

Лабораторная работа №4 Применение методов классификации
Цель работы: изучить алгоритмы и методы классификации на практике.
Краткий теоретический материал
EDA
Прежде чем отправить данные на вход модели и получить прогнозы, проводят «разведку данных» — EDA, или исследовательский анализ данных. На этом этапе вы изучаете распределения отдельных признаков и целевой переменной, строите корреляции между величинами, исследуете специфику датасета. Бывает полезно построить график оценки плотности ядра признаков. Этот график похож на гистограмму, только представляет из себя линию, которая проходит по вершинам столбцов гистограммы. При этом углы сглаживаются. В библиотеке seaborn такие графики отрисовывают методом kdeplot().
Разведка данных позволит сформулировать первые гипотезы относительно качества данных и аномалий в них. Уже на этом шаге можно предположить, какие признаки станут ключевыми для модели, а какими можно и даже нужно пренебречь.
Подготовка данных
Данные необходимо преобработать, а именно:
•обрабатывают пропущенные значения;
•преобразуют отдельные признаки (например, переводят категориальные признаки в количественные);
•нормализуют или стандартизируют данные (;
•создают новые признаки (фичи) на основе уже существующих. Этот этап ещё называют feature engineering (англ. «проектирование признаков»), и иногда он может вывести вашу модель на совершенно новый уровень качества.
Тестовая, валидационная и обучающая выборки
Например, задача бинарной классификации — научиться прогнозировать, останется пользователь в следующем месяце или перейдёт к конкуренту.
У нас есть данные о 15 000 клиентов, в том числе ушел ли пользователь после месяца.
Модель нужно обучить так, чтобы она предсказывала отток настоящих и будущих пользователей. Прежде чем передавать на вход модели реальные данные, нужно понять, хорошо ли она работает. Можно обучить модель, а со следующего месяца сравнивать её прогнозы с действительными целевыми переменными.
Реальные данные, которые попадают на вход модели после её разработки, называют тестовая выборка (англ. test data). Однако перед тем
как оценивать качество модели, аналитики проверяют её работу на валидационной выборке (англ. validation data).
Возьмём 15 000 наблюдений. Разделим их на две неравные части — например, на 10 и 5 тысяч. Передадим первую порцию данных в модель и подождём, пока алгоритм обучится на них. Затем предложим модели предсказать ответы для второй порции и сравним, насколько прогнозы совпадают с реальными значениями целевой переменной.
Часть данных (10 тысяч), которую подают на вход модели при обучении, называют обучающая выборка (англ. train data). Те данные, на которых
модель |
проверяют |
(5 |
тысяч), |
называют валидационная |
выборка (англ. validation data), или отложенная. |
|
|||
Выбор алгоритма
В зависимости от типа задач (с учителем или без) и поставленной проблемы, у вас есть целый арсенал различных алгоритмов со своими достоинствами и недостатками. Одни алгоритмы точнее, но их сложно интерпретировать; другие — быстрые, но притом слабее. Вот основные критерии выбора алгоритма:
•Точность;
•Скорость;
•Интерпретируемость;
•Индивидуальные особенности алгоритмов: на разных типах признаков они работают по-разному.
Даже у самого простого алгоритма есть множество настраиваемых
параметров. Иногда они могут повлиять на качество и скорость обучения вашей модели. Чаще всего выбор параметров происходит итеративно. Вы обучаете модель с одними параметрами, оцениваете метрики, видите, что они так себе — меняете параметры, снова обучаете и проверяете качество. Это можно делать бесконечно, но мы научим вас останавливаться вовремя.
Выбор метрик
Прежде чем обучать алгоритм, определитесь, как будете оценивать его качество.
Для каждого типа задач (классификация, регрессия, кластеризация) есть стандартный набор метрик. Однако важно не просто «прогнать» результаты через этот набор, а понять, какая метрика лучше всего отражает суть бизнеспроцесса.
Обучение и прогнозирование fit-predict.
В sklearn много инструментов работы с данными и моделей, поэтому они разложены по подразделам.
Например, в модуле tree (англ. «дерево») находится решающее дерево.
