

8970
.pdf3. Написание параллельной программы, в которой каждый поток выводит на экран сообщение: “Hello World!”.
3.1.Для поддержки параллельных систем с общей памятью будем использовать библиотеку omp.h. Подключите указанную библиотеку командой include.
3.2.Модифицируйте программу, написанную в Задании 2, добавив в неё директиву, создающую параллельную область: #pragma omp parallel. Так, чтобы код программы принял следующий вид:
#include <omp.h> #include <stdio.h> #include <conio.h>
int main () {
#pragma omp parallel
{
printf("Hello World!\n");
}
getch();
}
3.3. Включите поддержку OpenMP для компилятора через меню Проект – Свойства (Project – Properties) или клавишу Alt+F7 (Рис. 10). В
открывшемся окне свойств выберите пункт Свойства конфигурации - C/C++ - Язык – Поддержка OpenMP (Configuration Properties – C/C++ - Language – OpenMP Support) и установите значение Yes (/openmp) (Рис. 11). Для подтверждения нажмите кнопку OK.
Рис. 10. Задание свойств проекта
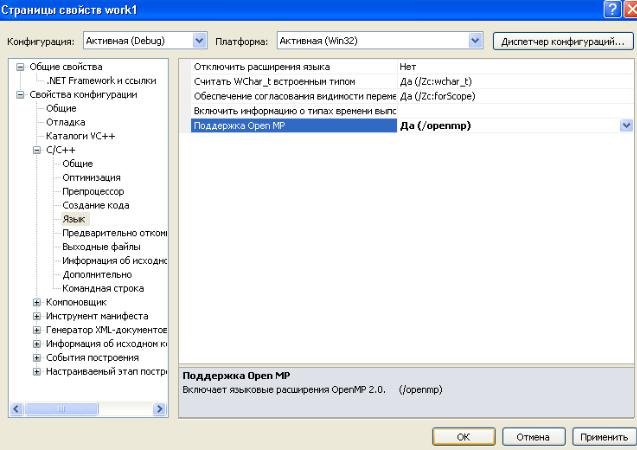
Рис. 11. Включение поддержки OpenMP
3.4. Выполните сборку программы как описано в п. 2.3. и в случае успеха запустите программу как описано в п.2.4.
4. Модификация программы из Задания 3 так, чтобы потоки выводили на экран сообщение: “Hello World!” и свой порядковый номер, а нулевой поток дополнительно выводил бы количество потоков.
4.1.Для вывода порядковых номеров потоков и их количества необходимо объявить две переменных типа int в функции main(), а также в строке, объявляющей создание параллельной области. Для переменной, определяющей номер потока указать область видимости как private, а для переменной, определяющей количество потоков указать область видимости как shared.
4.2.Для определения номера потока используйте функцию omp_get_thread_num(). Для определения количества потоков используйте функцию omp_get_num_threads().
4.3.Количество потоков рекомендуется определять после определения номеров потоков и только для одного (нулевого) потока.
5. Модификация программы из Задания 4 так, чтобы порядковый номер выводился в порядке возрастания.
5.1.Для проверки правильности работы программы рекомендуется использовать функцию, задающую количество потоков (нитей) перед созданием параллельной области:
omp_set_num_threads(N), где N – количество нитей.
5.2.Для упорядочивания вывода номеров нитей можно использовать директиву ordered и опцию ordered для директивы pragma omp for, определяющие блок внутри тела цикла, который должен выполняться в том порядке, в котором итерации идут в последовательном цикле. Пример использования:
#pragma omp for ordered for (i=0;i<10;i++)
#pragma omp ordered printf(“%d\n”, i);
ЛАБОРАТОРНАЯ РАБОТА № 2
Тема: Создание консольного многопоточного Windows-приложения, вычисляющего суммы элементов двух n-мерных векторов Ci=Ai+Bi для систем с общей памятью.
Цель работы: Изучение omp-директивы по распараллеливанию циклов и видов распределения витков цикла по потокам.
Лабораторная работа состоит из трёх последовательно выполняемых заданий.
1.Написать последовательную программу, вычисляющую суммы элементов двух n-мерных векторов Ci=Ai+Bi, где 1 ≤ i ≤ n.
2.Написать параллельную программу на основе технологии OMP, в которой элементы векторов А и В распределяются по потокам и суммируются (реализовать статическое, динамическое и экспоненциальное распределения).
