

Алгоритм стохастического градиентного спуска для обучения нейронных сетей
Стохастический градиентный спуск – итерационный метод для оптимизации целевой функции с подходящими свойствами гладкости (например, дифференцируемость или субдифференцируемость).
При наличии достаточно большого тренировочного набора, вычислять функцию ошибки по всем элементам этого набора, задача весьма затратная по ресурсам. Поэтому разобьём набор на K частей (minibatch) размера M:
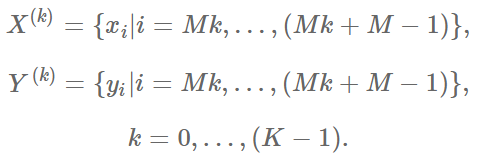
определим функции:
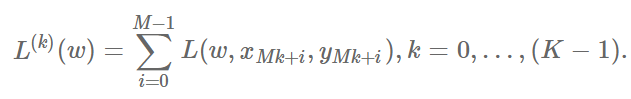
И вместо одной итерации градиентного спуска у нас появляется набор из K мини-итераций вида:
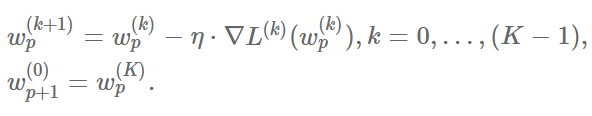
Каждую “большую” итерацию (p=0,1,2,…), когда мы проходим весь набор, будем называть эпохой (epoch). Между эпохами тренировочный набор перемешивается, чтобы элементы попадали в разные минибатчи в разных эпохах. Таким образом, L^(k)(w) вообще говоря суммируются по разным поднаборам X,Y для разных эпох (при фиксированном k).
Метод стохастического градиентного спуска, позволяет решить проблему требовательности к ресурсам обычного градиентного спуска, однако, ставит много новых вопросов, например, какого размера выбирать минибатчи.

Как инициализируют веса в нейронных сетях? Что такое проблема затухающих и взрывающихся градиентов? Что такое инициализация Хе (Кайминга) и Ксавье?
Принцип выбора начальных значений весов для слоев, составляющих модель очень важен: установка всех весов в 0 будет серьезным препятствием для обучения, так как ни один из весов изначально не будет активен. Присваивать весам значения из интервала [−1,1] — тоже обычно не лучший вариант — на самом деле, иногда (в зависимости от задачи и сложности модели) от правильной инициализации модели может зависеть, достигнет она высочайшей производительности или вообще не будет сходиться. Даже если задача не предполагает такой крайности, удачно выбранный способ инициализации весов может значительно влиять на способность модели к обучению, так как он предустанавливает параметры модели с учетом функции потерь.
Всегда можно выбрать случайно начальное приближение, но лучше выбирать определённым образом, ниже приведены самые распространённые из них:
Метод инициализации Завьера (Xavier) (иногда — метод Glorot’а). Основная идея этого метода — упростить прохождение сигнала через слой во время как прямого, так и обратного распространения ошибки для линейной функции активации (этот метод также хорошо работает для сигмоидной функции, так как участок, где она ненасыщена, также имеет линейный характер). При вычислении весов этот метод опирается на вероятностное распределение (равномерное или нормальное) с дисперсией, равной Var(W) = 2 / (n_in + n_out), где n_in и n_out – количества нейронов в предыдущем и последующем слоях соответственно;
Метод инициализации Ге (He) — вариация метода Завьера, больше подходящая функции активации ReLU, компенсирующая тот факт, что эта функция возвращает нуль для половины области определения. А именно, в этом случае Var(W) = 2 / n_in.

>проблема затухающих и взрывающихся градиентов
Напомним, что градиентом в нейронных сетях называется вектор частных производных функции потерь по весам нейронной сети. Таким образом, он указывает на направление наибольшего роста этой функции для всех весов по совокупности. Градиент считается в процессе тренировки нейронной сети и используется в оптимизаторе весов для улучшения качества модели.
В процессе обратного распространения ошибки при прохождении через слои нейронной сети в элементах градиента могут накапливаться большие значения, что будет приводить к сильным изменениям весов. Это в свою очередь может сделать нестабильным алгоритм обучения нейронной сети. В таком случае элементы градиента могут переполнить тип данных, в котором они хранятся. Такое явление называется взрывающимся градиентом.
Существует аналогичная обратная проблема, когда в процессе обучения при обратном распространении ошибки через слои нейронной сети градиент становится все меньше. Это приводит к тому, что веса при обновлении изменяются на слишком малые значения, и обучение проходит неэффективно или останавливается, то есть алгоритм обучения не сходится. Это явление называется затухающим градиентом.
Таким образом, увеличение числа слоев нейронной сети с одной стороны увеличивает ее способности к обучению и расширяет ее возможности, но с другой стороны может порождать данную проблему.