

ГУАП
КАФЕДРА №41
ОТЧЕТ ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
ассистент |
|
|
|
В.В. Боженко |
|
|
|
|
|
|
|
|
|
|
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ №2
АНАЛИЗ СВЯЗЕЙ МЕЖДУ ПРИЗНАКАМИ ДВУМЕРНОГО НАБОРА ДАННЫХ
по курсу: Введение в анализ данных
РАБОТУ ВЫПОЛНИЛ |
|
|
|
|
|
|
СТУДЕНТ ГР. № |
4918 |
|
|
|
Е.С. Плеханов |
|
|
|
|
|
|
|
|
|
|
|
|
подпись, дата |
|
инициалы, фамилия |
Санкт-Петербург 2022
Цель работы
Изучение связи между признаками двумерного набора данных.
Индивидуальный вариант
Индивидуальный вариант номер 10 в соответствии с таблицей 1.
Таблица 1 – Индивидуальный вариант задания
Название |
|
Пояснение |
датафрейма |
|
|
|
|
|
8и10credit.csv |
Информация о заемщиках: |
|
|
1. |
Количество детей в семье |
|
2. |
Общий трудовой стаж в днях |
|
3. |
Возраст клиента в годах |
|
4. |
Уровень образования клиента |
|
5. |
Идентификатор уровня образования |
|
6. |
Семейное положение |
|
7. |
Идентификатор семейного положения |
|
8. |
Пол клиента |
|
9. |
Тип занятости |
|
10. |
Имел ли задолженность по возврату кредитов |
|
11. |
Ежемесячный доход |
|
12. |
Цель получения кредита |
2

Ход работы
1)Получили у преподавателя набор данных 8и10credit.csv в соответствии с индивидуальным вариантом №10 для проведения анализа согласно цели выполняемой работы.
2)Загрузить датасет с помощью библиотеки pandas в Jupyter-ноутбуке в соответствии с рисунком 1.
Рисунок 1 – Загрузка датаcета в Colab из файла 8и10credit.csv на Google Диске
Вывод: Изучив данные выявили следующие проблемы с колонками данных:
•Колонка daysEmployed содержит нужно переименовать в змеином регистре; формат данных должен быть целочисленным, потому что столбец хранит кол-во дней, что передусматривает целое число и дробная часть не имеет особого значения в нащем случае; числа не должны быть оттрицательными так как значение должно отражать сколько человек отработал дней; значений привышающих возраст человека быть не может.
•Столбец dob_years необходимо переименовть в full_years чтобы конкретизировать содержащуюся в нем информацию.
•Столбец children переименуем в children_count так как это количественный а не
3

бинарный признак
•Столбец education переименуем в education_level с тойже целью что и столбец
dob_years; регистр данных различен, из-за этого произойдет замножения однотипных категорий по данному признаку
• Столбец total_income можно привести к целому числу что бы отбросить не значащие копецки.
3)Провели предварительную обработку данных.
Выявили и устранили проблемы с названиями столбцов таблицы в соответствии с рисунком 2.
Рисунок 2 – Устранение проблем названий столбцов
4