3.Построить графики зависимости времени выполнения последовательного и параллельных (статическое, динамическое и экспоненциальное распределение) алгоритмов от количества элементов вектора. Проанализировать эффективность параллельного алгоритма.
Пояснения к выполнению работы
1.Написание последовательной программы, вычисляющей суммы элементов двух n-мерных векторов Ci=Ai+Bi, где 1 ≤ i ≤ n.
1.1.Создать пустой проект консольного Windows – приложения в среде Visual С++ (см. Лабораторная работа №1).
1.2.Написать код, включающий в себя:
- инициализацию элементов векторов А и В значениями, равными соответствующим номерам элементов векторов;
- вывод на экран значений элементов векторов А и В (функция printf() из библиотеки stdio.h);
- вычисление элементов результирующего вектора С; - вывод на экран результатов вычислений в виде таблицы.
1.3.Запустить программу.
2.Написание параллельной программы на основе технологии OMP, в которой элементы векторов А и В распределяются по потокам и суммируются.
2.1.Для поддержки параллельных систем с общей памятью подключите библиотеку omp.h.
2.2.Модифицируйте программу, написанную в Задании 1, добавив в неё директиву, создающую параллельную область: #pragma omp parallel. Укажите видимость общих и локальных переменнных для потоков через опции shared и private.
2.3.Добавьте директиву для распараллеливания циклов #pragma omp for.
2.4.Для явного задания типа распределения итераций в цикле укажите опцию schedule и тип распределения (static, dynamic, guided):
·static – блочно-циклическое распределение итераций цикла; размер блока – chunk. Первый блок из chunk итераций выполняет нулевая нить, второй блок — следующая и т.д. до последней нити, затем распределение снова начинается с нулевой нити.
·dynamic – динамическое распределение итераций с фиксированным размером блока: сначала каждая нить получает chunk итераций (по умолчанию chunk=1), та нить, которая заканчивает выполнение своей порции итераций, получает первую свободную порцию из chunk итераций. Освободившиеся нити получают новые порции итераций до тех пор, пока все порции не будут исчерпаны. Последняя порция может содержать меньше итераций, чем все остальные.
·guided – динамическое распределение итераций, при котором размер порции уменьшается с некоторого начального значения до величины chunk (по умолчанию chunk=1) пропорционально количеству ещё не распределённых итераций, делённому на количество нитей, выполняющих цикл.
2.5.Включите в свойствах проекта поддержку OpenMP.
3. Построение графиков зависимости времени выполнения последовательного и параллельных (статическое, динамическое и экспоненциальное распределение) алгоритмов от количества элементов вектора. Анализ эффективности параллельного алгоритма.
3.1. Добавьте в проект все три модификации (статическое, динамическое и экспоненциальное распределение) параллельного алгоритма, а также последовательный алгоритм.
3.2. Выполните замеры времени выполнения всех алгоритмов только для фрагмента кода, выполняющего непосредственное вычисление вектора С. Для измерения времени можно использовать функцию clock() из библиотеки time.h. Пример использования функции clock() показан ниже:
double t1 = clock();// вызывается из последовательной части программы
//Фрагмент кода, в котором необходимо выполнить замер времени
double t2 = clock();// вызывается из последовательной части программы double td = (t2 - t1) / double (CLOCKS_PER_SEC);// вычисление разницы
между замерами и преобразование результата в секунды
3.3. Проведите 5 экспериментов, изменяя количество элементов векторов, таким образом, чтобы время выполнения алгоритмов составляло не менее 20 секунд. При выполнении параллельных алгоритмов используйте все доступные операционной системе ядра. Каждый поток должен выполняться на одном процессоре (ядре). Результаты экспериментов занесите в Таблицу 1.
|
|
|
|
|
|
|
|
|
|
Таблица 1 |
|
Кол- |
Время |
Статическое |
Динамическое |
Экспоненциальн |
|
||||||
во |
выполнен |
распределени |
распределение |
|
ое |
|
|
||||
элем |
ия |
|
е |
|
|
|
распределение |
|
|||
енто |
последов |
Tp, |
Sp |
Ep |
Tp, |
Sp |
Ep |
Tp, |
Sp |
Ep |
|
в |
ательного |
сек |
|
|
сек |
|
|
сек |
|
|
|
вект |
алгоритм |
|
|
|
|
|
|
|
|
|
|
оров |
а (T1), сек |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Количество ядер составляет _________шт.