Каждой модели в sklearn соответствует отдельная структура данных. DecisionTreeClassifier (англ. «классификатор дерева решений») — это структура данных для классификации деревом решений.
from sklearn.tree import DecisionTreeClassifier
Затем создаём объект этой структуры данных.
model = DecisionTreeClassifier()
В переменной model (англ. «модель») будет храниться модель. Правда, она пока не умеет предсказывать. Чтобы научилась, нужно запустить алгоритм обучения.
На вход модели передают набор значений признаков X и целевую переменную y. А у вас есть датафрейм, где есть столбец со значениями целевой переменной и остальные столбцы.
Например, у вас есть таблица data. В ней столбец с целевой переменной называется 'target'. Чтобы задать матрицу объект-признак X и вектор целевой переменной y, применим метод drop() библиотеки Pandas:
y = data['target']
X = data.drop(['target'], axis=1)
Методу передают список с названиями столбцов, которые нужно удалить. Параметр axis = 1 указывает, что избавиться нужно именно от колонки.
Теперь уже можно построить взаимосвязь и на её основании спрогнозировать y по новым X.
Чтобы запустить обучение, вызовите метод fit() (англ. «подогнать») и передайте ему как параметр данные:
model.fit(X, y)
Здесь вы передаёте на вход модели для обучения матрицу с признаками X и вектор со значениями целевой переменной.
Чтобы построить прогнозы для набора данных, хватит одной строчки кода и вызова метода predict() (англ. «предсказывать»):
predictions = model.predict(X)
Итак, на стадии fit вы передаёте подготовленную порцию данных (train- выборку), алгоритм на ней обучается и строит взаимосвязи между признаками.
Переходим к predict. У вас осталась отложенная порция данных, для которых вы знаете признаки и ответы. На этом этапе вы берёте только признаки, передаёте их на вход обученной модели и сохраняете предсказанные значения.
Оценка качества результатов и выбор лучшей модели
На этом шаге вы определяете, насколько спрогнозированные вами значения для объектов из валидационной выборки отличаются от реальных. Часто оценивают не один, а несколько алгоритмов и на основании выбранных метрик выбирают лучший.
Оценка важности признаков
Вы выбрали самый успешный алгоритм, который показывает лучший в сравнении с другими алгоритмами результат. Чаще всего этого недостаточно, чтобы начать использовать вашу модель. Нужно ещё раз убедиться, что модель отразила правильные паттерны и взаимосвязи между данными. Как это сделать? Например, применив анализ важности признаков. Этот набор подходов позволяет оценить не только что предсказала модель, но и почему.
Что дальше?
Вы нашли данные, преобразовали их, разделили на обучающую и валидационную выборки, выбрали несколько подходящих алгоритмов. Дальше fit-predict. Выбрали лучшую модель, проинтерпретировали важность признаков и даже сами поверили в то, что она работает.
На самом деле всё не так просто: вы проходите пайплайн один раз, а потом чаще всего возвращаетесь на предыдущие этапы, что-то меняете и смотрите, как преобразился результат. Это совершенно нормально.
Метрики классификации на основе значений прогнозного класса
Сначала рассмотрим метрики, которые берут в расчёт только итоговое спрогнозированное значение — 0 или 1:
•Матрица ошибок (англ. confusion matrix)
•Доля правильных ответов (англ. accuracy)
•Точность (англ. precision) и полнота (англ. recall)
•F1_score
Матрица ошибок
Возможные значения классов: 0 и 1. И ваша модель тоже может выдавать итоговый прогноз в виде значения одного из двух классов. Тогда для каждого объекта прогноз относится к одной из четырех групп:
•Прогноз модели = 1, реальное значение = 1. Такие прогнозы называют True Positive («истинно положительные») — сокращённо TP.
•Прогноз модели = 1, реальное значение = 0. Такие прогнозы называют False Positive («ложно положительные») — сокращённо FP.
•Прогноз модели = 0, реальное значение = 1. Такие прогнозы называют False Negative («ложно отрицательные») — сокращённо FN.
•Прогноз модели = 0, реальное значение = 0. Такие прогнозы
называют True Negative («истинно отрицательные») — сокращённо TN.
У хорошей модели бóльшая часть прогнозов должна попадать в группы
TP и TN.