Выяснили что категориальные значения в столбцах отличаются регистром написания что увеличивает кол-во категорий. Исправили эту проблему приведением значений столбцов к регистру одного вида в соответствии с рисунком 3.
Рисунок 3 – Устранение проблем регистра
Обработали пропуски в строках.
Выяснили в каких столбцах присутствуют пропуски и изучили остальные данные в них в соответствии с рисунком 4.
Рисунок 4 – Выявление проблем пропусков
5
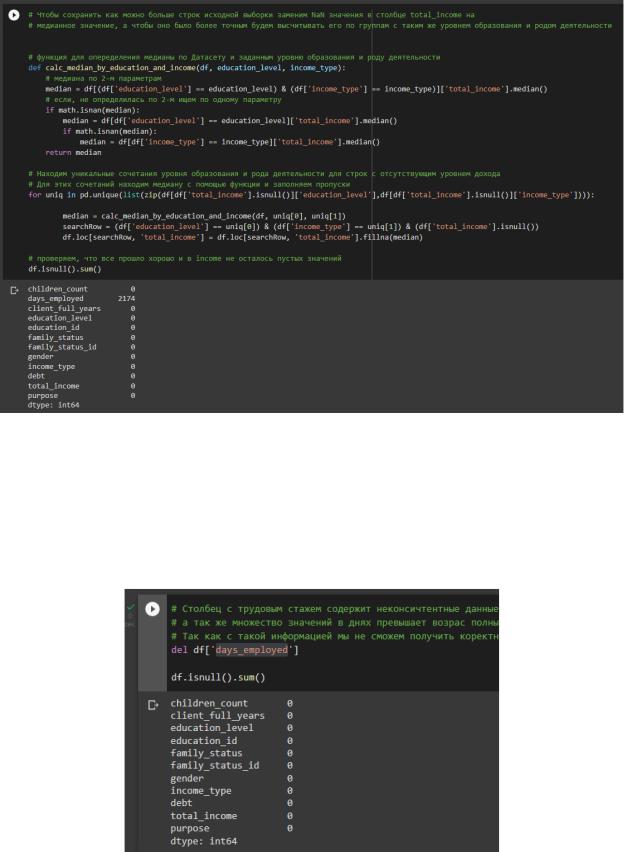
Устранили пропуски столбца «total_income» (ежемесячный доход) заполнив их медианным значениям для клиентов с таким же уровнем образования и родом деятельности в соответствии с рисунком 5.
Рисунок 5 – Устранили пропуски в столбце «total_income»
Столбец «days_employed», который должен содержать трудовой стаж, так же имеет проблему пропусков, но эта не самая большая проблема этих данных. Данный столбик
содержит отрицательные значения и значения, которые при переводе из дней в года превышают значения полных лет для клиента, поэтому этот столбик в анализе нам использовать не получится, его мы удалим в соответствии с рисунком 6.
Рисунок 6 – Удаление столбика «days_employed»
6

Вывод:
•Пропущенные значения дохода мы заменили на медианное значение для категории, в которую попадает человек. Это позволит получить более точную информацию
иснизить возможную статистическую погрешность;
•Столбец days_employed мы удалили т.к. он содержит слищко много противоречащий информации;
•Пропуски скорее всего появились из-за того, что нет подтвержденной информации о клиенте или данные были поврежденны из-за ошибки при выгрузке.
Привели тип данных столбца «total_income» к целому числу чтобы отбросить дробную часть числа, которая погоды нам не сделает, а найти дубликаты может помешать в соответствии с рисунком 7.
Рисунок 7 – Приведение типа данных столбца «» к целому числу
Вывод: Точность дохода до копеек для нас не имеет смысла, к тому же дробная часть превышала два знака после запятой, а также целые значения позволят проще категорировать группы людей.
7

Выявили и удалили явные дубликаты в таблице в соответствии с рисунком 8.
Рисунок 8 – Удаление явных дубликатов
Обработка других ошибок данных.
Вывод: Дубликатов оказалось не так много, их мы просто удалили. Возможно, в базу попало по две-три заявки от одних и тех же клиентов, чтобы такого не происходило необходимо делать проверки при сборе данных.
Выявили проблемы с данными выведя уникальные значения для столбцов дата фрейма в соответствии с рисунком 9.
Рисунок 9 – Выявление проблем с данными
8

Дополнительно изучив данные в соответствии с рисунком 10, выявили следующие проблемы:
children_count содержит значение 20 и -1, хотя отрицательного числа быть не может,
а 20 сильно выделяется на фоне остальной выборки; full_years содержит нулевой возраст;
gender содержит пол XNA;
purpose содержит опечатку - ремонт жильЮ.
Рисунок 10 – Выявление проблем с данными Про возможные причины и решения:
1.Значение 20 в количестве детей скорее всего опечатка, при наборе 2, случайно задели ноль;
2.Значение -1 могло означать раннее отсутствие детей либо их наличие, но почему-
то выгруженное, как отрицательное число. Т.к. по df[df['children_count'] == -
1]['family_status'].value_counts() можно убедиться, что большая часть этих людей находится или находилась в браке, предположим что у них 1 ребенок;
3.Нулевой возраст быть не может, скорее всего он нам просто неизвестен. Т.к. в
нашем случае значение возраста не так уж критично, оставим эти значения без изменений;
4.Поскольку пол XNA только один, а в наших данных большинство женщины -
заменим значением по умолчанию - F.
9

Устранили проблемы данных в соответствии с рисунком 11.
Рисунок 11 – Устранили проблемы данных
Вывод: В данных встречаются артефакты, тем кто делал сбор данных стоит позаботиться о более тщательной проверке данных перед их загрузкой в БД. Однако их количество вряд ли отразится на статических результатах исследования.
10