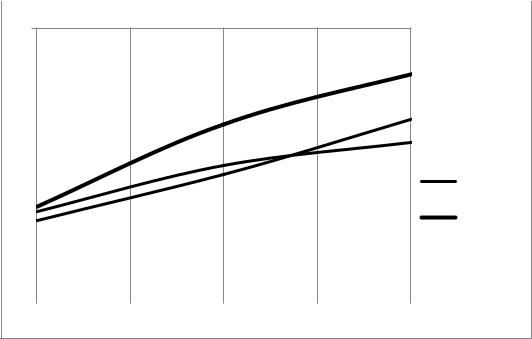
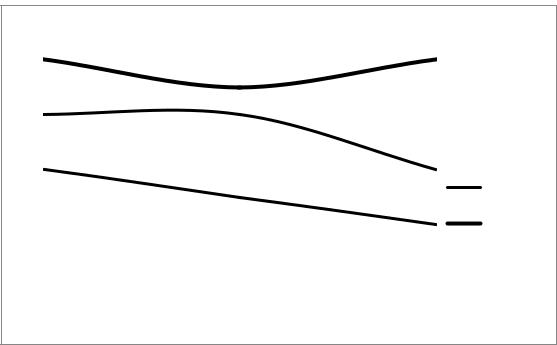
3.4. Вычислите ускорение (Sp = T1 / Tp) и эффективность (Ep = Sp / p) параллельных алгоритмов и внесите результаты вычислений в таблицу 1. По данным таблицы 1 постройте графики зависимостей ускорения и эффективности от количества элементов векторов, разместив их как показано на рис. 12.
6S
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
Статич. |
|
3 |
|
|
|
|
|
|
|
N=3000 |
|
|
|
|
|
|
|
|
N=4000 |
||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
||
2 |
|
|
|
|
|
|
|
Динамич. |
|
|
|
|
|
|
|
|
|
N=5000 |
|
1 |
|
|
|
|
|
|
Кол-во |
||
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|||
0 |
|
|
|
|
|
|
элементов |
||
|
|
|
|
|
|
векторов |
|||
|
|
|
|
|
|
||||
1000 |
2000 |
3000 |
4000 |
5000 |
|||||
|
|
||||||||
Рис. 12 а. Пример графиков зависимости ускорения от количества элементов векторов при разных способах распределения
1
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
E
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
N=3000 |
|
|
|
|
|
|
|
|
|
|
|
|
Статич. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
N=4000 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Динамич. |
|
|
|
|
|
|
|
|
|
|
|
|
N=5000 |
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
Кол-во |
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
элементов |
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
векторов |
|
1000 |
2000 |
3000 |
4000 |
5000 |
|
|||||||
|
|
|
||||||||||
2 |
3 |
4 |
5 |
6 |
|
|
||||||
Рис. 12 б. Пример графиков зависимости эффективности от количества элементов векторов при разных способах распределения
3.5. На основе полученных данных проанализируйте эффективность параллельных алгоритмов.

ЛАБОРАТОРНАЯ РАБОТА № 3
Тема: Создание консольного многопоточного Windows-приложения, вычисляющего число Пи для систем с общей памятью.
Цель работы: Изучение директив, предназначенных для синхронизации работы нитей (потоков) на примере директив редукции, критической секции и атомарной операции.
Лабораторная работа состоит из трёх последовательно выполняемых заданий.
1. Написать последовательную программу, вычисляющую число Пи по формуле:
.
2.Написать параллельную программу, вычисляющую число Пи, на основе технологии OpenMP, распараллелив выполняемые операции в цикле (суммирование высот прямоугольников реализовать в трёх вариантах: через редукцию, критическую секцию и атомарную операцию (atomic)).
3.Построить графики зависимости времени выполнения последовательного и параллельных (редукция, критическая секция и директива atomic) алгоритмов от количества интервалов разбиения (N). Проанализировать эффективность параллельного алгоритма.
Пояснения к выполнению работы
1. Написание последовательной программы, вычисляющей число Пи используя формулу:
.
1.1.Создать пустой проект консольного Windows – приложения в среде Visual С++ (см. Лабораторная работа №1).
