Дашин_ЛБ4
.docxЛабораторная работа № 4
ОБРАБОТКА И АНАЛИЗ РЕАЛЬНЫХ МАССИВОВ ДАННЫХ


pclass: A proxy for socio-economic status (SES) 1st = Upper 2nd = Middle 3rd = Lower age: Age is fractional if less than 1. If the age is estimated, is it in the form of xx.5 sibsp: The dataset defines family relations in this way... Sibling = brother, sister, stepbrother, stepsister Spouse = husband, wife (mistresses and fiancés were ignored) parch: The dataset defines family relations in this way... Parent = mother, father Child = daughter, son, stepdaughter, stepson Some children travelled only with a nanny, therefore parch=0 for them.
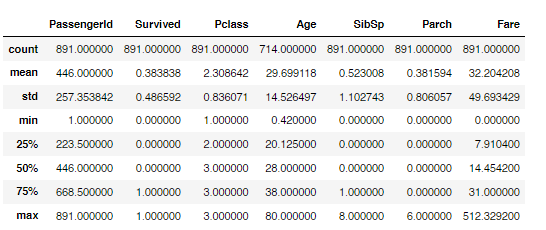
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object












X=bb_clearAge[['Pclass', 'Family']]
y=bb_clearAge['Age']
regr = RandomForestRegressor()
Mean Absolute Error: 10.343644067796612
Mean Squared Error: 168.33202457627118
Mean Root Squared Error: 12.974283200865903
Mean Absolute Error: 10.235169491525424
Mean Squared Error: 165.55066864406783
Mean Root Squared Error: 12.866649472340024

pr=["Pclass", "Age", "Fare", "Sex"]
X = bb_PredAge[pr]
y = bb_PredAge['Survived']


precision recall f1-score support
0 0.82 0.86 0.84 184
1 0.75 0.68 0.71 111
accuracy 0.79 295
macro avg 0.78 0.77 0.78 295
weighted avg 0.79 0.79 0.79 295
pr=["Pclass", "Age", "Fare", "Sex"]
X = bb_PredAge[pr]
y = bb_PredAge['Survived']
clf = LogisticRegression()

precision recall f1-score support
0 0.83 0.87 0.85 184
1 0.77 0.71 0.74 111
accuracy 0.81 295
macro avg 0.80 0.79 0.79 295
weighted avg 0.81 0.81 0.81 295



pr=["Pclass", "Age", "Fare", "Sex", 'Family', 'Emb_C','Emb_Q','Emb_S', 'Alone' ]
X = bb_final[pr]
y = bb_final['Survived']
clf = DecisionTreeClassifier(max_depth=4)

precision recall f1-score support
0 0.81 0.93 0.87 184
1 0.85 0.64 0.73 111
accuracy 0.82 295
macro avg 0.83 0.78 0.80 295
weighted avg 0.82 0.82 0.81 295
pr=["Pclass", "Age", "Fare", "Sex", 'Family', 'Emb_C','Emb_Q','Emb_S', 'Alone', 'Parch', 'SibSp', 'Fareperhead']
X = bb_final[pr]
y = bb_final['Survived']
clf = LogisticRegression()

precision recall f1-score support
0 0.85 0.88 0.86 275
1 0.79 0.75 0.77 171
accuracy 0.83 446
macro avg 0.82 0.82 0.82 446
weighted avg 0.83 0.83 0.83 446
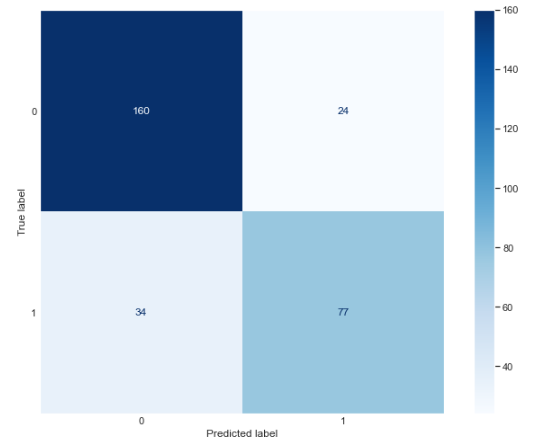
pr=["Pclass", "Age", "Fare", "Sex", 'Family', 'Emb_C','Emb_Q','Emb_S', 'Alone', 'Parch', 'SibSp']
X = bb_final[pr]
y = bb_final['Survived']
clf = RandomForestClassifier(n_estimators=30)
precision recall f1-score support
0 0.82 0.87 0.85 184
1 0.76 0.69 0.73 111
accuracy 0.80 295
macro avg 0.79 0.78 0.79 295
weighted avg 0.80 0.80 0.80 295
from sklearn.ensemble import GradientBoostingClassifier
pr=["Pclass", "Age", "Fare", "Sex", 'Family', 'Emb_C','Emb_Q','Emb_S', 'Alone', 'Parch', 'SibSp', 'Fareperhead']
X = bb_final[pr]
y = bb_final['Survived']
clf = GradientBoostingClassifier()

precision recall f1-score support
0 0.86 0.88 0.87 275
1 0.79 0.77 0.78 171
accuracy 0.83 446
macro avg 0.83 0.82 0.82 446
weighted avg 0.83 0.83 0.83 446

from sklearn.model_selection import GridSearchCV
pr=["Pclass", "Age", "Fare", "Sex", 'Family', 'Emb_C','Emb_Q','Emb_S', 'Alone', 'Parch', 'SibSp']
X = bb_final[pr]
y = bb_final['Survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
params = [{'criterion':['gini','entropy'],
'max_depth':[4,5,6,7,8,9,10,11,12,15,20,30,40,50,70,90,120,150, None],
'splitter': ['best', 'random']}]
clf = GridSearchCV(DecisionTreeClassifier(), param_grid=params, cv=5)
clf = clf.fit(X_train,y_train)
y_pred = clf.predict(aa_final[pr])
print(y_pred)