

Z9411_КафкаРС_ВВАД_ЛР
.docxМИНИСТЕРСТВО НАУКИ И ВЫСШЕГО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
федеральное государственное автономное образовательное учреждение высшего образования
«САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ АЭРОКОСМИЧЕСКОГО ПРИБОРОСТРОЕНИЯ»
ИНСТИТУТ НЕПРЕРЫВНОГО И ДИСТАНЦИОННОГО ОБРАЗОВАНИЯ
КАФЕДРА 41
|
ОЦЕНКА
ПРЕПОДАВАТЕЛЬ
д-р техн. наук, профессор |
|
|
|
Т. М. Татарникова |
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ОТЧЁТ О ЛАБОРАТОРНОЙ РАБОТЕ №1
|
Кластеризация данных
|
по дисциплине: Введение в анализ данных |
РАБОТУ ВЫПОЛНИЛ
СТУДЕНТ ГР. № |
Z9411 |
|
|
|
Р. С. Кафка |
|
номер группы |
|
подпись, дата |
|
инициалы, фамилия |
Студенческий билет № |
2019/3603 |
|
|
|
|
Шифр ИНДО |
|
Санкт-Петербург 2023
Цель работы: изучить алгоритмы и методы кластерного анализа на практике.
Порядок выполнения
Получить у преподавателя набор данных для проведения кластерного анализа, при необходимости провести нормализацию и кодирование данных.
Провести предварительную обработку данных, как в 1 ЛР.
Выполнить кластеризацию объектов
иерархическим агломеративным методом
выбрать подходящую метрику расстояния;
построить дендрограмму;
рассчитать оптимальное число кластеров.
методом k-средних.
задать число кластеров;
рассчитать евклидово расстояние между кластерами;
определить объекты, относящиеся к каждому кластеру;
рассчитать оптимальное число кластеров
Опишите полученные кластеры в терминах предметной области, дайте каждому кластеру условное наименование с учетом значимости признаков, повлиявших на выделение кластеров.
Сделать выводы по работе
Вариант задания с кратким описанием набора данных:
Вариант 1, данные содержат информацию о сердечных болезнях:
Age - содержит возраст пациентов, число не отрицательное.
Sex - содержит пол пациентов: пишется M или F.
ChestPainType - тип боли в груди, содержит 4 значения: TA: типичная стенокардия, ATA: атипичная стенокардия, NAP: неангинальная боль, ASY: бессимптомная.
RestingBP - артериальное давление в покое, число.
Cholesterol - холестерин сыворотки, число.
FastingBS - указывается если уровень сахара в крови натощак > 120 мг/дл, содержит значения '0' или '1'.
RestingECG - Результаты электрокардиограммы в покое, содержит значения 'Normal' - , 'ST' - аномалия, 'LVH' - гипертрофия.
MaxHR - максимальная достигнутая частота сердечных сокращений [Числовое значение от 60 до 202]
ExerciseAngina - стенокардия, вызванная физической нагрузкой, значения: 'Y' или 'N'.
Oldpeak - депрессия ST, вызванная физической нагрузкой, по сравнению с состоянием покоя. Содержит значения небольшие числа, как положительные, так и отрицательные.
ST_Slope - наклон пикового сегмента ST при нагрузке. Содержит значения 'Up' - восходящий, 'Flat' - плоский, 'Down' - нисходящий.
HeartDisease - выходной класс. Сожержит значения '1' - болезнь сердца, '0': нормальный.
Ход работы:
Предварительная обработка данных
В качестве среды разработки был выбран блокнот Colab — это бесплатная интерактивная облачная среда для работы с кодом на языке Python от Google в браузере: https://colab.research.google.com/.
Первым делом загружаются необходимые библиотеки для лабораторной работы.
 Рисунок
1 – Список загруженных библиотек для
кода
Рисунок
1 – Список загруженных библиотек для
кода
Этот код использует несколько библиотек Python:
pandas - библиотека для работы с данными в табличном формате.
csv - модуль для чтения и записи файлов в формате CSV.
matplotlib - библиотека для создания графиков и визуализации данных.
numpy - библиотека для работы с многомерными массивами и математическими операциями над ними.
scikit-learn - библиотека для машинного обучения, которая содержит реализации алгоритмов кластеризации KMeans и AgglomerativeClustering, а также инструменты для предварительной обработки данных (StandardScaler) и оценки качества кластеризации (silhouette_score).
scipy - библиотека для научных вычислений, которая содержит функции для иерархической кластеризации (dendrogram, linkage) и вычисления расстояний (distance).
yellowbrick - библиотека для визуализации машинного обучения, которая содержит инструмент KElbowVisualizer для определения оптимального числа кластеров.
seaborn - библиотека для статистической визуализации данных.
