

книги / Технологии разработки объектно-ориентированных программ на язык C++. Представление графических объектов и проектирование программ на алгоритмическом языке C++
.pdfОбратный обход (рис. 22.18) отличается от предыдущего симметричного тем, что относительно определенного узла к другому потомку одного предка не нужно сначала проходить через предка, а надо сразу идти к его потомку. Затем следуем к проигнорированному предку. Например:
•Вновь начало с самого нижнего левого листа – D. Чтобы продвигаться направо, в симметричном обходе в предыдущем случае нужно было пройти через предка этого листа.
•В обратном обходе этого не требуется.
•Так что необходимо перейти к узлу Е.
•Направляемся к узлу – предку этих потомков – B.
Левое поддерево пройдено. Обход через корень игнорируется, так что начало будет с самого низа его правого поддерева:
•Лист F.
•Выше – С.
•Конец на корне А.
Функции прямого, симметричного, обратногообходовдерева
Эти три метода прохождения дерева можно легко реализовать
ввиде рекурсий.
Вкаждой функции имеется аргумент – текущий узел. Если этот узел не NULL, т.е. существует, то выведем его, а также спустимся к его левому либо правому потомку.
Главную роль в каждой из функций прохождения играет порядок выполнения описанных до этого операций с узлом, т.е. очень важно и уникально для каждой функции прохождения дерева то,
вкакой последовательности эти действия будут располагаться: вывод, переход к левому или правому поддереву:
//ПРЯМОЙ ОБХОД (СВЕРХУ ВНИЗ) template<class T>
void Tree<T>::reorder(Tree<T> *node) { if (node != NULL) {
cout <<node->getData() <<““; reorder(node->left); reorder(node->right);
}
}
//СИММЕТРИЧНЫЙ ОБХОД (СЛЕВА НАПРАВО)
21
template<class T>
void Tree<T>::inOrder(Tree<T> *node) { if (node != NULL) {
inOrder(node->left);
cout <<node->getData() <<““; inOrder(node->right);
}
}
// ОБРАТНЫЙ ОБХОД (СНИЗУ ВВЕРХ) template<class T>
void Tree<T>::postOrder(Tree<T> *node) { if (node != NULL) {
postOrder(node->left); postOrder(node->right); cout<<node->getData() <<““;
}
}
Извлечение левого/правого поддерева и его удаление
Чтобы извлечь, например, левое поддерево, нужно нарушить связь между вызывающим узлом и его левым потомком. В итоге вызывающий узел лишится левого поддерева, а функция вернет корень этого извлеченного поддерева (рис. 22.19).
Чтобы удалить поддерево слева, нужно сначала его извлечь (для благополучного изменения связей), а затем удалить его корень.
Аналогичные действия производятся с извлечением и удалением правого поддерева:
template<class T>
Tree<T>* Tree<T>::ejectLeft() { // Извлечение if (this->left != NULL) {
Tree<T>* temp = this->left; this->left = NULL;
return temp;
}
return NULL;
}
template<class T>
void Tree<T>::deleteLeft() { // Удаление Tree<T>* temp = this->ejectLeft();
22

delete temp;
}
template<class T>
Tree<T>* Tree<T>::ejectRight() { if (this->right != NULL) {
Tree<T>* temp = this->right; this->right = NULL;
return temp;
}
return NULL;
}
template<class T>
void Tree<T>::deleteRight() { Tree<T>* temp = this->ejectRight(); delete temp;
}
Рис. 22.19. Извлечение и удаление поддерева
Печать дерева, развернутого на 90° против часовой стрелки и отраженного по вертикали
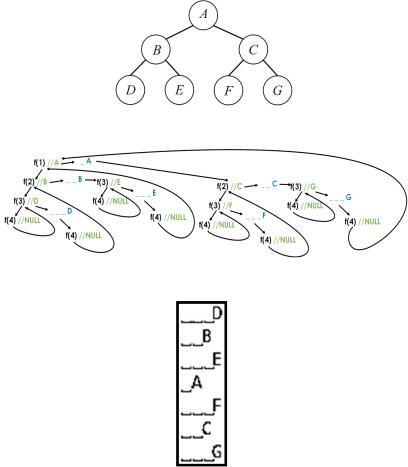
Данный вид печати дерева использует симметричный метод прохождения дерева.
