

4.2. Обоснование состава множества информативных характеристик
Выбор информативных ВХ случайных величин Gi должен производиться с учетом двух основных факторов:
выбранные ВХ должны существенно изменять свои значения при наличии в программе РПС;
ВХ должны относительно легко вычисляться при экспериментальных исследованиях программы.
Поскольку информативные характеристики должны реагировать на наличие в программе закладок, изменяющих основной алгоритм функционирования или инициирующих изменение исходных данных (промежуточных или конечных результатов), следовательно, необходимо определить класс функций, которые получаются из исходной под воздействием программной закладки. К сожалению, РПС сами нуждаются в дополнительном исследовании и классификации, могут искажать реализуемую функцию в таком широком диапазоне, что однозначно предсказать ее искаженный вид просто невозможно. Поэтому для количественной оценки информативности той или иной ВХ целесообразно хотя бы приблизительно определить ожидаемый вариант воздействия дефекта на исследуемую программу.
С точки зрения удобства экспериментального вычисления наиболее простой характеристикой является значение функции распределения в одной точке. Вычисление этой характеристики сводится к подсчету значений выходной величины, попавших в заданный интервал. Вычисление этой ВХ для тех контрольных точек программы, где критерием перехода на ту или иную ветвь является значение функции, сводится к подсчету числа прохождений по этим ветвям. Например, экспериментальные исследования программ, входящих в специальное ПО, реализующего комбинационные алгоритмы выбора предпочтений, показали, что для программ такого класса частота прохождения различных ветвей при заданном законе распределения входных данных является достаточно устойчивой информативной характеристикой. Если при этом еще фиксировать временные интервалы прохождения различных путей программы, которые могут существенно отличаться друг от друга, то время выполнения также может использоваться в качестве информативной характеристики.
Для вычислительных программ, обладающих достаточно простой ациклической структурой, но реализующих сложные вычислительные функции, например, вычисления полиномов различной степени в приближенных расчетах, в качестве вероятностных характеристик могут использоваться начальные моменты законов распределения входных данных

где yi - значения входной величины при i-том испытании (прогоне программы);
mk* - начальный момент, полученный при проверке программы;
n - число прогонов программы.
4.3. Алгоритмы приближенных вычислений вероятностных характеристик наличия в программах рпс
В основу алгоритмов приближенных вычислений ВХ положен принцип расчета ВХ по функциям распределения выходных и промежуточных величин. При этом законы их распределения вычисляются как распределения функции от случайных аргументов.
Задача функционального преобразования непрерывных случайных величин формируется следующим образом.
Дано: совместная плотность распределения вероятностей wn(x1,...,xn) непрерывных случайных величин 1,...,n и совокупность функций f1,...,fm от n переменных. С помощью этих функций определены m случайных величин h1=f1(x1,...,xn),...,hm=fm(x1,...,xn), где xi – значения случайных величин i.
Необходимо: определить закон распределения каждой полученной случайной величины hj и их совместную плотность Wm(y1,...,ym), где yi - значения случайных величин hj.
Решение этой задачи точными методами даже для одномерного случая возможно только при жестких ограничениях на вид функции и закон распределения аргумента. Например, применение метода обратной функции требует вычисления на каждом участке монотонности f(x) обратной функции и производной от обратной функции.
Вычисление W(y) методом характеристической функции ограничено таким набором w(x) и f(x), для которых можно вычислить характеристическую функцию в явном виде, а по характеристической функции вычислить W(y).
В связи с этим целесообразно воспользоваться приближенным методом, сущность которого заключается в вычислении некоторых характеристик закона распределения и по ним восстановлении всего закона распределения. В качестве таких характеристик можно взять начальные моменты закона распределения:
mk(h)= ...
f(x1,...,xn)kw(x1,...,xn) dx1...dxn
...
f(x1,...,xn)kw(x1,...,xn) dx1...dxn
или для одномерного случая h=f(x)
mk(h)= f(x)kw(x) dx
при условии, что этот интеграл сходится абсолютно.
Поскольку данный
методический подход возможен практически
для любых вычислительных алгоритмов,
то для иллюстрации его реализуемости
можно ограничиться классом функций,
представимых конечным степенным рядом.
В этом случае еслиf(x)= (общий вид), то определение первых t=r/N
моментов случайных величин h=f(k)
выполняется по следующему алгоритму
(r
– число первых начальных моментов
закона распределения w(x),
принимающих значения m1(),...,mr()).
(общий вид), то определение первых t=r/N
моментов случайных величин h=f(k)
выполняется по следующему алгоритму
(r
– число первых начальных моментов
закона распределения w(x),
принимающих значения m1(),...,mr()).
Алгоритм A
А1. i:=1.
А2. Вычислить
значения bj,
j=1,...,N
полинома f(x)i
путем перемножения f(x)i
и f(x)i-1:
если f(x)= и f(x)i-1=
и f(x)i-1= ,
то bj=
,
то bj= .
.
А3. Вычислить
mi(h)=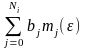 .
.
А4. i:=i+1.
А5. Если ir/N, то переход на п.А2. В противном случае алгоритм завершается.
Кроме рассмотренного, возможно применение алгоритмов реализующих методы вычисления моментов функции от случайных величин с использованием моментопроизводящих или кумулянтных функций.
Задача вычисления закона распределения F(y) в заданной точке y0 по L моментам формулируется следующим образом.
Дано:mi, i=1,...,L - начальные моменты F(y).
Необходимо: определить значения sup F(y0) и inf F(y0).
Метод вычисления sup F(y0) и inf F(y0) по известным начальным моментам F(y) описан в. Алгоритм вычисления sup F(y0) и inf F(y0) для L=2k-1, k=1,2..., и известных а и b – конечных значений y, меньше и больше которых соответственно значения функции принимать не могут, реализуют данный метод с некоторыми модификациями.
Алгоритм Б
Б1. Сформировать
ряд «подходящих» дробей к интегралу

Б2. Преобразовать «подходящую дробь» в непрерывную вида
 .
.
Б3. Привести непрерывную дробь к дробно рациональному виду L(z)/L(z).
Б4. Выполнить пункты Б2 и Б3 для L=L-1 и вычислить L-1(z)/L-1(z).
Б5. Определить
функцию
 .
.
Б6.Определить вещественные корни полинома 1(z).
Б7. Вычисление
интеграла
 с помощью вычетов. При этом inf F(y0)
будет равно сумме вычетов 0(z)/1(z)
для всех y,y0,
а sup F(y0),
будет равно сумме inf F(y0)
и очередного вычета. Среднее значение
Fср(y0)=(sup F(y0)+inf F(y0))/2
и значение =(sup F(y0)+inf F(y0))/2,
определяющее точность восстановления
функции распределения, зависят от mi,
i=1,...,L
и y0.
Однако 1/L+1.
с помощью вычетов. При этом inf F(y0)
будет равно сумме вычетов 0(z)/1(z)
для всех y,y0,
а sup F(y0),
будет равно сумме inf F(y0)
и очередного вычета. Среднее значение
Fср(y0)=(sup F(y0)+inf F(y0))/2
и значение =(sup F(y0)+inf F(y0))/2,
определяющее точность восстановления
функции распределения, зависят от mi,
i=1,...,L
и y0.
Однако 1/L+1.
Таким образом, с помощью алгоритмов А и Б можно с заданной точностью рассчитать вероятностные характеристики исследуемой программы.