

ГУАП
КАФЕДРА № 41
ОТЧЕТ ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
доцент |
|
|
|
М.Н. Шелест |
|
|
|
|
|
|
|
|
|
|
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ №2
СПЕЦИАЛИЗИРОВАНЫЕ ФУНКЦИИ ДЛЯ РАБОТЫ С ДАТАФРЕЙМАМИ И БАЗОВАЯ ГРАФИКА
по курсу: СТАТИЧЕСКАЯ ОБРАБОТКА ИНФОРМАЦИИ
РАБОТУ ВЫПОЛНИЛ |
|
|
|
|
|
СТУДЕНТ ГР. № |
29.09.2021 |
|
|
||
|
|
|
|
|
|
|
|
|
подпись, дата |
|
инициалы, фамилия |
Санкт-Петербург 2021

Цель работы
Изучить применение основных функций для работы с датафреймами и базовой встроенной графики в R.
Выполнение работы
1) С помощью встроенной функции runif() сгенерировал 2 вектора вещественных чисел в промежутке [a;b] и с помощью функции sample()
сгенерировал 2 вектора целых чисел в промежутке [c;d] и один вектор в промежутке [0,k]. Объединил 2 вектора вещественных чисел и вектор положительных чисел в датафрейм – df1, а 2 вектора целых чисел в другой датафрейм – df2 (параметры a=-10, b=50, c=-30 и d=30, k=50, a, c < 0, b, d, k > 10) в соответствии с рисунком 1.
Рисунок 1 – Результат выполнения пункта 1
2) Для каждого из датафреймов при помощи функции apply() нашел максимальное значение в каждой строке. Сохранил результат в переменную p_max в соответствии с рисунком 2.
Рисунок 2 – Результат выполнения пункта 2
2

3) Написал функцию colunm_sum, которая получает на вход каждый из датафреймов и находит сумму положительных значений в каждой переменной. Сохраните результат в список в соответствии с рисунком 3.
Рисунок 3 – Результат выполнения пункта 3
4) Объединил два исходных датафрейма в один построчно встроенной функцией сbind, назовите его my_df в соответствии с рисунком 4.
Рисунок 4 – Результат выполнения пункта 4
5)Написал функцию negative_values, которая получает на вход
my_df. Функция для каждой переменной в данных проверяет, есть ли в ней отрицательные значения. Если в переменной отрицательных значений нет, то эта переменная не выводится, для всех переменных, в которых есть отрицательные значения выводятся эти значения отдельным списком по каждой переменной в соответствии с рисунком 5.
Рисунок 5 – Результат выполнения пункта 5
3

6) Случайным образом добавил NA значения в свой датафрейм в соответствии с рисунком 6.
Рисунок 6 – Результат выполнения пункта 6
7) Написал функцию na_values которая заменяет все пропущенные значения в столбцах my_df на соответствующее среднее значение. То есть все
NA в первом столбце заменяются на среднее значение первого столбца
(рассчитанного без учета NA). Все NA второго столбца заменяются на среднее значение второго столбца и т.д. для проверки является ли наблюдение NA
нужно использовал функцию is.na() в соответствии с рисунком 7.
Рисунок 7 – Результат выполнения пункта 7
4

8) Создал случайную последовательность данных x размером 50 (с
помощью функции seq()). Используя функцию sapply() и lapply() относительно каждого значения x нашел y из уравнения = 2 + 3 − 19 в соответствии с рисунком 8.
Рисунок 8 – Результат выполнения пункта 8
9)Выбрал встроенный датафрейм из R и сохранил его в переменную
my_df2 в соответствии с рисунком 9.
Рисунок 9 – Результат выполнения пункта 9
5

10) Используя функции из пакета dplyr, в переменную A сохранил все нечетные строчки из my_df2, а в переменную B все четные строчки. После этого склеил два полученных датафрейма в один по столбцам используя встроенную функцию rbind в соответствии с рисунком 10.
Рисунок 10 – Результат выполнения пункта 10
11) Из исходного датафрейма my_df2 отобрал только четыре количественные переменные. Оставил только те наблюдения, для которых значения первой переменной больше, чем среднее значение в этом столбце, а
значение второй переменной меньше среднего значения в этом столбце.
Отсортировал получившиеся данные по убыванию первой переменной и вывел только первые 10 строчек в соответствии с рисунком 11.
Рисунок 11 – Результат выполнения пункта 11
6
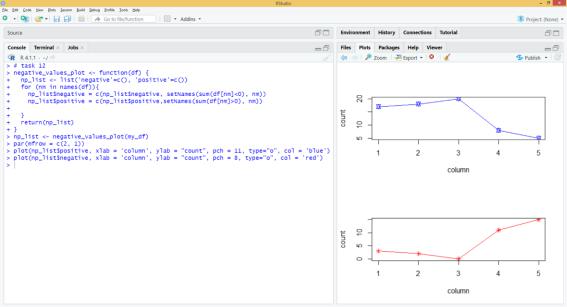
12) Модифицировал функцию negative_values, путем создания новой функции negative_values_plot, таким образом, чтобы на выходе функции получались два списка с количеством отрицательных элементов по каждому столбцу и с количеством положительных элементов по каждому столбцу.
Затем по этим данным построил точечный график количества положительных и отрицательных элементов по количеству столбцов в датафрейме. Для построения использовал plot(). Изменил стандартный значок отображения точки на графике на звездочку. Получившиеся графики отличаться друг от друга цветом соединительных линий. Добавил подписи осей в соответствии с рисунком 12.
Рисунок 12 –– Результат выполнения пункта 12
7

13) Сгенерировал случайное нормальное распределенние величины с помощью функции rnorm(). Отобразил эти случайные величины на гистограмме, используя функцию hist(). Гистограмму сделал цветной. На этом же графике отобразил кривую плотности вероятности. Оценку плотности вероятности сделал с помощью функции density(). Добавил подписи осей и общее название для графика в соответствии с рисунком 13.
Рисунок 13 – Результат выполнения пункта 13
8
Вывод
Выполнив лабораторную работу, мы изучили особенности генерации случайных последовательностей с использование встроенных функций runif(), sample() и seq(), научились создавать датафреймы из векторов значений,
применять функции к массивам с помощью функции apply(), писать свои функции обработки данных, объединять датафреймы с помощью функций cbind и rbind, представлять данные на графике используя встроенную графику языка R.
9