

Современные методы построения языковых моделей.
Вложение слов: word2vec, glove.
Word2vec — метод эффективного создания вложений. Сначала обрабатываем текст, создаем словарь, создаем 2 матрицы Embedding и Context. В этих матрицах хранятся вложения для каждого слова в нашем словаре. Размерность вложения задаем сами. Начинаем процесс обучения. На каждом этапе берём один положительный пример и связанные с ним отрицательные, т.е. входное слово «х» и выходные контекстные слова «у», среди которых только одно положительное. Ищем вложения для «х» в Embedding и для «у» в Context. Вычислим произведение входного вложения на каждое контекстное, превращаем их в вер-ти (от 0 до 1). Получаем разности:
у одного положительного контекста (1-вер-ть).
У остальных отрицательных (0-вер-ть).
Пишем эту оценку в таблицу Context. Пройдемся так по всем словам словаря и получим улучшенную таблицу.
Glove - пытаемся приблизить матрицу встречаемости. Берем слово «а» и 2 случайных контекстных слова «б» и «в», смотрим вер-ть встречи контекстных слов, вычисляем вер-ть встречи пар p(а, б) и р(а,в), получим их частное и пишем в матрицу встречаемости.
Рекуррентные нейронные сети.
Рекуррентные нейронные сети – вид нейронных сетей, где связи между элементами образуют направленную пос-ть. Можно обрабатывать серию событий во времени или последовательные цепочки. Слово представляется как вектор определенной размерности (от 50 до 300 в зависимости от задачи). Это удобно использовать как вход для нейронных сетей.
Механизм внимания.
Механизм влияния помогает избежать проблемы смены порядка слов при переводе с одного языка на другой. Он выявляет закономерность между входными и выходными данными.
Машинное обучение в ранжирование.
Факторы для ранжирования на примере Google.
Факторы домена:
– Возраст домена
– чем старше, тем лучше
– История домена
– какие были сайты на этом домене
– Привязка к стране
– Публичный или приватный whois
– Ключевое слово в домене
– Ключевое слово в поддомене
– Оштрафован ли владелец whois
– Длительность регистрации домена
Факторы оптимизации сайта
– Ключевые слова в h1, h2, h3, h4, url, title, meta
– Размер страниц
– Уникальность наполнения
– Исходящие ссылки
– Видео и фото на сайте
– Скорость загрузки
– Битые ссылки
– Правильность html
– Частота обновления
Факторы уровня сайта
– Уникальность сайта
– Обновления сайта
– Наличие карты сайта
– Место нахождение сервера
– Наличие обратной связи
– Количество страниц
– Юзабилити сайта
– Доступность сайта
– как часто сайт находится не техобслуживании или подобном
– Удобство навигации
Поточечный подход для ранжирования.
Поточечный подход – каждой паре число-документ нужно присвоить число, по которому будет сортировать.
Попарный подход для ранжирования, алгоритмы RankNet, FRank, SVMRank, SortNet.
Попарный подход – тройка: два документа и запрос, для них определяем порядок, какой из документов лучше подходит. Подходит, когда мы не можем однозначно присвоить число.
Алгоритм RankNet. Пусть p(i,j) – вер-ть того, что i документ выше j, p_active(i,j) – наблюдаемая величина (0 или 1). Тогда:
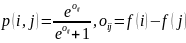
Функция потерь будет выглядеть так:
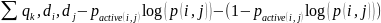
Алгоритм Frank. Уменьшаем диапазон вер-ти с [0,1] до [1e-5,1-1e-5]. Функция потерь будет выглядеть так:
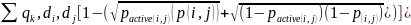
Алгоритм SVMRank. Пусть есть прямая, разделяющая 2 множества – релевантные слова и нет. Для каждой точки вводим положительный штраф ξi , их сумму стараемся минимизировать.
Недостатки попарного подхода и их исправления.
Не учитывают количество документов на уровне запроса – есть 2 запроса, в одном нашлось много правильных документов, в другом документов вообще мало и все неправильные. Если используем попарный подход напрямую – получаем неправильную среднюю точность
Нужно дополнительно настраивать попарный подход, чтобы избежать этих проблем