

Построение и исследование моделей краткосрочного прогнозирования гликемии у больных сахарным диабетом
.pdfnew_data = DATA.'
Транспонированная матрица разделяется на две части: на обучающую и тестовую выборку. Для обучающей выборки выбиралось 80 процентов элемен-
тов из начала всей совокупности данных. Остальные 20 процентов элементов по-
падается в тестовую выборку. Разделение выборки выполняется с помощью сле-
дующих команд:
for i = 1 : (0.8 * (numel(DATA) / 10)) DataTrain(:, i) = new_data(:, i)
end
for j = 1 : (numel(DATA) / 10) - int64 (0.8 * (numel(DATA) / 10)) DataTest(:, j) = new_data(:, j + int64(0.8 * (numel(DATA) / 10))) end
Здесь DataTrain – это матрица размерностью 10 × 6189, представляющая обучающую выборку, а DataTest – это матрица размерностью 10 × 1547, пред-
ставляющая тестовую выборку данных.
Матрицу DataTest разделяется на две части: на входные и выходные дан-
ные. Входные данные будут использоваться как входные параметры для обучен-
ной модели, а выходные данные – как целевые эталонные значения. Разделение матрицы выполняется с помощью следующих команд:
for k = 1 : 9 DataTestInput(k, :) = DataTest(k, :)
end DataTestOutput(1, :) = DataTest(k + 1, :)
Здесь DataTestOutput – это матрица входных данных, в которую включа-
ются первые девять строк матрицы DataTest, а DataTestOutput – это матрица-
строка выходных данных, в которую включается последняя десятая строка мат-
рицы DataTest.
Созданные после ручного последовательного сэмплинга матрицы будут доступны в рабочем пространстве (Workspace) среды разработки MATLAB, как
это представлено на рисунке 2.19.
61
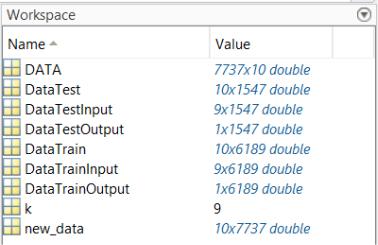
Рисунок 2.19 – Данные для обучения модели
2.7.Выводы
Вданной главе была дана характеристика исходных данных для дальней-
шего их использования в прогностических моделях. Было описано построение автоматического синтаксического анализатора данных биологического монито-
ринга, который осуществляет предварительную подготовку данных для дальней-
шего построения адекватных прогностических нейросетевых моделей и рассмот-
рено формирование обучающей и тестовой выборки с использованием аналити-
ческой платформы Deductor и среды разработки MATLAB.
62
ГЛАВА 3. ПОСТРОЕНИЕ МОДЕЛЕЙ ДЛЯ ПРОГНОЗИРОВАНИЯ
ГЛИКЕМИИ
В данной главе обосновывается выбор инструментальных средств для прогнозирования гликемии, разрабатывается структура нейросетевой модели.
Описываются параметры и результаты обучения модели линейной регрессии и нейросетевых моделей, производится оценка точности прогнозирования на обу-
чающих моделях.
3.1.Выбор средства разработки
Впоследние десятилетия прогресс компьютерных технологий определил процесс появления новых языков программирования. Это, в свою очередь, по-
служило созданию большого числа сред разработки для кодирования с исполь-
зованием этих языков. Вместе они организуют мощные инструменты по проек-
тированию и реализации как небольших программ, так и серьезных программ-
ных комплексов. Очень часто, одни и те же задачи можно решить с использова-
нием разных средств разработки. Однако, какие-то из них могут быть либо слиш-
ком избыточными для решаемой задачи, а других, наоборот, может быть недо-
статочно, и в обоих случаях при этом усложняется сам процесс программирова-
ния. Поэтому при выборе средств разработки необходимо опираться на решае-
мую задачу.
Вычислительные модули для решения поставленных задач должны обла-
дать следующим свойствами:
1)выполняться на вычислительных системах под управлением ОС
Microsoft Windows NT;
2)обладать приемлемой скоростью выполнения;
3)обладать меньшей трудоемкостью затрат для настройки среды раз-
работки;
4)иметь дружественный графический интерфейс.
