

парал прогр / 2020_2021_311_paral_Pelipets_Work15
.docxМИНОБРНАУКИ РОССИИ
Федеральное государственное бюджетное образовательное учреждение
высшего образования
«САРАТОВСКИЙ НАЦИОНАЛЬНЫЙ ИССЛЕДОВАТЕЛЬСКИЙ
ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
ИМЕНИ Н. Г. ЧЕРНЫШЕВСКОГО»
ОТЧЕТ
ПО ЗАДАНИЮ «ПАРАЛЛЕЛЬНЫЙ МЕТОД ЗЕЙДЕЛЯ С ПОМОЩЬЮ MPI»
студента 3 курса 311 группы
направления 02.03.02 — Фундаментальная информатика и информационные
технологии
факультета КНиИТ
Пелипца Владислава Сергеевича
Проверил
старший преподаватель ____________ М. С. Портенко
Саратов 2021
Свойства процессора:
Постановка задачи:
Выполните разработку параллельного варианта для метода Зейделя.
Для тестовой матрицы из нулей и единиц проведите вычислительные эксперименты, результаты занесите в таблицу 1.
Таблица 1. Время выполнения последовательного и параллельного итерационного алгоритмов решения систем линейных уравнений и ускорение
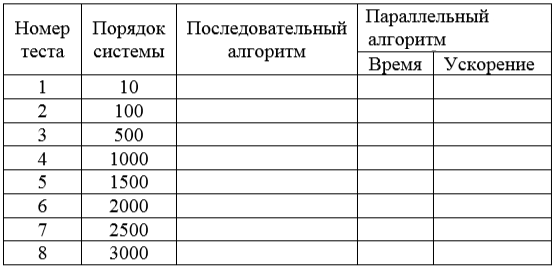
Какой из алгоритмов Гаусса или итерационный обладает лучшими показателями ускорения? Заполните таблицу 2.
Таблица 2. Ускорение параллельных алгоритмов Гаусса и итерационного (вариант) решения систем линейных уравнений
Программная реализация проекта:
#include <stdio.h>
#include <stdlib.h>
#include <conio.h>
#include <time.h>
#include <math.h>
#include "mpi.h"
int ProcNum;
int ProcRank;
int* pProcInd;
int* pProcNum;
double* xk;
double* xk_1;
// Function for random initialization of the matrix and the vector elements
void RandomDataInitialization(double* pMatrix, double* pVector, int Size) {
int i, j;
srand(unsigned(clock()));
for (i = 0; i < Size; i++) {
pVector[i] = rand() / double(1000);
for (j = 0; j < Size; j++) {
if (j <= i)
pMatrix[i * Size + j] = rand() / double(1000);
else
pMatrix[i * Size + j] = 0;
}
}
}
// Function for memory allocation and definition of the objects elements
void ProcessInitialization(double*& pMatrix, double*& pVector, double*& pResult, double*& pProcRows, double*& pProcVector, double*& pProcResult, int& Size, int& RowNum) {
if (ProcRank == 0) {
// Setting the size of the matrix and the vector
do {
printf("\nEnter size of the matrix and the vector: ");
scanf_s("%d", &Size);
printf("\nChosen size = %d \n", Size);
if (Size <= 0)
printf("\nSize of objects must be greater than 0!\n");
} while (Size <= 0);
}
MPI_Bcast(&Size, 1, MPI_INT, 0, MPI_COMM_WORLD);
pProcRows = new double[Size * Size];
pProcVector = new double[Size];
pProcResult = new double[Size];
pProcInd = new int[Size];
pProcNum = new int[Size];
