

ГУАП
КАФЕДРА №41
ОТЧЕТ ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
ассистент |
|
|
|
В.В. Боженко |
|
|
|
|
|
|
|
|
|
|
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ №4
ПРИМЕНЕНИЕ МЕТОДОВ КЛАССИФИКАЦИИ
по курсу: Введение в анализ данных
РАБОТУ ВЫПОЛНИЛ
СТУДЕНТ ГР. №
подпись, дата |
|
инициалы, фамилия |
Санкт-Петербург 2022
Цель работы
Изучение алгоритмы и методы классификации на практике.
Индивидуальный вариант
Индивидуальный вариант номер 10 в соответствии с таблицей 1.
Таблица 1 – Индивидуальный вариант задания
Название |
|
Пояснение |
датафрейма |
|
|
|
|
|
5gym_churn.csv |
Информация о клиентах фитнес клуба: |
|
|
1. |
Пол |
|
2. |
Близкое расположение |
|
3. |
Сотрудник компании партнера |
|
4. |
По промо друзей |
|
5. |
Указан ли телефон |
|
6. |
Длительность текущего абонемента |
|
7. |
Посещение групповых занятий |
|
8. |
Возраст |
|
9. |
Средние траты на доп услуги |
|
10. |
Количество месяцев до окончания абонемента |
|
11. |
Время с момента первого обращения в фитнес-центр (в месяцах) |
|
12. |
Средняя частота посещений в неделю за все время с начала |
|
|
действия абонемента |
|
13. |
Средняя частота посещений в неделю за предыдущий месяц |
|
14. |
Churn – факт ухода из клуба |
2

Ход работы
1. Получили у преподавателя набор данных 5gym_churn.csv в соответствии с индивидуальным вариантом №10 для проведения анализа согласно цели выполняемой работы.
Загрузили датасет с помощью библиотеки pandas в Jupyter-ноутбуке в соответствии с рисунком 1.
Рисунок 1 – Загрузка датаcета в Colab из файла 5gym_churn.csv на Google Диске
Вывод: Ознакомившись с данные на первый взгляд с ними все хорошо только названия столбцов нужно привести к единому змеиному регистру, переименовывать не нужно так как названия столбцов соответствуют содержимому.
Типы данных также соответствуют.
3

2.Провели предварительную обработку данных.
Устранили небольшую проблему с регистром названий столбцов приведением их к нижнему регистру в соответствии с рисунком 2.
Рисунок 2 – Устранение проблем названий столбцов Проверили данные на наличие пропусков значений в столбцах в соответствии с
рисунком 3.
Рисунок 3 – Проверка дата сета на наличие пропусков значений
Вывод: Пропусков в дата сете не оказалось, исправлять ничего не нужно – это упрощает нам работу.
4

Проверили данные на наличие явных дубликатов в соответствии с рисунком 4.
Рисунок 4 – Проверка дата сета на наличие явных дубликатов
Вывод: Дубликаты в выборке не обнаружены.
Проверили данные на наличие ошибочных значений в столбцах, которые противоречат логике содержимого столбца в соответствии с рисунками 5-6
Рисунок 5 – Проверка ошибочных значений
5
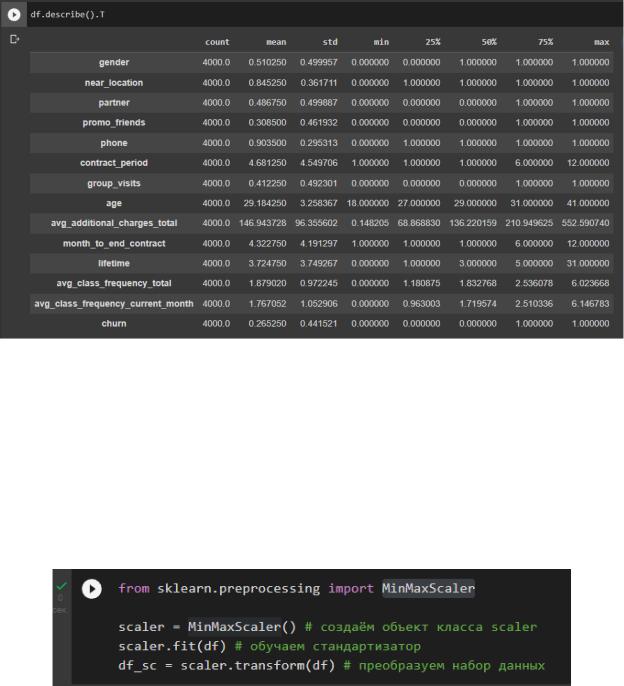
Рисунок 6 – Проверка ошибочных значений
Вывод: Проверив данные в столбцах на наличие ошибочных значений, не нашли их.
Все значения количественных значений в допустимых пределах, а категориальные данные не содержат ошибочных значений.
Масштабирование данных будем производить с помощью класса MinMaxScaler() из модуля preprocessing библиотеки для машинного обучения sklearn, в результате мы получим значения параметров в диапозоне от 0 до 1. Провели нормализацию данных в соответствии с рисунком 7.
Рисунок 7 – Нормализация данных
6