Специально для Google Colab загружается необходимый файл csv.
 Рисунок
2 – Загрузка набора данных
Рисунок
2 – Загрузка набора данных
Для того чтобы убедиться, что данные загрузились корректно, на экран выводятся первые 10 строк из файла.
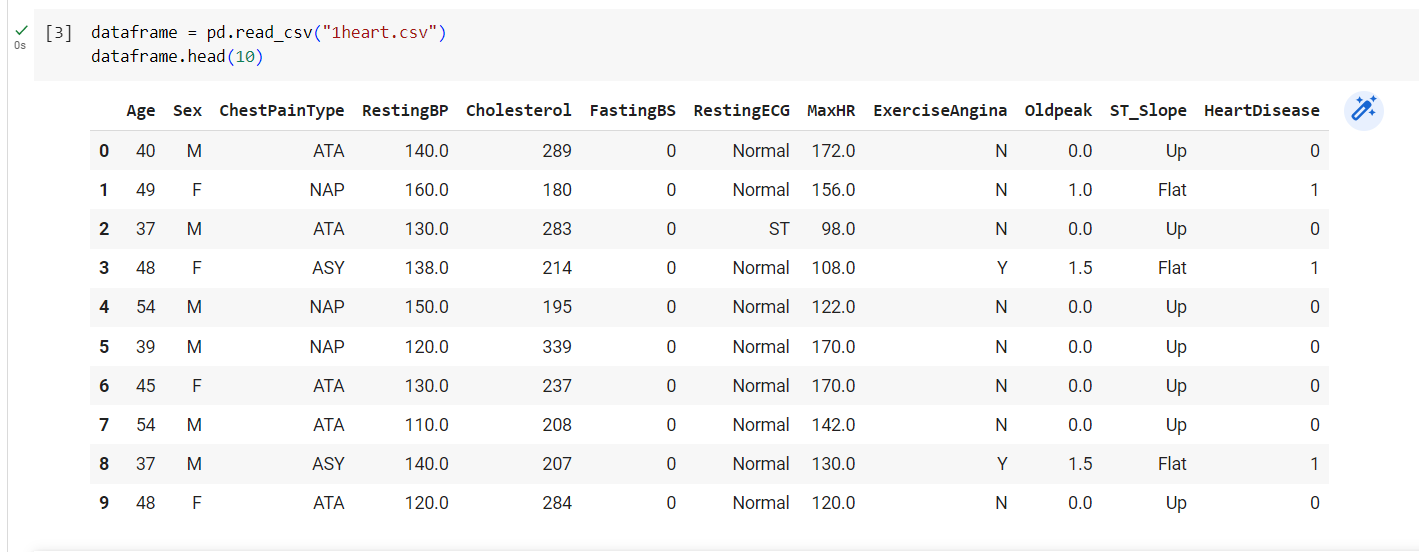 Рисунок
3 – Вывод первых строк данных
Рисунок
3 – Вывод первых строк данных
Далее необходимо оценить данные.
 Рисунок
4 – Оценка данных
Рисунок
4 – Оценка данных
По оценке данных мы можем заметить, что некоторые данные есть с пустыми значениями. Получается, что есть пропуски в данных. С помощью метода df.isna().sum() видно, что есть в сумме 5 пропусков, от которых нужно избавиться.
 Рисунок
5 – Пропуски в данных
Рисунок
5 – Пропуски в данных
Выполняем дополнительную обработку данных для удаления дубликатов. Для этого воспользуемся методом dropna(), который удаляет строку или колонку, в которой встречается NaN (хотя бы один пропуск). В данном случае были удалены строки.
 Рисунок
6 – Удаление строк с пустыми значениями
Рисунок
6 – Удаление строк с пустыми значениями
Пустые значения были удалены, а значит, можно приступать к поиску дубликатов.
Явные дубликаты рациональнее удалять уже после устранения неявных, а именно замены, объектов, имеющих немного отличающиеся названия, но при этом являющихся одним и тем же объектом по сути.
С помощью метода `unique` и `sort` на экран выводятся все, что есть в столбцах по возрастанию. Сортировка нужна, чтобы было легче искать дубликаты.
