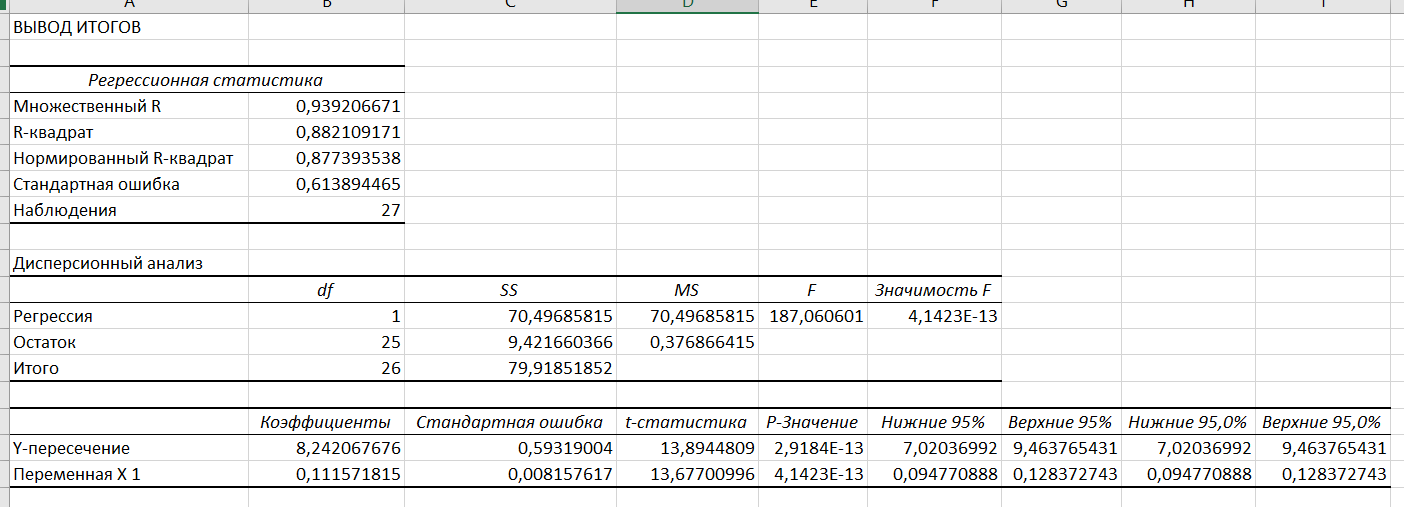 Рисунок
13 – Вывод итогов регрессии
Рисунок
13 – Вывод итогов регрессии
Коэффициент a является достоверным, если он лежит в промежутке (7,02036992, 9,463765431).
Коэффициент b является достоверным, если он лежит в промежутке (0,094770888, 0,128372743).
Найдём расчетную
величину средней ошибки аппроксимации
E по формуле
 .
.
Значение очень малое, что свидетельствует о хорошо проработанной модели уравнения.
 Рисунок
14 – Вывод остатка
Рисунок
14 – Вывод остатка
Вывод:
В заключение следует отметить, что задача по анализу данных о прибыли выборки из 30 предприятий с помощью программы Excel и статистических методов была выполнена. Данные были отсортированы, определены частоты и интервалы, рассчитаны различные статистические показатели, такие как диапазон, среднее, медиана и мода.
Гипотеза о нормальном распределении данных была проверена с помощью χ2-критерия Пирсона, и она была признана удовлетворительной при уровне значимости α = 0,05. χ2набл < χ2кр
Также были рассчитаны
среднее значение, дисперсия и стандартное
отклонение сгруппированных данных.
,

 .
.
Корреляция между стоимостью продукции и прибылью также была определена как положительная и сильная, т.к. график растёт и коэффициент корреляции r=0,939 что указывает на сильную связь между этими двумя переменными, т.к. 0,939 > 0,7.
Уравнение регрессии: y = 0,1116x+8,2421.
Расчётный F-критерия
Фишера
 оказался больше табличного значения
оказался больше табличного значения
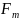 ,
что свидетельствует о том, что уравнение
регрессии является статистически
значимым, надежным.
,
что свидетельствует о том, что уравнение
регрессии является статистически
значимым, надежным.
Ошибка аппроксимации E = 2,93%, что свидетельствует о хорошо проработанной модели уравнения.
В целом, задача была успешно решена, поскольку был проведен тщательный анализ данных о прибыли по выборке предприятий.
Задание 3.
Вариант 3 - Месяц 3 - Годы 1986-2010
 Рисунок
15 – Данные о температуре поверхности
океана
Рисунок
15 – Данные о температуре поверхности
океана
Выделение и анализ тренда временного ряда.
с помощью метода наименьших квадратов рассчитать линейное уравнение трендовой составляющей
Т(t) = a0 +a1
где t – время.
Задача - построить график распределения температуры на основе исходных данных. Мы наложим линию регрессии на отмеченные значения и выразим уравнение построенной линии.
 Рисунок
15 – График распределения температуры
Рисунок
15 – График распределения температуры
Как видно из приведенного выше рисунка, анализ ряда этим методом не дает удовлетворительных результатов.
вычислить коэффициент корреляции (r), его стандартную ошибку (σr), коэффициент детерминации (R2=r2 ), который показывает вклад тренда в описание дисперсии исходного ряда.
Будем копировать значения из таблицы – первый ряд без последнего результата, второй ряд рядом – без первого результата. Далее первый ряд без последних двух результатов, второй ряд рядом – без первых двух результатов и так далее. В результате чего получится несколько «дублетов» таких рядов без первых и последних значений.
Для каждых из этих «дублетов» рядов определяем коэффициент корреляции с помощью стандартного пакета анализа в Excel.
 Рисунок
16 – Дублеты рядов
Рисунок
16 – Дублеты рядов
В результате было найдено 12 коэффициентов корреляции. Заносим их в один столбец, строим график и ищем вершины (максимумы) для определения наиболее подходящего значения амплитуды.
В данном случае наиболее подходящий период колебаний равен 12.
 Рисунок
17 – Определение периода колебаний
Рисунок
17 – Определение периода колебаний