

Цель работы
Изучить применение основных методов статистики для проверки
статистических гипотез.
Выполнение работы
1)Сгенерировали две выборки нормального распределения, где МО
=мой номер по списку (11), а дисперсия = корень из моего номера по списку
(sqrt(11)). При помощи t-критерия сделали выводы о статистическом различии.
Код в соответствии с листингом 1 и результат теста в соответствии с
рисунком 1.
Листинг 1 – Код пункта 1
# №1
n <- 1000 mo <- 11
disp <- sqrt(mo)
sample1 <- rnorm(n, mean = mo, sd = disp) sample2 <- rnorm(n, mean = mo, sd = disp)
t.test(sample1, sample2)
Рисунок 1 – Результат пункта 1
Исходя из полученного p-value = 0.6475, делаем выводы что различия
средних значений выборок статически не значимы, а истинная разница между
средними значениями с вероятностью 95% лежит между в диапазоне от -
0.3564933 до 0.2216646.

2) Используя встроенный датафрейм с характеристиками цветов ириса (iris), с помощью Шапиро-Уилка теста сделали вывод о нормальности распределения характеристик. Уровень значимости 0.05. Код в соответствии с листингом 2 и результат теста в соответствии с рисунком 2.
Листинг 2 – Код пункта 2
# №2 data(iris)
lapply(iris[, 1:4], function(x) {shapiro.test(x)})
Рисунок 2 – Результат пункта 2
Анализируя полученные данные, принимая во внимание уровень значимости в 0.05 отвергаем нулевую гипотезу для всех параметров, кроме iris$Sepal.Width, так как значение p-value в его случае превышает установленный уровень значимости.
2

3) Для k = 10, 15, 20, 25, 30 сгенерировали N=200 нормально распределенные случайные величины с мат. ожиданием, равным k, и
стандартным отклонением, равным √ k, и N=200 случайные величины,
распределенные по закону 2 с k степенями свободы. Используя тест Колмогорова-Смирнова, проверили гипотезу о том, что данные выборки относятся к одному непрерывному распределению. Уровень значимости 0.05.
Код в соответствии с листингом 3 и результат теста в соответствии с рисунками 3.
Листинг 3 – Код пункта 3
# №3
k <- c(10, 15, 20, 25, 30) N <- 200
lapply( k, function(x) {ks.test(rnorm(N, x, sqrt(x)), rchisq(N, x))})
Рисунок 3 – Результат пункта 3
3

4) Используя критерий χ2 проверили гипотезу, состоящую в том, что цвет глаз женщин не зависит от цвета волос (на фрейме данных HairEyeColor).
Код в соответствии с листингом 4 и результат теста в соответствии с рисунком 4.
Листинг 4 – Код пункта 4
# №4 data("HairEyeColor")
lapply(dimnames(HairEyeColor)$Eye, function(x) {chisq.test(HairEyeColor[, x, "Female"])})
Рисунок 4 – Результат пункта 4
Полученные результаты свидетельствуют о том, что цвет глаз зависит от
цвета волос так как все полученные значения p-value меньше 0.05.
4
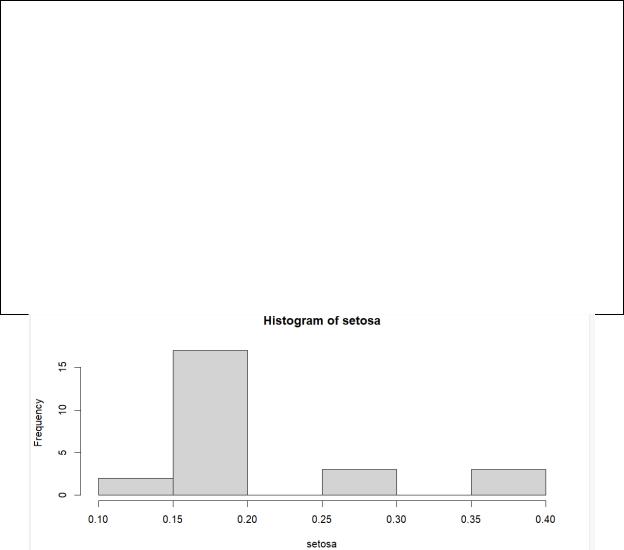
5) Используя встроенный датафрейм с характеристиками цветов ириса(iris), оставили только один количественный столбец и факторный столбец (оставили только 2 уникальных фактора, третий удалили), для разделения по группам.
•Построили гистограммы распределения оставленного столбца для каждого уникального значения факторной переменной;
•Проверить каждую группу на нормальность (shapiro.test);
•Проверьте эти группы на гомогенность дисперсий (bartlett.test);
•Проведите t-test для этих групп.
Код в соответствии с листингом 4 и результат в соответствии с
рисунком 5.
Листинг 5 – Код пункта 5
# №5
df <- subset(iris[, 4:5], Species == c("setosa", "versicolor"))
# гистограммы по каждому 2 факторов
hist(df$Petal.Width[df$Species == "setosa"], main = "Histogram of setosa",xlab = "setosa") hist(df$Petal.Width[df$Species == "versicolor"], main = "Histogram of versicolor",xlab = "versicolor")
# тест на нормальность shapiro shapiro.test(df$Petal.Width[df$Species == "setosa"]) shapiro.test(df$Petal.Width[df$Species == "versicolor"])
#Тест на гомогенность дисперсий bartlett.test(df$Petal.Width, df$Species)
#t-test
t.test(df$Petal.Width[df$Species == "setosa"], df$Petal.Width[df$Species == "versicolor"])
Рисунок 5 – График распределения для «setosa» пункта 4
5