 Рисунок
7 – Поиск дубликатов 1 часть
Рисунок
7 – Поиск дубликатов 1 часть
 Рисунок
8 – Поиск дубликатов 2 часть
Рисунок
8 – Поиск дубликатов 2 часть
 Рисунок
9 – Поиск дубликатов 3 часть
Рисунок
9 – Поиск дубликатов 3 часть
Были обнаружены некорректные значения, а именно в колонках «Sex» - пол «Ma», «Cholesterol» - значение «'a241'», «ST_Slope» - значения «UP» и «Up» с разным регистром и учитываются как разные значения.
Неправильные и альтернативные написания значений были исправлены методом replace(). В первом аргументе ему передают нежелательное значение из таблицы. Во втором - новое значение, которое должно заменить дубликат.
 Рисунок
10 – Исправление неправильных значений
данных
Рисунок
10 – Исправление неправильных значений
данных
Далее производится проверка на наличие явных дубликатов, и таковых было обнаружено 5 штук.
 Рисунок
11 – Поиск явных дубликатов
Рисунок
11 – Поиск явных дубликатов
Чтобы избавиться от таких дубликатов используется метод drop_duplicates().
После удаления строчек обновляем индексацию: чтобы в ней не осталось пропусков. Для этого применяется метод `reset_index()`. Он создаст новый датафрейм, где:
индексы исходного датафрейма станут новой колонкой с названием `index`;
все строки получат обычные индексы, уже без пропусков.
 Рисунок
12 – Удаление явных дубликатов и обновление
индексации данных
Рисунок
12 – Удаление явных дубликатов и обновление
индексации данных
С помощью метода df.dtypes производится проверка типов данных столбцов.
 Рисунок
13 – Проверка типов данных столбцов
Рисунок
13 – Проверка типов данных столбцов
Необходимо поменять тип данных столбца "Cholesterol" на целочисленный, а после ещё раз проверить правильность. У столбцов "FastingBS" и "HeartDisease" тип данных не будет изменён с целочисленного, на булевский, т.к. это помешает дальнейшему построению графиков.
 Рисунок
14 – Изменение типа данных столбца
«Cholesterol»
Рисунок
14 – Изменение типа данных столбца
«Cholesterol»
Столбцы с типом данных «object» будут удалены непосредственно перед кластеризацией.
Кластеризация
Иерархический агломеративный метод
Для кластеризации необходимо убрать целевой столбец HeartDisease. И также уберём все столбцы, где не численные значения, чтобы убрать качественные признаки и делать кластеризацию только по числовым столбцам.
 Рисунок
15 – Удаление столбцов данных
Рисунок
15 – Удаление столбцов данных
Создаётся объект класса scaler, далее он обучается по текущему набору данных, а после данные стандартизируются.
 Рисунок
16 – Создание, обучение и преобразование
объекта
Рисунок
16 – Создание, обучение и преобразование
объекта
По этим данным строится дендрограмма.
 Рисунок
17 – Код для построения дендрограммы
Рисунок
17 – Код для построения дендрограммы
 Рисунок
18 – Иерархическая кластеризация по
сердечным болезням пациентов
Рисунок
18 – Иерархическая кластеризация по
сердечным болезням пациентов
Оптимальное число кластеров, судя по дендрограмме - 4. Некоторые значения встречаются в разных кластерах (41, 39, 12 и т.д.). Из этого следует, что текущие данные невозможно распределить по однозначно определённым кластерам, а, значит, могут быть получены неверные результаты.
Метод k-средних
Для выбора оптимального количества кластеров воспользуемся методом локтя.
 Рисунок
19 – Метод локтя
Рисунок
19 – Метод локтя
Метод локтя показал, что оптимальным числом кластеров является 3.
Проверям, для какого количества кластеров кластеризация будет наиболее качественной.
Задаётся количество кластеров, равное 4, а далее изучаем набор данных.
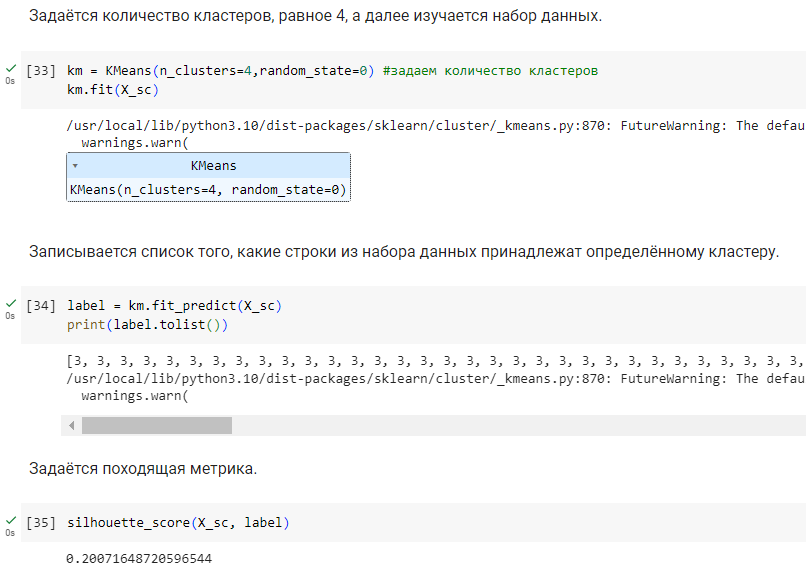 Рисунок
20 – Метрика при делении на 4 кластера
Рисунок
20 – Метрика при делении на 4 кластера
Задаётся количество кластеров, равное 3, а далее изучается набор данных.
