

ГУАП
КАФЕДРА ПИ
ОТЧЕТ ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
Доцент, канд. тех. наук |
|
|
|
О. О. Жаринов |
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ № 1 |
ОСНОВЫ МОДЕЛИРОВАНИЯ АУДИОСИГНАЛОВ СРЕДСТВАМИ PYTHON |
по курсу: Мультимедиа технологии |
|
|
РАБОТУ ВЫПОЛНИЛ
СТУДЕНТ ГР. № |
|
|
|
|
|
|
|
|
подпись, дата |
|
инициалы, фамилия |
Санкт-Петербург 2024
Цель работы
Получить представления о принципах формирования аудиосигналов и приобрести навыки работы со звуковыми файлами с использованием Python.
Вариант задания
Номер варианта: №8
Свойства моделируемого аудиосигнала: Синусоидальный сигнал, громкость которого линейно увеличивается от 0 в начале записи до максимума в конце записи в левом канале и одновременно уменьшается от максимума до 0 в правом канале. Частота сигнала не изменяется на всем протяжении записи.
Теоретические сведения
Мультимедиа аудиоконтент представляет собой разновидность медиаконтента, основанную на звуковых элементах, включающих подкасты, аудиорекламу, аудиокниги, голосовые сообщения и другие форматы, где главным средством коммуникации является звук. В качестве основных задач по обработке мультимедиа аудиоконтента обычно выделяют следующие:
Редактирование аудиофайлов – это процесс изменения звуковых файлов, например, удаление шумов, вырезание фрагментов, добавление эффектов и т.д.;
Воспроизведение аудиофайлов – процесс проигрывания звуковых файлов на разных устройствах;
Визуализация аудиофайлов – возможность визуально оценить звук, записанный внутри файла, а также узнать АЧХ звука;
Транскодирование аудиофайлов – процесс преобразования аудиофайлов из одного формата в другой;
И т.д.
Для генерации простейших аудиосигналов можно применять различные языки программирования: С++, Java, MATLAB, C# и т.д. Однако среди всего этого набора был выбран язык программирования Python, поскольку он является одним из самых популярных языков программирования в мире. И плюсов, которые можно отметить у данного языка, можно выделить следующие: очень легкий синтаксис и огромное количество разнообразных библиотек, благодаря которым возможности данного языка расширяются многократно.
Формирование модельного аудиофайла
Теперь перейдем к основным частям лабораторной работы. Сама работа состоит из двух частей, и в первой части необходимо написать программу, осуществляющую формирование модельного аудиофайла с заданными по варианту свойствами и последующую запись его в файл в формате wav. Список используемых переменных представлен в таблице 1, а сам код программы – в листинге 1.
Таблица 1. Список используемых переменных
Название |
Тип |
Описание |
Sample_rate |
Целочисленный |
Частота дискретизации звука |
Td |
Дробный |
Период дискретизации звука |
Signal_left |
Массив дробей |
Сгенерированный звук 1-го канала |
Signal_right |
Массив дробей |
Сгенерированный звук 2-го канала |
Stereo_signal |
Двумерный массив |
Конечный двухканальный звук |
Duration |
Целочисленный |
Длительность звуковой дорожки |
freq |
Целочисленный |
Частота генерируемого звука |
Листинг 1. Формирование аудиофайла
def generate_signal(duration: int, freq: int): sample_rate = 44100 # частота дискретизации td = 1/sample_rate # период дискретизации # Генерируем звуковой сигнал для левого уха (эталонный) t = np.linspace(0, duration, int(sample_rate * duration), endpoint=False) signal_left = np.sin(2 * np.pi * freq * t) # Меняем амплитуду for i in range(int(sample_rate * duration)): signal_left[i] = signal_left[i] * i/int(sample_rate * duration) # Генерируем звуковой сигнал для правого канала (копируем эталонный) signal_right = signal_left[::-1] # Создаем стерео звуковой сигнал stereo_signal = np.column_stack((signal_left, signal_right)) return stereo_signal, sample_rate # Генерация звука signal, rate = generate_signal(5, 800) # Воспроизводим стерео звук и сохраняем в файл sd.play(signal, rate) sd.wait() sf.write("output_audio.wav", signal, rate) |
Далее, для того чтобы убедиться в том, что данная программа создает именно ту звуковую дорожку, которая требуется по варианту задания, была создана визуализация сгенерированного аудиофайла, которая показана на рисунке 1. Также, исходный код программы и сгенерированный аудиофайл расположен в репозитории на GitHub [1].
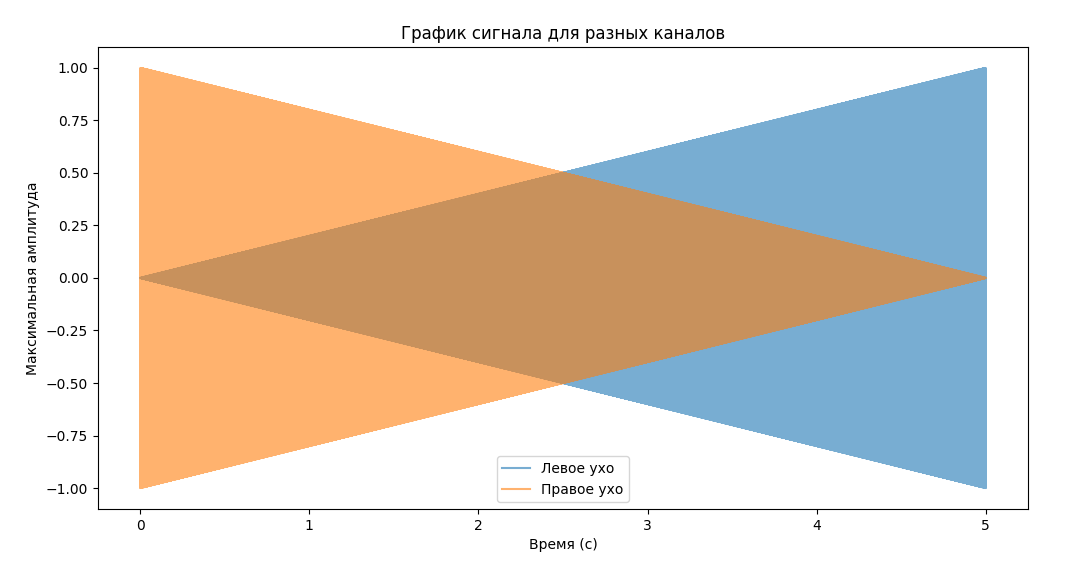
Рисунок 1 – Визуализация сформированного аудиофайла
Если же приблизить данный график, то будет видно, что амплитуда сигналов уменьшается (и увеличивается) не прямолинейно, а волнообразно, как показано на рисунке 2.

Рисунок 2 – Волнообразный спуск амплитуды