3.Выявили целевой признак (отклик).
Целевым признаком для нашего набора данных является поле churn – Факт ухода из клуба. Поскольку основная задача бизнеса — это удержать постоянных клиентов, а для этого нужно понимать и прогнозировать, когда? и, почему? клиент может уйти чтобы предпринять какие-то действия по его удержанию.
Отделили целевой признак от основной выборки, это необходимо для проведения корректного обучения в соответствии с рисунком 8.
Рисунок 8 – Выделение целевого признака
4.Разбили набор данных на тренировочной и тестовый датасеты с помощью
train_test_split.
Размер тренировочной выборки 2500 записей что составляет 62,5% от общего количества записей 4000, и 1500 тестовая выборка.
Что результат разделения повторялся от запуска к запуску установили значение параметра random_state. Код и результат разделения в соответствии с рисунком 9.
Рисунок 9 – Разбиение дата сета на обучающий и тестовый
7

5.Разработали предсказательные модели качественного отклика методами:
5.1.Метод k- ближайших соседей
Суть метода в отнесении объекта к какому-то классу на основании расстояния от него до центров кластеров, определённых моделью в процессе обучения.
Для классификации методом К-ближайших соседей воспользовались моделью,
предоставляемой модулем KNeighborsClassifier из библиотеки Scikit-learn.
Обучение проводили на специально подготовленных данных X_train (объект-
признаков) и y_train (вектор целевой переменной) в соответствии с рисунком 10.
Задали параметр n_neighbors = 5, который обозначает количество кластеров алгоритма K-ближайших соседей. Занчение было получено в прошлой лабораторной работе при кластеризации агломеративно иерархическим методом.
Рисунок 10 – Обучение модели классификатора методом К-ближайших соседей Сделали предсказание для тестовой части данных (X_test) в соответствии с
рисунком 11.
Рисунок 11 – Предсказание модели классификации К-ближайших соседей
8

5.2.Логистическая регрессия
Суть метода в отнесении объекта к какому-то классу на основании его положения относительно плоскости, которая разбивает пространство объектов на кластеры (в нашем случае на два кластера). Положение плоскости в пространстве объектов определяется моделью в ходе обучения.
Для классификации методом Логической регрессии воспользовались моделью,
предоставляемой модулем LogisticRegression из библиотеки Scikit-learn.
Обучение проводили на специально подготовленных данных X_train (объект-
признаков) и y_train (вектор целевой переменной) в соответствии с рисунком 12.
Рисунок 12 – Обучение модели классификатора методом Логической регрессии Сделали предсказание для тестовой части данных (X_test) в соответствии с
рисунком 13.
Рисунок 13 – Предсказание модели классификации Логической регрессии
9

5.3.Случайный лес
Суть метода состоит в использовании нескольких решающих деревьев. Само по себе решающее дерево предоставляет крайне невысокое качество классификации, но из-за большого их количества результат значительно улучшается.
Для классификации методом Случайный лес воспользовались моделью,
предоставляемой модулем RandomForestClassifier из библиотеки Scikit-learn.
Обучение проводили на специально подготовленных данных X_train (объект-
признаков) и y_train (вектор целевой переменной) в соответствии с рисунком 14.
Рисунок 14 – Обучение модели классификатора методом Случайный лес Сделали предсказание для тестовой части данных (X_test) в соответствии с
рисунком 15.
Рисунок 15 – Предсказание модели классификации Случайный лес
10