

БД Батраева / Отчет 5 БД
.docxОтчет по заданию 5. Филатова Ольга 311
Запрос

Предполагаемая
стоимость поддерева без индекса
Время работы SQL Server без индекса
![]()
Некластеризованный составной индекс
![]()
Предполагаемая стоимость поддерева с индексом

Время работы SQL Server с Индексом
![]()
Запрос

Предполагаемая стоимость поддерева без индекса
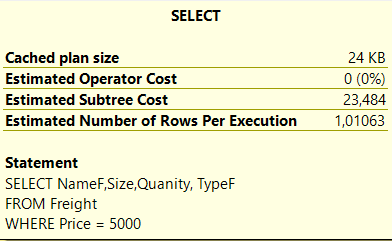
Время работы SQL Server без индекса
![]()
Некластеризованный покрывающий индекс

Предполагаемая стоимость поддерева с индексом
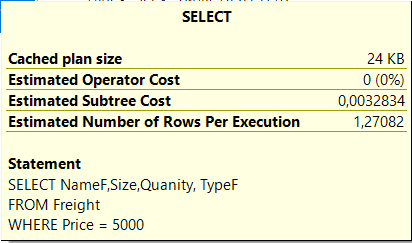
Время работы SQL Server с индексом
![]()
Запрос

Предполагаемая стоимость поддерева без индекса

Время работы SQL Server без индекса
![]()
Некластеризованный уникальный индекс
![]()
Предполагаемая стоимость поддерева с индексом

Время работы SQL Server с индексом
![]()
Запрос

Предполагаемая стоимость поддерева без индекса

Время работы SQL Server без индекса
![]()
Некластеризованный фильтрующий индекс

Предполагаемая стоимость поддерева с индексом
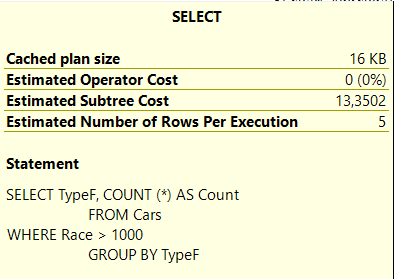
Время работы SQL Server с индексом
![]()
Запрос

Предполагаемая стоимость поддерева без индекса

Время работы SQL Server без индекса
![]()
Некластеризованный индекс с включенными столбцами

Предполагаемая стоимость поддерева с индексом
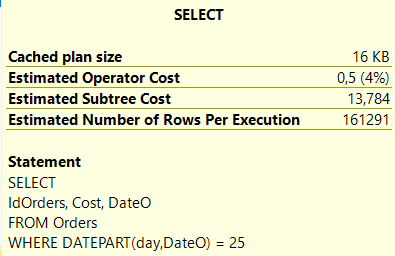
Время работы SQL Server с индексом
![]()
Запрос

Создаем таблицу без первичного ключа, чтобы проверить кластеризованный индекс. Все значения столбца PhNum уникальны.
Предполагаемая стоимость поддерева без индексов
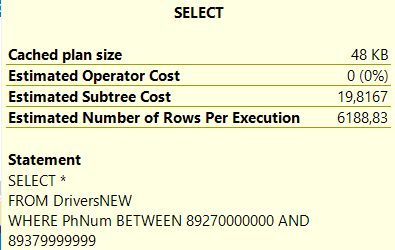
Время работы SQL Server без индекса
![]()
Кластеризированный индекс
![]()
Предполагаемая стоимость поддерева с индексом
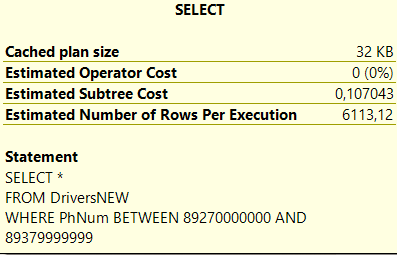
Время с индексом
![]()
Происходит индексация высокоселективных столбцов (здесь они уникальные), соответственно выигрыш по стоимости запросов, содержащих условие отбора по этому столбцу, очевиден.
Примечание: с помощью Redgate Data Generator было сгенерировано 5000000 записей для каждой таблицы дополнительно к уже имеющимся.
Вывод:
Кластеризованные индексы сортируют и хранят строки данных в таблицах или представлениях на основе их ключевых значений. Этими значениями являются столбцы, включенные в определение индекса. Существует только один кластеризованный индекс для каждой таблицы, так как строки данных могут храниться в единственном порядке.
Некластеризованные индексы имеют структуру, отдельную от строк данных. В некластеризованном индексе содержатся значения ключа некластеризованного индекса, и каждая запись значения ключа содержит указатель на строку данных, содержащую значение ключа.
Использование индексов позволяет оптимизировать поиск при верном использовании. Например, при проектировании кластеризированных индексом необходимо учитывать селективность столбцов, а при построении некластеризированныъ индексов необходимо учитывать занимаемую ими память.