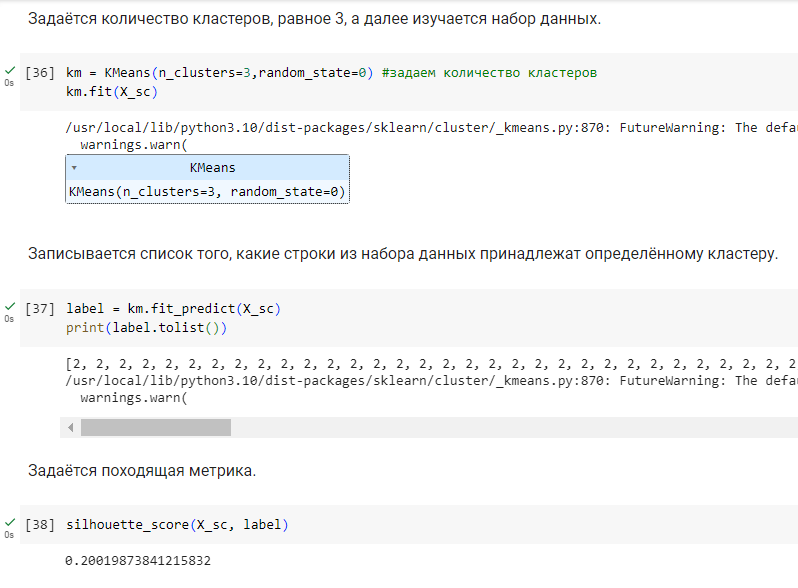 Рисунок
21 – Метрика при делении на 3 кластера
Рисунок
21 – Метрика при делении на 3 кластера
Задаётся количество кластеров, равное 2, а далее изучается набор данных.
 Рисунок
22 – Метрика при делении на 2 кластера
Рисунок
22 – Метрика при делении на 2 кластера
По метрикам видно, что кластеризация ни в одном из случаев не может быть проведена качественно, однако деление на 4 кластера показало наиболее лучший результат. Именно такое количество кластеров будет задаваться для метода k-средних.
Выводятся центроиды кластеров.
 Рисунок
23 – Центроиды кластеров
Рисунок
23 – Центроиды кластеров
Вычисляется Евклидово расстояние между кластерами, и оно записывается в матрицу, где элемент aij матрицы - Евклидово расстояние между кластерами i и j соответственно.
 Рисунок
24 – Евклидово расстояние между кластерами
Рисунок
24 – Евклидово расстояние между кластерами
В набор данных добавляется ещё один столбец - cluster, который показывает, к какому из двух кластеров принадлежит данная строка. Также выводятся первые 15 строк набора данных, чтобы убедиться, что этот столбец добавлен.
 Рисунок
25 – Добавление столбца cluster
Рисунок
25 – Добавление столбца cluster
С помощью метода describe() просматриваются средние значения по каждому из столбцов, а также их средние отклонения.
 Рисунок
26 – Средние значения данных.
Рисунок
26 – Средние значения данных.
Строится график деления клиентов по столбцу «HeartDisease» с помощью команды sns.pairplot(dataframe, hue = 'HeartDisease').