// Memory allocation
if (ProcRank == 0) {
pMatrix = new double[Size * Size];
pVector = new double[Size];
pResult = new double[Size];
xk = new double[Size];
xk_1 = new double[Size];
// Initialization of the matrix and the vector elements
RandomDataInitialization(pMatrix, pVector, Size);
}
}
// Function for data distribution
void DataDistribution(double* pMatrix, double* pProcRows, double* pVector, double* pProcVector, int Size, int RowNum) {
int* pSendNum;
int* pSendInd;
int i;
pSendInd = new int[ProcNum];
pSendNum = new int[ProcNum];
RowNum = Size;
pSendNum[0] = RowNum * Size;
pSendInd[0] = 0;
for (i = 1; i < ProcNum; i++) {
pSendNum[i] = RowNum * Size;
pSendInd[i] = 0;
}
MPI_Scatterv(pMatrix, pSendNum, pSendInd, MPI_DOUBLE, pProcRows, RowNum * Size, MPI_DOUBLE, 0, MPI_COMM_WORLD);
pProcInd[0] = 0;
pProcNum[0] = Size;
for (i = 1; i < ProcNum; i++) {
pProcInd[i] = 0;
pProcNum[i] = Size;
}
MPI_Scatterv(pVector, pProcNum, pProcInd, MPI_DOUBLE, pProcVector, pProcNum[ProcRank], MPI_DOUBLE, 0, MPI_COMM_WORLD);
delete[] pSendNum;
delete[] pSendInd;
}
// Function for formatted vector output
void PrintVector(double* pVector, int Size) {
int i;
for (i = 0; i < Size; i++)
printf("%7.4f ", pVector[i]);
}
// Function for computational process termination
void ProcessTermination(double* pMatrix, double* pVector, double* pResult, double* pProcRows, double* pProcVector, double* pProcResult) {
if (ProcRank == 0) {
delete[] pMatrix;
delete[] pVector;
delete[] pResult;
}
delete[] pProcRows;
delete[] pProcVector;
delete[] pProcResult;
}
// Normal system
double Normal(double* x1, double* x2, int Size) {
double norm = fabs(x1[0] - x2[0]);
for (int i = 1; i < Size; i += 1) {
if (fabs(x1[i] - x2[i]) > norm) {
norm = fabs(x1[i] - x2[i]);
}
}
return norm;
}
// Function for the execution of Zeidel algorithm
void ZeidelCalculation(double* pMatrix, double* pVector, double* pResult, int Size) {
if (ProcRank == 0) {
for (int i = 0; i < Size; i++) {
xk[i] = 0.0;
xk_1[i] = 0.0;
}
}
double* xkProc = new double[Size];
double* xk_plus_1Proc = new double[Size];
pProcInd[0] = 0;
pProcNum[0] = Size;
for (int i = 1; i < ProcNum; i++) {
pProcInd[i] = 0;
pProcNum[i] = Size;
}
MPI_Scatterv(xk, pProcNum, pProcInd, MPI_DOUBLE, xkProc, pProcNum[ProcRank], MPI_DOUBLE, 0, MPI_COMM_WORLD);
MPI_Scatterv(xk_1, pProcNum, pProcInd, MPI_DOUBLE, xk_plus_1Proc, pProcNum[ProcRank], MPI_DOUBLE, 0, MPI_COMM_WORLD);
bool stop = false;
while (!stop) {
double sum1, sum2, s1, s2;
for (int i = 0; i < Size; i++) {
sum1 = 0.0;