Матрица ошибок отражает количество наблюдений в каждой группе. Выглядит она так:
Расчёт матрицы ошибок реализован в sklearn в модуле metrics. Можно задать и переменные TN, FP, FN, TP:
from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_true,y_pred)
tn, fp, fn, tp = cm.ravel() # "выпрямляем" матрицу, чтобы вытащить нужные значения
Функция confusion_matrix() возвращает матрицу вида [[TN, FP], [FN, TP]].
Метод .ravel() позволяет преобразовать матрицу к сводному (одномерному) списку [TN, FP, FN, TP].
По матрице ошибок вы можете понять, как именно склонен ошибаться ваш алгоритм. Есть ли у него перекос в сторону позитивного класса (чрезмерный оптимизм, слишком много FP). Или наоборот, он перестраховывается, и увеличена группа FN, как у пессимистов.
Для остальных метрик итогового прогноза классов справедливы термины, введённые для матрицы ошибок.
Доля правильных ответов
Долю правильных ответов вычисляют так:
Это доля верно угаданных ответов из всех прогнозов. Чем ближе значение accuracy к 100%, тем лучше.
Метрику рассчитывают функцией accuracy_score из модуля metrics. На вход функция принимает верные и спрогнозированные значения классов на валидационной выборке:
acc = accuracy_score(y_true, y_pred)
accuracy работает не всегда, а только при условии баланса классов — когда объектов каждого класса примерно поровну, 50% : 50%. И вот почему.

Представьте, что классы не сбалансированные: всего 1% класса "1" среди выборки, а оставшиеся объекты относятся к классу "0". Тогда безо всякого алгоритма вы можете придерживаться железной стратегии — всегда прогнозировать класс "0". Метрика accuracy — целых 99%! И не нужно никакого машинного обучения.
В таких случаях оценивать качество модели нужно другими метриками.
Точность (precision) и полнота (recall)
Чтобы оценить модель без привязки к соотношению классов, рассчитывают метрики:
precision говорит, какая доля прогнозов относительно "1" класса верна.
То есть смотрим долю правильных ответов только среди целевого класса. В бизнесе метрика precision нужна, если каждое срабатывание (англ. alert) модели — факт отнесения к классу "1" — стоит ресурсов. А вы не хотите, чтобы модель часто «срабатывала попусту». Например, когда вы принимаете решение, выдавать клиенту кредит или нет, ситуация невозврата более неприятна, чем невыдача.
Вторая метрика нацелена на минимизацию противоположных рисков
— recall показывает, сколько реальных объектов "1" класса вы смогли обнаружить с помощью модели. Эта метрика полезна при диагностике заболеваний: лучше отправить пациента на повторное обследование и узнать, что тревога была ложной, чем прозевать настоящий диагноз.
Каждая метрика принимает значения от 0 до 1. Чем ближе к единице, тем лучше. Однако при настройке параметров модели — обычно порога вероятности, после которого мы относим объект к классу "1" — оптимизация одной метрики часто приводит к ухудшению другой. Настраивая параметры модели, вы балансируете между этими двумя показателями. Окончательное решение принимайте, исходя из целей работы.
Метрики точности и полноты также реализованы в модуле metrics в функциях precision_score и recall_score; имеют схожий с другими метриками синтаксис:
precision = precision_score (y_true, y_pred) recall = recall_score (y_true, y_pred)
Обе функции возвращают число от 0 до 1.
F1-мера
Так как precision и recall направлены на избежание противоположных рисков, нужна сводная метрика, учитывающая баланс между метриками.
Это F1-score:
В sklearn.metrics F1-меру вычисляют методом f1_score: f1= f1_score(y_true, y_pred)
Функция также возвращает одно число от 0 до 1. Чем ближе к единице, тем лучше.