Для того чтобы напечатать дерево горизонтально, понадобится рекурсивная функция, изменяющимся аргументом которой является некоторое число, отвечающее за то, сколько пробелов будет выведено перед данными, содержимым текущего узла. Причем чем глубже совершается проход по дереву, соответственно, чем больше уровень, тем больше пробелов будет напечатано для данного узла.
Схематично симметричный обход по дереву (рис. 22.20) показан на рис. 22.21, а его печать – на рис. 22.22:
23
void Tree<T>::printTree(int level) { if (this != NULL) {
this->left->printTree(level+1);
for (int i = 1; i <level; i++) cout <<" "; cout <<this->getData() << endl; this->right->printTree(level + 1);
}
}
Рис. 22.20. Дерево для теста горизонтальной печати
Рис. 22.21. Схема прохождения по дереву с печатью узлов
Рис. 22.22. Горизонтальная печать дерева (вывод): нижние подчеркивания обозначены символом пробела
24
Стоит заметить, что при выводе левое поддерево всегда будет печататься выше правого. Кроме того, если все узлы хранят в себе максимумодинсимволвкачестведанных, печатьбудетвклассическомвиде.
Вертикальная печать будет рассмотрена отдельно позже.
Копирование дерева
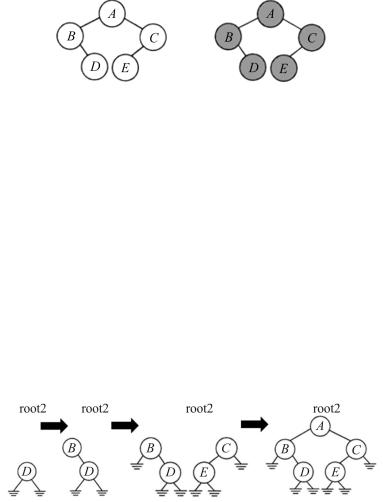
Функция копирования принимает корень исходного дерева и создает его дубликат (рис. 22.23).
Рис. 22.23. Копирование дерева: оригинал и дубликат
Она использует для посещения узлов обратный метод прохождения, гарантирующий, что спустимся по дереву на максимальную глубину, прежде чем начнем операцию посещения, которая создает узел для нового дерева (рис. 22.24).
Таким образом, функция копирования строит новое дерево снизу вверх:
Tree<T>* Tree<T>::copyTree() {
Tree<T>* tree = new Tree<T> (this->data); if (this->parent != NULL)
tree->parent = this->parent; if (this->left != NULL)
tree->left = this->left->copyTree(); if (this->right != NULL)
tree->right = this->right->copyTree(); return tree;
}
Рис. 22.24. Схема копирования дерева поэтапно
25
22.4. Бинарные деревья поиска
Определение и свойства
Бинарные деревья часто используются для представления множества данных, элементыкоторого находятся по уникальному ключу.
Бинарное дерево поиска – это двоичное дерево, для которого выполняются следующие дополнительные условия (свойства дерева поиска):
•Оба поддерева, левое и правое, являются бинарными деревьями поиска.
•У всех узлов левого поддерева произвольного узла X значения ключей данных меньше, нежели значение ключа данных самого узла X.
•У всех узлов правого поддерева произвольного узла X значения ключей данных больше либо равны, нежели значение ключа данных самого узла X.
Очевидно, данные в каждом узле должны обладать ключами, на которых определена операция сравнения «меньше».
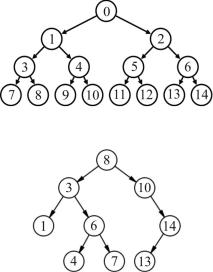
Два бинарных дерева поиска представлены нарис. 22.25 и22.26.
Рис. 22.25. Первый пример бинарного дерева поиска
Рис. 22.26. Второй пример бинарного дерева поиска
26
22.5. Программа для работы с бинарным деревом поиска
Заголовочный файл tree.h – класс SearchTree
Можно не рассматривать функции класса SearchTree, которые по принципу работы повторяют или достаточно похожи на ранее разобранные функции класса Tree.
