

МИНОБРНАУКИ РОССИИ Федеральное государственное бюджетное образовательное учреждение высшего образования
«Нижегородский государственный архитектурно-строительный университет»
Д. И. Кислицын
Языки программирования систем искусственного интеллекта
Учебно-методическое пособие
по выполнению лабораторных работ для обучающихся по дисциплине «Языки программирования систем искусственного интеллекта»
по направлению подготовки 09.04.02 Информационные системы и технологии, профиль «Искусственный интеллект в системах и сетях передачи данных»
Нижний Новгород
2022
2
МИНОБРНАУКИ РОССИИ Федеральное государственное бюджетное образовательное учреждение высшего образования
«Нижегородский государственный архитектурно-строительный университет»
Д. И. Кислицын
Языки программирования систем искусственного интеллекта
Учебно-методическое пособие
по выполнению лабораторных работ для обучающихся по дисциплине «Языки программирования систем искусственного интеллекта»
по направлению подготовки 09.04.02 Информационные системы и технологии, профиль «Искусственный интеллект в системах и сетях передачи данных»
Нижний Новгород ННГАСУ
2022
3
УДК 681.3 (075)
Кислицын Д. И. Языки программирования систем искусственного интеллекта: учебно-методическое пособие / Д. И. Кислицын; Нижегородский государственный архитектурно-строительный университет. – Нижний Новгород : ННГАСУ, 2022. - 35 с. - Текст : электронный.
Предназначено для обучающихся в ННГАСУ по дисциплине «Языки программирования систем искусственного интеллекта» по направлению подготовки 09.04.02 Информационные системы и технологии, профиль «Искусственный интеллект в системах и сетях передачи данных».
Д. И. Кислицын, 2022ННГАСУ, 2022
4
ОГЛАВЛЕНИЕ |
|
Лабораторная работа № 1. Введение в анализ данных (очистка, интерполяция, |
|
экстраполяция) с использованием языков программирования Python и R |
5 |
Лабораторная работа № 2. Корреляционный анализ данных |
13 |
Лабораторная работа № 3. Анализ временных рядов (регрессии, классификация) с
использованием языков программирования Python и R |
26 |
Лабораторная работа № 4. Применение нейронных сетей для анализа временныхрядов с
использованием языков программирования Python и R |
28 |
Лабораторная работа № 5. Применение методов ИИ для поиска и организации каналов
связи с использованием языков программирования Python и R |
30 |
Лабораторная работа № 6. Кластерный анализ с использованием языков |
|
программирования Python и R |
34 |
5
ЛАБОРАТОРНАЯ РАБОТА № 1
Введение в анализ данных (очистка, интерполяция, экстраполяция) с использованием языков программирования Python и R
Цель работы: изучить методы интерполяции и очистки временных рядов средствами библиотек pandas, statsmodels и sklearn.
ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
Импортирование датасетов и интерполяция пропущенных данных
#@title Импортирование библиотек и монтирование диска
from google.colab import drive # функция монтирования google диска (доступ к папкам) import os # библиотека работы с фаловой системой
import pandas as pd import numpy as np
#import seaborn as sns
#import matplotlib.pyplot as plt
#Монтирование google диска с целью получния доступа к датасетам drive.mount('/content/drive')
#Указываем путь до папки с датасетом максимальной применимой частоты (МПЧ (muf)) dir_path = "/content/drive/My Drive/Colab Notebooks/ai_systems/lw2/muf_data"
#Метод .listdir позволяет получить список файлов в дирректории
directory_files = os.listdir(dir_path)
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
Формирование дата фрейма и интерполяция пропущенны значений
Создадим новый дата фрейм и начнем обработку файлов дата сета в цикле. Интерполяция пропущенных значений файлов выполним путем определения начальной и конечной даты каждого набора данных (файл), затем в данном диапазоне создадим новый набор индексов формата времени с шагом датасета (в данном случае шаг 5 мин (300 сек)). Далее по новому временному диапазону произведем реиндексирование дата фрейма, пропущенные значения определятся как NaN. Операция интерполирования восстановит NaN значения.