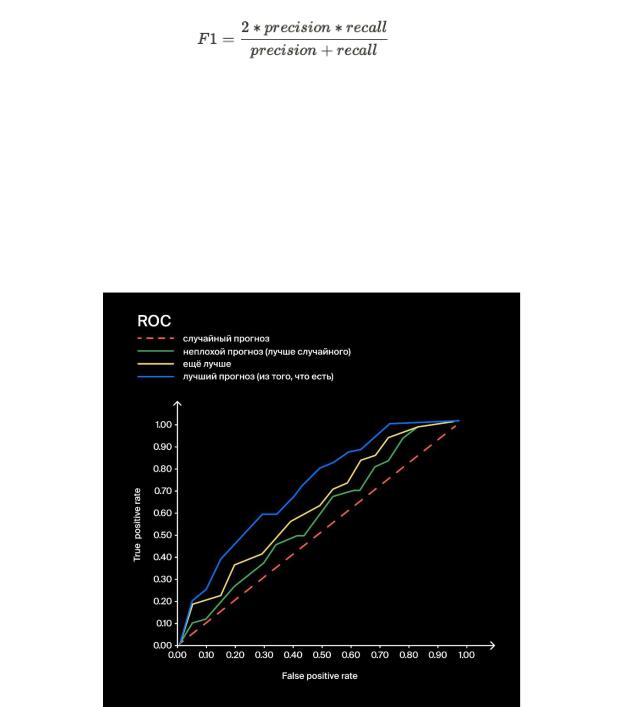
ROC - кривая
Для оценки качества классификатора (модели классификации)
применяют метрику roc_auc, или площадь под кривой ошибок — AUCROC (от англ. Area Under Curve, «площадь под кривой», Receiver Operating Characteristic, «рабочая характеристика приёмника»).
Метрика roc-auc реализована в модуле metrics под названием roc_auc_score:
roc_auc = roc_auc_score(y_true, probabilities[:,1])
На вход этой функции подаются вектор реальных ответов y_true и вектор вероятности отнесения объекта к классу "1". Для этого из вектора пар вероятностей отнесения объекта к классу "0" и "1", берут лишь вторые числа (probabilities[:,1]). На выходе этой функции получаем одно число в пределах от 0 (чаще от 0.5) до 1.
Регуляризация
Простые линейные модели нетрудно реализовать и легко
интерпретировать. Однако |
и они |
дают |
сбои. |
Например, из- |
за мультиколлинеарности. |
|
|
|
|
Мультиколлинеарность |
возникает, |
когда |
есть |
группа линейно |
зависимых признаков — взаимозависимых или очень сильно скоррелированных. Скажем, если в датасет «просочились» два признака, отвечающие за одно и то же расстояние. Один — в метрах, другой — в километрах. Или признаки просто очень связаны — как температура воды в пруду и температура воздуха.
Если коэффициент корреляции между двумя признаками слишком большой (часто больше 0.8), с линейной регрессией возникнут проблемы.
Как с этим бороться? Оставить только признаки, корреляция между которыми не превышает высокого порога (скажем, 0.8). Например, вычислить
матрицу корреляций |
методом corr() и |
для |
каждой |
пары сильно |
|
скоррелированных признаков вручную удалить один |
|
||||
Кроме |
ручного |
удаления |
скоррелированных |
признаков, |
|
есть регуляризация. В |
общем смысле |
это |
любое дополнительное |
||
ограничение на модель или какое-то действие, которое позволяет снизить её сложность и влияние эффекта переобучения. У линейных моделей регуляризация — ограничение веса.
Порядок выполнения
1.Получить у преподавателя набор данных для проведения классификации, при необходимости провести нормализацию и кодирование данных.
2.Провести предварительную обработку данных, как в 1 ЛР.
3.Выявить, что будет являться целевым признаком (откликом).
4.Разбить набор данных на тренировочной и тестовый датасеты с помощью train_test_split.
5.Разработать предсказательную модель качественного отклика методами:
- метод k- ближайших соседей - логистическая регрессия - случайный лес.
На оценку 5 выполнять все три метода. На оценку 4 – 2 метода.
6.Оценить ошибку классификации. Подсчитать метрики "Accuracy", "Precision", "Recall", "Balanced accuracy", 'F1 score'.
7.Построить матрицу неточностей с помощью confusion_matrix.
8.Построить график ROC-кривой.
9.Сделать вывод о качестве построенного классификатора по подсчитанным выше метрикам.
Содержание отчета
1.Титульный лист
2.Цель работы
3.Вариант задания с кратким описанием набора данных
4.Пояснения и скриншоты по каждому пункту выполнения лабораторной работы
5.Ссылка на ваш Jupyter-ноутбук
6.Расширенный вывод по вашему исследованию