for (int j = ProcRank; j <= i - 1; j += ProcNum) {
sum1 += xk_plus_1Proc[j] * pMatrix[i * Size + j];
}
MPI_Reduce(&sum1, &s1, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
sum2 = 0.0;
for (int j = ProcRank + i + 1; j < Size; j += ProcNum) {
sum2 += xkProc[j] * pMatrix[i * Size + j];
}
MPI_Reduce(&sum2, &s2, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (ProcRank == 0)
xk_1[i] = (pVector[i] - s1 - s2) / pMatrix[i * Size + i];
MPI_Scatterv(xk, pProcNum, pProcInd, MPI_DOUBLE, xkProc,
pProcNum[ProcRank], MPI_DOUBLE, 0, MPI_COMM_WORLD);
MPI_Scatterv(xk_1, pProcNum, pProcInd, MPI_DOUBLE, xk_plus_1Proc,
pProcNum[ProcRank], MPI_DOUBLE, 0, MPI_COMM_WORLD);
}
if (ProcRank == 0) {
if (Normal(xk, xk_1, Size) < 0.0001) {
stop = true;
}
else {
for (int i = 0; i < Size; i++) {
xk[i] = xk_1[i];
}
}
}
}
if (ProcRank == 0) {
for (int i = 0; i < Size; i++) {
pResult[i] = xk_1[i];
}
}
}
int main() {
double* pMatrix; // The matrix of the linear system
double* pVector; // The right parts of the linear system
double* pResult; // The result vector
double* pProcRows;
double* pProcVector;
double* pProcResult;
int Size; // The size of the matrix and the vectors
int RowNum;
double start, finish, duration;
setvbuf(stdout, NULL, _IONBF, 0);
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &ProcRank);
MPI_Comm_size(MPI_COMM_WORLD, &ProcNum);
if (ProcRank == 0) {
printf("Zeidel algorithm for solving linear systems\n");
}
// Data initialization
ProcessInitialization(pMatrix, pVector, pResult, pProcRows, pProcVector, pProcResult, Size, RowNum);
DataDistribution(pMatrix, pProcRows, pVector, pProcVector, Size, RowNum);
start = MPI_Wtime();
ZeidelCalculation(pProcRows, pProcVector, pResult, Size);
finish = MPI_Wtime();
duration = finish - start;
if (ProcRank == 0)
printf("\n Time of execution: %f\n", duration); // Printing the time spent by parallel Zeidel algorithm
ProcessTermination(pMatrix, pVector, pResult, pProcRows, pProcVector, pProcResult); // Program termination
MPI_Finalize();
}
Результат работы последовательного алгоритма:
Результат работы алгоритма с MPI распараллеливанием:
Время выполнения последовательного и параллельного алгоритмов Зейделя решения систем линейных уравнений и ускорение:
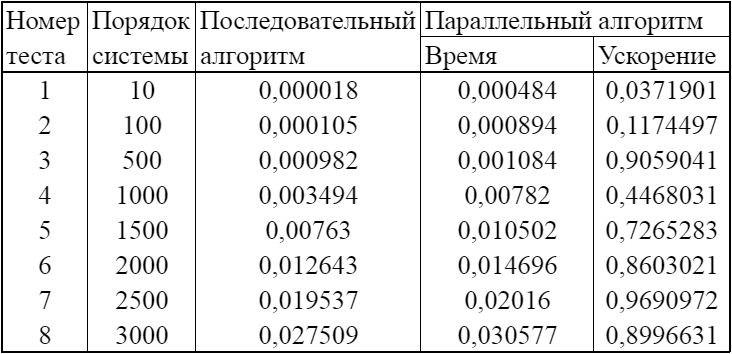 Вывод:
Вывод:
Параллельный алгоритм имеет смысл только на больших значениях.
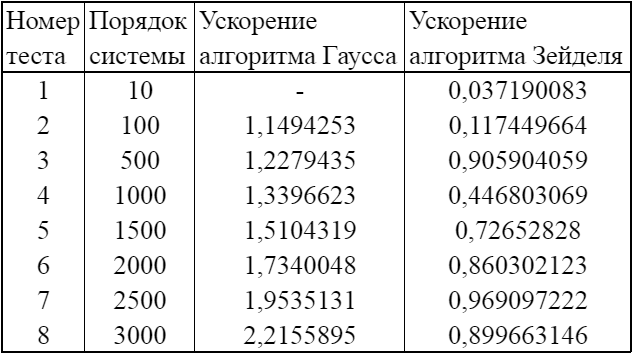 Вывод:
Вывод:
На выбранных значениях преимущество параллельного алгоритма над последовательным лучше всего наблюдается для алгоритма Гаусса.