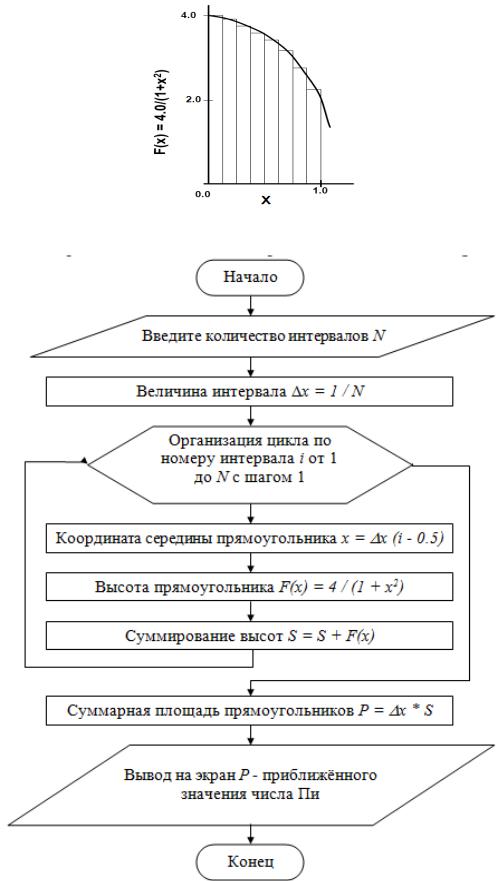
1.2.Для вычисления интеграла воспользуйтесь методом прямоугольников
(рис. 13) с постоянным шагом x:
N |
N |
|
F xi |
x x F xi |
, |
i 1 |
i 1 |
|
где F(x) – высота прямоугольника (значение подынтегральной функции), x – ширина прямоугольника, 0 ≤ x ≤ 1. Таким образом, вычисление числа Пи сводится к вычислению суммы площадей всех прямоугольников. Известно, что с уменьшением ширины прямоугольников ( x), т.е. с увеличением
количества интервалов разбиения отрезка [0, 1], точность вычисления числа Пи возрастает.
Рис. 13. Разбиение площади под интегральной кривой на прямоугольники 1.3. Алгоритм вычисления числа Пи представлен на блок-схеме (рис. 14).
Рис. 14. Блок-схема алгоритма вычисления числа Пи
1.4.Ввод количества интервалов организовать через функцию scanf(), а вывод вычисленного числа Пи через функцию printf() из библиотеки stdio.h.
1.5.Запустить программу.
2. Написание параллельной программы на основе технологии OMP, в которой элементы векторов А и В распределяются по потокам и суммируются (реализовать статическое, динамическое и экспоненциальное распределения).
2.1.Для распараллеливания цикла, в котором происходит суммирование высот прямоугольников добавьте директиву #pragma omp for. В результате чего суммирование будет выполняться только внутри потоков. Таким образом, для каждого потока будет существовать своя (локальная) сумма.
2.2.Для суммирования локальных сумм можно применить опцию reduction к
директиве #pragma omp for:
reduction (оператор : список переменных) – задаёт оператор и список общих переменных; для каждой переменной создаются локальные копии в каждой нити; над локальными копиями переменных после завершения всех итераций цикла выполняется заданный оператор (+, *, -, &, |, ^, &&, ||). Переменные, указываемые в reduction указывать через опции shared и private не нужно.
2.3.Для суммирования локальных сумм через критическую секцию необходимо объявить переменную, в которой накапливается сумма высот прямоугольников внутри потоков, как локальную (private) и дополнительно ввести общую переменную, в которой будут накапливаться локальные суммы. Суммирование локальных сумм должно выполняться в критической секции, объявленной через директиву #pragma omp critical.
Вкаждый момент времени в критической секции может находиться не более одной нити. Если критическая секция уже выполняется какой-либо нитью, то все другие нити, выполнившие директиву для секции с данным именем, будут заблокированы, пока вошедшая нить не закончит выполнение данной критической секции. Как только работавшая нить выйдет из критической секции, одна из заблокированных на входе нитей войдет в неё. Если на входе в критическую секцию стояло несколько нитей, то случайным образом выбирается одна из них, а остальные заблокированные нити продолжают ожидание.
2.4.Для суммирования высот прямоугольников через директиву atomic необходимо перед оператором суммированием добавить директиву #pragma omp atomic, а переменную, в которой накапливается сумма высот прямоугольников объявить как общую.
Директива #pragma omp atomic относится к идущему непосредственно за ней оператору присваивания и гарантирует корректную работу с общей переменной, стоящей в его левой части. На время выполнения оператора блокируется доступ к данной переменной всем запущенным в данный момент нитям, кроме нити, выполняющей операцию. Атомарной является