

ГУАП
КАФЕДРА №41
ОТЧЕТ ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
ассистент |
|
|
|
В.В. Боженко |
|
|
|
|
|
|
|
|
|
|
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ №3
КЛАСТЕРИЗАЦИЯ ДАННЫХ
по курсу: Введение в анализ данных
РАБОТУ ВЫПОЛНИЛ
СТУДЕНТ ГР. №
подпись, дата |
|
инициалы, фамилия |
Санкт-Петербург 2022
Цель работы
Изучение алгоритмы и методы кластерного анализа на практике.
Индивидуальный вариант
Индивидуальный вариант номер 10 в соответствии с таблицей 1.
Таблица 1 – Индивидуальный вариант задания
Название |
|
Пояснение |
датафрейма |
|
|
|
|
|
5gym_churn.csv |
Информация о клиентах фитнес клуба: |
|
|
1. |
Пол |
|
2. |
Близкое расположение |
|
3. |
Сотрудник компании партнера |
|
4. |
По промо друзей |
|
5. |
Указан ли телефон |
|
6. |
Длительность текущего абонемента |
|
7. |
Посещение групповых занятий |
|
8. |
Возраст |
|
9. |
Средние траты на доп услуги |
|
10. |
Количество месяцев до окончания абонемента |
|
11. |
Время с момента первого обращения в фитнес-центр (в месяцах) |
|
12. |
Средняя частота посещений в неделю за все время с начала |
|
|
действия абонемента |
|
13. |
Средняя частота посещений в неделю за предыдущий месяц |
|
14. |
Churn – факт ухода из клуба |
2

Ход работы
1. Получили у преподавателя набор данных 5gym_churn.csv в соответствии с индивидуальным вариантом №10 для проведения анализа согласно цели выполняемой работы.
Загрузили датасет с помощью библиотеки pandas в Jupyter-ноутбуке в соответствии с рисунком 1.
Рисунок 1 – Загрузка датаcета в Colab из файла 5gym_churn.csv на Google Диске
Вывод: Ознакомившись с данные на первый взгляд с ними все хорошо только названия столбцов нужно привести к единому змеиному регистру, переименовывать не нужно так как названия столбцов соответствуют содержимому.
Типы данных также соответствуют.
3

2.Провели предварительную обработку данных.
Устранили небольшую проблему с регистром названий столбцов приведением их к нижнему регистру в соответствии с рисунком 2.
Рисунок 2 – Устранение проблем названий столбцов Проверили данные на наличие пропусков значений в столбцах в соответствии с
рисунком 3.
Рисунок 3 – Проверка дата сета на наличие пропусков значений
Вывод: Пропусков в дата сете не оказалось, исправлять ничего не нужно – это упрощает нам работу.
4

Проверили данные на наличие явных дубликатов в соответствии с рисунком 4.
Рисунок 4 – Проверка дата сета на наличие явных дубликатов
Вывод: Дубликаты в выборке не обнаружены.
Проверили данные на наличие ошибочных значений в столбцах, которые противоречат логике содержимого столбца в соответствии с рисунками 5-6
Рисунок 5 – Проверка ошибочных значений
5

Рисунок 6 – Проверка ошибочных значений
Вывод: Проверив данные в столбцах на наличие ошибочных значений, не нашли их.
Все значения количественных значений в допустимых пределах, а категориальные данные не содержат ошибочных значений.
6
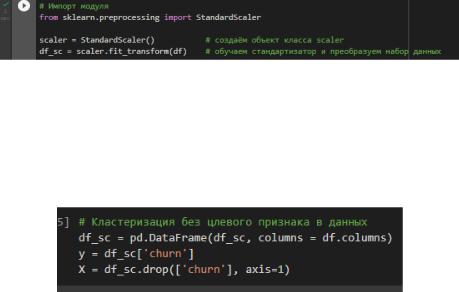
3.Выполнили кластеризацию объектов
Чтобы перейти к кластеризации данных сначала необходимо их нормализовать или стандартизировать. Выберем метод стандартизации, потому что это наиболее часто используемы метод. Масштабирование данных будем производить с помощью класса
StandardScaler() из модуля preprocessing библиотеки для машинного обучения sklearn в
соответствии с рисунком 7.
Рисунок 7 – Стандартизация данных По стандартизированным данным мы можем проводить дальнейшую
кластеризацию.
Удалили целевой признак чтобы он не влиял на кластеризацию в соответствии с рисунком 7.1.
Рисунок 8.1 – Удаление целевого признака
7

3.1.Иерархическим агломеративным методом
Для кластеризации данных использовали алгоритм «ward» он позволяет на основе расстояний между точками сформировать кластеры регулярного размера.
Воспользовавшись модулями linkage() и dendrogram() библиотеки sklearn построили таблицу связок между объектами и построили дендрограмму в соответствии с рисунком 8.
Рисунок 9 – Кластеризация и построение дендрограммы кластеров Из дендрограммы явно видно, что оптимальное количеством кластеров для нашего
датесета 4.
8

Разделим данные на 4 кластеров с применением метода KMeans и метрики высчитанной для агломеративной иерархической кластеризации в соответствии с рисунком 9.
Рисунок 10 – Разделение данных на 5 кластеров Произвели оценку средних значений признаков кластера в соответствии с
рисунком 10.
Рисунок 11 – Средние значения признаков кластеров Определили три признака (характеристики), оказавших наибольшее влияние на
выделение кластеров используя оценку средних значений признаков на основе визуального анализа построенного графика:
•contract_period – Длительность текущего абонемента
•avg_additional_charges_total – Средние траты на доп
•churn – Факт ухода из клуба
Данные признаки были выбраны, потому что они сильнее всего отличаются для разных кластеров.
9

3.2.Методом k-средних.
Задали случайным образом число кластеров равное 4 и произвели кластеризацию в соответствии с рисунком 11.
Рисунок 12 – Разбиение датасета на кластеры методом K-средних
Рассчитали евклидово расстояние между кластерами и отобразили их на тепловой карте в соответствии с рисунком 12.
Рисунок 13 – Тепловая карта расстояний между кластерами Определили три признака (характеристики), оказавших наибольшее влияние на
выделение кластеров используя оценку средних значений признаков на основе визуального анализа построенного графика:
Рисунок 14 – Средние значения признаков кластеров Аналогично тому, как мы определяли три признака наиболее повлиявших на
разбиение кластеров в прошлый раз определили параметры, которые наиболее различны для кластеров, ими оказались следующие: contract_period – Длительность текущего абонемента; month_to_end_contract – Количество месяцев до окончания абонемента; churn – Факт ухода из клуба.
Определили объекты, относящиеся к каждому кластеру
10