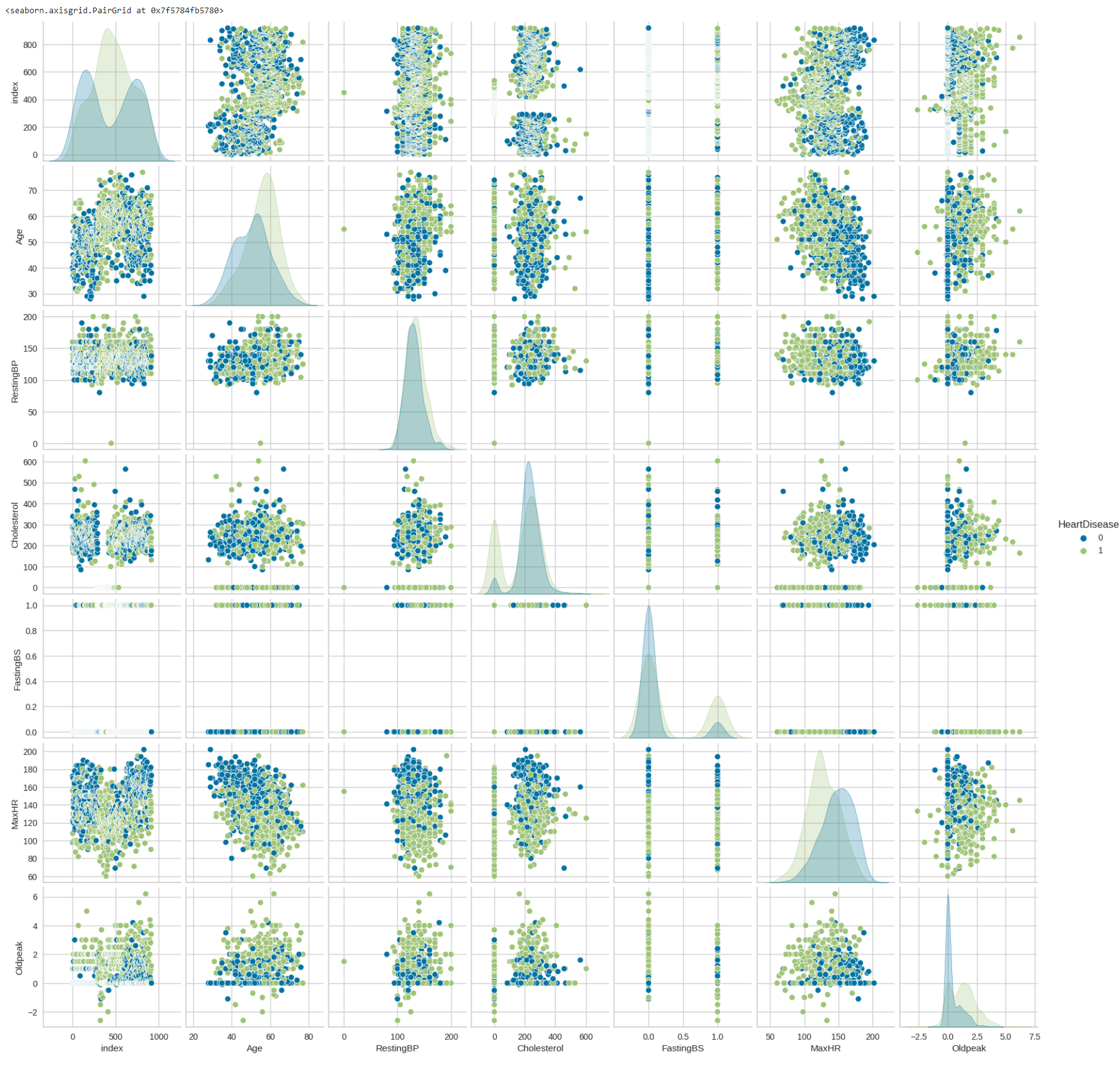 Рисунок
27 – График деления клиентов по столбцу
«HeartDisease»
Рисунок
27 – График деления клиентов по столбцу
«HeartDisease»
Исходя из графика, нельзя точно определить, какие именно признаки оказывают наибольшее влияние на признак.
ВЫВОД
В ходе выполнения лабораторной работы я изучил алгоритмы и методы кластерного анализа на практике. Я выполнил кластеризацию объектов с помощью иерархического агломеративного метода и метода k-средних. Я выбрал подходящую метрику расстояния, построил дендрограмму и рассчитал оптимальное число кластеров. Я также описал полученные кластеры в терминах предметной области и дал каждому кластеру условное наименование с учетом значимости признаков, повлиявших на выделение кластеров.
В результате работы я пришел к выводу, что кластеризация может быть полезным инструментом для анализа данных и выделения групп объектов с похожими характеристиками. Однако, необходимо тщательно подбирать параметры алгоритмов кластеризации и проводить предварительную обработку данных для достижения наилучших результатов. В целом, лабораторная работа была интересной и познавательной.
Посмотреть на реализацию лабораторной работы в Colab можно по следующей ссылке:
https://colab.research.google.com/drive/1PEc2ILK2NWmac-DjqrdPqrcuEaZgqyUC?usp=sharing