Рисунок 6 – График распределения для «versicolor» пункта 4
Рисунок 7 – Результат пункта 5
По результатам тестов делаем выводы:
-тест Шапиро-Уилка нулевая гипотеза отвергается для обеих групп;
-тест Барлетта говорит о том, что дисперсии выборок различны;
-тест t-test показал, что выборки имеют значительные статические различия.
Код программы целиком представлен в Приложении А.
6
Вывод
Выполнив в данную лабораторную работу, мы изучили и получили практические навыки в работе с основными методами статистики для проверки статистических гипотез. В том числе работа с тестами t-test, Шапиро-
Уилка, Барлетта и Колмогорова-Смирнова. С их помощью мы проверили статические различия для двух выборок нормального распределения с заданными параметрами; сделали вывод о нормальности распределения характеристик при заданном уровне нормальности; проверили гипотезу о принадлежности двух выборк к одному непрерывному распределению с заданным уровнем значимости; проверили гипотезу о зависимости цвет глаз женщин от цвета волос; проверили 2 группы на нормальность, на гомогенность дисперсий и t-test.
7
Приложение А. Листинг программы
# №1
n <- 1000 mo <- 11
disp <- sqrt(mo)
sample1 <- rnorm(n, mean = mo, sd = disp) sample2 <- rnorm(n, mean = mo, sd = disp)
t.test(sample1, sample2)
#№2
data(iris)
lapply(iris[, 1:4], function(x) {shapiro.test(x)})
#№3
k <- c(10, 15, 20, 25, 30) N <- 200
lapply( k, function(x) {ks.test(rnorm(N, x, sqrt(x)), rchisq(N, x))})
#№4
data("HairEyeColor")
lapply(dimnames(HairEyeColor)$Eye, function(x) {chisq.test(HairEyeColor[, x, "Female"])})
#№5
df <- subset(iris[, 4:5], Species == c("setosa", "versicolor"))
# гистограммы по каждому 2 факторов
hist(df$Petal.Width[df$Species == "setosa"], main = "Histogram of setosa",xlab = "setosa")
hist(df$Petal.Width[df$Species == "versicolor"], main = "Histogram of versicolor",xlab = "versicolor")
# тест на нормальность shapiro shapiro.test(df$Petal.Width[df$Species == "setosa"]) shapiro.test(df$Petal.Width[df$Species == "versicolor"])
# Тест на гомогенность дисперсий
8
bartlett.test(df$Petal.Width, df$Species)
# t-test
t.test(df$Petal.Width[df$Species == "setosa"], df$Petal.Width[df$Species == "versicolor"])
9