В связи с тем, что ранее многое уже было рассказано, для простоты создадим новый класс и объявим прототипы только части функций, аналогичных функциям класса Tree, плюс некоторые новые, с которыми нам предстоит познакомиться в дальнейшем:
template <class S> class SearchTree {
public:
S data; // Данные типа Т
SearchTree* left; // Указатель на узел слева SearchTree* right; // Указатель на узел справа
SearchTree* parent; // Указатель на предка SearchTree(S); // Конструктор ~SearchTree(); // Деструктор
void deleteSearchTree() { delete this; }
// Удалить дерево
void printSearchTree(int);
// Горизонтальная печать дерева void inOrder(SearchTree<S>*);
// Симметричный обход дерева void setData(Sdt) {data = dt;}
// Установить данные для узла
SearchTree<S>* next(); // Найти следующий элемент SearchTree<S>* prev(); // Найти предыдущий элемент void insertNode(S); // Вставить узел
void deleteNode(S); // Удалить узел SearchTree<S>* findElement(S); // Найти элемент SearchTree<S>* findMax(); // Найти максимум SearchTree<S>* findMin(); // Найти минимум
};
27
Поиск элемента
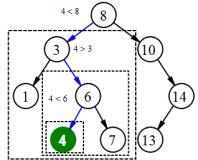
Для поиска элемента в бинарном дереве поиска можно воспользоваться следующей функцией, которая принимает в качестве параметра искомый ключ. Для каждого узла функция сравнивает значение его ключа с искомым ключом. Если ключи одинаковы, то функция возвращает текущий узел, в противном случае функция вызывается рекурсивно для левого или правого поддеревьев (рис. 22.27):
template <class S>
SearchTree<S>* SearchTree<S>::findElement(S dt) { if ((this == NULL) || (dt == this->data))
return this;
if (dt<this->data) return this->left->findElement(dt); else return this->right->findElement(dt);
}
Рис. 22.27. Схема нахождения элемента 4 для данного дерева
Поиск минимального/максимального элемента по ключу
Минимальный/максимальный элемент – самый левый/правый элемент поддерева с данным корнем.
Чтобы найти минимальный элемент в бинарном дереве поиска, необходимо просто следовать указателям left от корня дерева, пока не встретится значение NULL. Если у вершины есть левое поддерево, то по свойству бинарного дерева поиска в нем хранятся все элементы с меньшим ключом. Если его нет, значит, эта вершина и есть минимальная.
28
Аналогично находится и максимальный элемент. Для этого нужно следовать правым указателям:
template <class S>
SearchTree<S>* SearchTree<S>::findMin() { if (this->left == NULL) return this; return this->left->findMin();
}
template <class S>
SearchTree<S>* SearchTree<S>::findMax() { if (this->right == NULL) return this; return this->right->findMax();
}
Нахождение предыдущего/следующего элемента (по ключу)
Если у узла есть правое поддерево, то следующий за ним элемент будет минимальным элементом в этом поддереве. Если у него нет правого поддерева, то нужно следовать вверх, пока не встретим узел, который является левым дочерним узлом своего родителя. Поиск предыдущего выполняется аналогично. Если у узла есть левое поддерево, то следующий за ним элемент будет максимальным элементом в этом поддереве. Если у него нет левого поддерева, то нужно следовать вверх, пока не встретим узел, который является правым дочерним узлом своего родителя.
Влистинге ниже первая функция ищет следующий элемент,
авторая – предыдущий:
template <class S>
SearchTree<S>* SearchTree<S>::next() { SearchTree* tree = this;
if (tree->right != NULL) return tree->right->findMin();
SearchTree<S>* t = tree->parent;
while ((t!=NULL) && (tree==t->right)) { tree = t;
t = t->parent;
}
29
return t;
}
template <class S>
SearchTree<S>* SearchTree<S>::prev() { SearchTree* tree = this;
if (tree->left != NULL)
return tree->left->findMax(); SearchTree<S>* t = tree->parent;
while ((t != NULL) && (tree == t->left)) { tree = t;
t = t->parent;
}
return t;
}
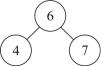
Рис. 22.28. Пример родителя с двумя потомками
Следующий для 4 – это 6, следующий для 6 – это 7, следующий для 7 – это NULL (не существует). Предыдущий для 4 – это NULL (не существует), предыдущий для 6 – это 4, следующий для 7 – 6 (рис. 22.28).
Вставка узла
Как уже было сказано ранее, бинарное дерево поиска – это бинарное дерево, обладающее дополнительными свойствами: значение левого потомка меньше значения родителя, а значение правого потомка больше или равно значению родителя для каждого узла дерева. Иными словами, данные в бинарном дереве поиска хранятся в отсортированном виде. При каждой операции вставки нового или удаления существующего узла порядок дерева сохраняется.
На основе этого создадим функцию добавления узлов
(рис. 22.29):
30