df = pd.DataFrame()
for file in directory_files:
#Оператор os.path.join(dir_path, file) соединяет путь до папки с данными с конкретным названием файла,
#с целью формирования полноценного пути до документа дата сета
df_file = pd.read_csv(os.path.join(dir_path, file) , names=['time', 'muf', 'bool'], encoding = 'ISO-8859-1', low_memory=False)
#Метод .drop выполняет удаление колонки или строчки из дата фрейма df_file = df_file.drop('bool', axis=1)
#Ниже код формирования колонки времени дата фрейма формата '%Y-%m-%d %H:%M'
df_file['time'] = pd.to_datetime('2021'+str(file.split('.')[0]) +' '+ df_file['time'].astype(str), format='%Y%j %H:%M:%S').dt.strftime('%Y-%m-%d %H:%M') #
Далее определим начальную и конечную датуstart = df_file['time'].min()
stop = df_file['time'].max()

6
#Создадим и отформатируем новый диапазон дат new_daterange = pd.date_range(start, stop, freq='300S') new_daterange = new_daterange.strftime('%Y-%m-%d %H:%M') #
Произведем операцию реиндексирования и интерполирования
df_file = df_file.set_index('time').reindex(new_daterange).interpolate().reset_index()
#Объединим обработанные дата фреймы в один
df = pd.concat([df, df_file], axis=0)
df = df.set_index(['index'])df = df.sort_index()
Графическое представление обработанного дата фрейма (библ. pyplot)
Plotly - библиотека для визуализации данных, состоящая из нескольких частей:
Front-End на JS
Back-End на Python (за основу взята библиотека Seaborn)
Back-End на R
Документация - https://plotly.com/graphing-libraries/
Модуль plotly.express (обычно импортируемый как px) содержит функции, которые могут создавать целые графики сразу, и называется Plotly Express или PX. Plotly Express является встроенной частью библиотеки графиков и является рекомендуемой отправной точкой для создания наиболее распространенных графиков. Каждая функция Plotly Express использует графические объекты внутри и возвращает экземпляр plotly.graph_objects.Figure. Модуль plotly.graph_objects (обычно импортируемый как go) содержит автоматически сгенерированную иерархию классов Python, которые представляют неконечные узлы в этой схеме рисунка. Термин «объекты графа (graph objects)» относится к экземплярам этих классов.
Данная библиотека позволяет выполнять интерактивный анализ построенных графиков.
#импорт очновных модулей библиотеки plotly import plotly.graph_objects as go
import plotly.express as px
#Метод .line() создает линейный график (соединенный по точкам) fig = px.line(df, x=df.index, y=df['muf'], title='MUF')
#Выведем не весь временной ход, только часть, где присутствует# не весь день
fig.update_xaxes(range=['2021-02-02', '2021-02-09']) fig.show()
Рисунок 1. Графическое представление интерполированного временного хода значений максимальной применимой частоты.
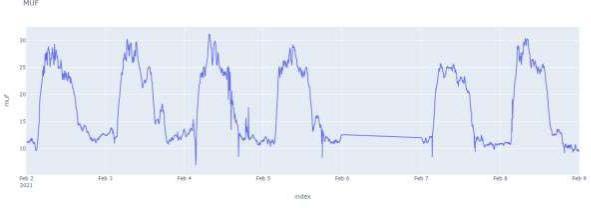
7
Анализ графика и удаление значений за неполный день
Проводя анализ интерполированных временных рядов (график рис.1) может возникунать необходимость удалить значения за не полный день, как, например, за 2021- 02-05. Программный код ниже позволяет по определенным инедксам формата даты удалить из дата фрейма не восстановленные значения временного хода.
# Удаляем диапазон значений за 06.02.2021
df = df.drop(df.loc['2021-02-06 16:40':'2021-02-06 23:55'].index)
# Построми графки скорреткированного хода
fig = px.line(df, x=df.index, y=df['muf'], title='MUF') fig.update_xaxes(range=['2021-02-02', '2021-02-09']) fig.show()
Рисунок 2. Графическое представление интерполированного временного хода значений максимальной применимой частоты без остаточной составляющей.
Обработка аномалий временного хода и апроксимация Детектирование аномалий
Обработку аномалий выполним при помощи метода машинного обучения IsolationForest. Изолирующий лес — это алгоритм обнаружения аномалий. Он обнаруживает аномалии, используя изоляцию (насколько далеко точка данных находится от остальных данных), а не моделируя нормальные точки см. За данную процедуру отвечает библиотека sklearn.ensemble. Кроме того, для работы данного алгоритмамашинного обучения требуется предварительная обработка используемого набора данных, за что отвечает метод StandartScaler библиотеки sklearn.preprocessing. Предварительния обработка бывает необходима в следующих случаях:
Когда наши данные состоят из атрибутов с разным масштабом, многие алгоритмы машинного обучения могут извлечь выгоду из масштабирования атрибутов, чтобы все они имели одинаковый масштаб.
Это важно для алгоритмов оптимизации, используемых в ядре алгоритмовмашинного обучения, таких как градиентный спуск.
Это также важно для алгоритмов, которые взвешивают входные данные, такие как регрессия и нейронные сети, и алгоритмов, которые используют меры расстояния, например, K-ближайшие соседи.
Кроме того, есть возможность масштабировать исходные данные с помощью scikitlearn, используя класс MinMaxScaler.
#Испорт библиотек и иниициализация предобработчика scaler
from sklearn.ensemble import IsolationForest from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
# Создадим функцию выполняющую операции детектирования аномалий