

ИАД_ЛР1_Дашин
.docxФедеральное государственное бюджетное образовательное учреждение высшего образования. «Национально исследовательский университет
«Московский энергетический институт»
Кафедра Управления и интеллектуальных технологий
Лабораторная работа №1
ПОСТРОЕНИЕ И АНАЛИЗ РЕГРЕССИОННЫХ ЗАВИСИМОСТЕЙ
Выполнил:
Дашин И.Н.
А-02-20
Москва 2022 г.
Импортируем датасет ирисы Фишера:

Проведем разведочный анализ данных датасета ирисы Фишера:
Построим диаграмму Тьюки по всем признакам

Видим, что среди значений признаков выделяются значения sepal width, так как они имеют выбросы.
Проанализируем корреляционные зависимости между исследуемыми переменными:
Для этого построим тепловые карты для парных и множественных коэффициентов корреляции:

Видим, что наилучшая линейная связь наблюдается у ширины лепестка (Petal Width) с его длинной (Petal Length) – 0.96, а так же с длинной чашелистика (Sepal Length) – 0.82.
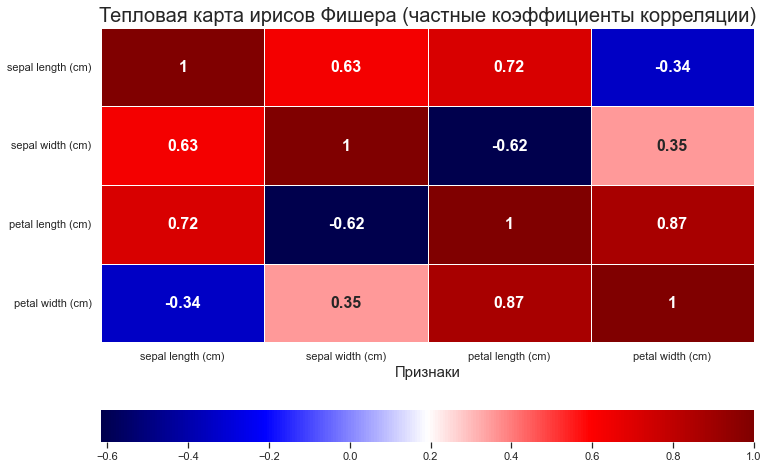
При построении тепловой карты с частными коэффициентами корреляции видим, что при фиксации остальных переменных линейная связь между длинной лепестка (Petal Width) с длинной чашелистика (Sepal Length) становится не сильно выраженной и отрицательной, а значит до этого корреляция возникала от воздействия факторов которые теперь зафиксированы.
Проверим предположение о распределении признаков по нормальному закону критерием Колмогорова-Смирнова:
sepal length (cm) : KstestResult(statistic=0.999991460094529, pvalue=0.0)
sepal width (cm) : KstestResult(statistic=0.9794298858198347, pvalue=1.9343513094431768e-253)
petal length (cm) : KstestResult(statistic=0.8765328487477231, pvalue=1.4044248603466367e-136)
petal width (cm) : KstestResult(statistic=0.5459263761057697, pvalue=1.8764992713715694e-42)
Значения статистик намного меньше уровня значимости, значит мы можем предположить,
что значения всех признаков не подчиняются нормальному закону распределения.
Определим входные и выходные переменные:
Проанализируем зависимость длинны от ширины лепестка. Ширина лепестка (Petal Length ) – входная переменная, длинна лепестка (Petal Length ) – выходная.

Уравнение парной регрессии

Коэффициент детерминации: 0.9271098389904927
Скорректированный коэффициент детерминации: 0.924167399602457
Стандартная ошибка: 0.36579694412763775
B0: 1.0835580328505112
B1: [2.2299405]
Множественная регрессия:
В качестве выходного параметра выступает длинна лепестка, в качестве входных – остальные три признака.
Коэффициент детерминации: 0.9485236349446816
Скорректированный коэффициент детерминации: 0.948521600504265
Стандартная ошибка: 0.31369294102123063
B0: -1.5071383768459286
B1,b2,b3: [1.74810286 0.27112781 0.27112781]
Проверка гипотезы о нормальном распределении остатков:
Значения критерия Дурбина-Уотсона = 1.3609804610262028
KstestResult(statistic=0.23522102323512725, pvalue=1.3722091847744725e-07)
Остатки не подчиняются нормальному закону распределения. Значение критерия Дурбина-Уотсона < 2. Это говорит о наличии ненулевой связи между остатками. Эта информация говорит нам о том, что возможно для нашей модели не выполняются предпосылки регрессионного анализа и это стоит учитывать при интерпретации полученных результатов.
5. Разделив выборку на тестовую и обучающую в соотношении 1:1 получим предсказание переменной.
Коэффициент детерминации: 0.8582150221196795
Стандартная ошибка: 0.26679680989339244
СКО: 0.3250530447035454
KstestResult(statistic=0.2694499056604559, pvalue=2.672187743568187e-05)
(остатки так же не подчиняются нормальному распределению)
Удалив выбросы из выборки получаем новый фрейм данных:


Коэффициент детерминации: 0.8571094796835401
Стандартная ошибка: 0.25930623004608877
СКО: 0.3279503306135595
KstestResult(statistic=0.27499944699578704, pvalue=2.268497665387463e-05)
(остатки так же не подчиняются нормальному распределению)

График остатков для множественной регрессии без выбросов
Удалив выбросы, мы получили незначительное снижение коэффициента детерминации, это может быть связано с тем, что наша выборка имело очень мало выбросов и их устранение не принесло огромный вклад в построение множественной регрессии.
8. Проведем исследования для датасета - Factor.sta.

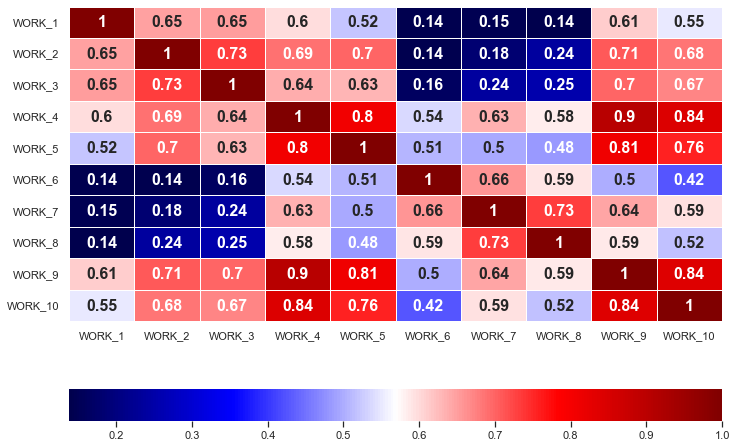
Построенная по переменным тепловая карта (парные коэффициенты корреляции)

Из тепловой карты можем сделать вывод что целесообразно будет строить регрессию с переменными, которые имеют наибольший парный коэффициент корреляции.
Например: work_4 имеет такие с work_5, work_9, work_10