Если с пунктами 1), 3) и 4) все довольно ясно, то пункт 2) необходимо по-
яснить. Поскольку вычислительные модули имеют в своей основе нейронные
сети, то скорость выполнения является очень важным критерием при выборе
63
среды разработки. И все дело именно в методах обучения многослойного пер-
септрона: алгоритм обучения этой сети требует многоразового повторения про-
цедур умножения и сложения больших массивов данных, а также вычисления некоторых функций (например, сигмоидальной функции). На сегодняшний день для их реализации возможно использование многих средств разработки, однако,
отметим наиболее популярные:
1)Python;
2)Deductor Studio;
3)MATLAB.
Во всех вышеперечисленных средствах предоставляют возможность для работы на платформе Microsoft Windows NT. Что же касается скорости выполне-
ния и затрат времени на настройку среды разработки, то преимущество стоит отдавать MATLAB и Deductor Studio, имеющие большую скорость выполнения и имеющие встроенные инструменты для предподготовки данных и нейросете-
вой пакет анализа данных, который упрощает решение поставленной задачи.
Учитывая все вышесказанное, наиболее предпочтительным платформой для реализации вычислительных модулей является именно пакет прикладных программ MATLAB. Основные его свойства:
1)использование матричной математики увеличивает быстродействие математических операций;
2)высокоуровневый язык программирования, используемый в среде
MATLAB, математико-ориентированный на технические вычисления и возмож-
ность генерации в программный код в язык С/С++;
3)есть поддержка двухмерной и трехмерной графических элементов;
4)большой объем встроенных математических функций;
5)существует возможность создания собственных функций (М-
файлы);
6)имеются средства разработки графического пользовательского ин-
терфейса (GUI-интерфейс);
64
7)наличие графической среды имитационного моделирования
Simulink, позволяющая при помощи блок-диаграмм в виде направленных гра-
фов, строить динамические модели, включая дискретные, непрерывные и ги-
бридные, нелинейные и разрывные системы [24].
Также для обучения целесообразным будет использования аналитической платформы Deductor Studio. Основные его возможности:
1)множество способов визуализации, позволяющие проводить разведочный
исравнительный анализ, выявлять тенденции;
2)выявление ошибок: встроенные алгоритмы поиска пропусков, аномалий,
дубликатов и противоречий, обнаружения шумов;
3)исправление ошибок в данных на основе алгоритмов машинного обучения,
статистики или по жестким правилам;
4)самообучающиеся алгоритмы и машинное обучение: деревья решений,
нейронные сети, самоорганизующиеся карты, ассоциативные правила;
5)анализ временных рядов: выявления сезонности, тренда и случайной со-
ставляющей.
В выпускной квалификационной работе первая часть моделей будет разра-
ботана в аналитической платформе Deductor Studio, вторая часть моделей будет
написана с использованием среды разработки MATLAB.
3.2. Разработка модели множественной линейной регрессии и оценка точ-
ности прогнозирования гликемии на обучающей выборке
Для доказательства предположения о том, что регрессионные модели яв-
ляются менее подходящими для решения задачи прогнозирования, чем нейросе-
тевые модели, произведем разработку модели линейной регрессии в аналитиче-
ской платформе Deductor Studio.
В Deductor Studio для построения линейных регрессионных моделей ис-
пользуется узел Линейная регрессия (рисунок 3.1). В нем реализован алгоритм расчета коэффициентов регрессии по методу наименьших квадратов.
65
Рисунок 3.1 – Мастер обработки После выбора вида модели происходит выделение входных и выходных
параметров модели (Рисунок 3.2). В качестве входных данных берутся значения углеводов, инсулина и глюкозы в крови за три предыдущих временных шага, в
качестве выходных данных – значения глюкозы в крови из горизонта прогноза.
Рисунок 3.2 – Выделение входных и выходных параметров
66

На рисунке 3.3 представлено окно мастера разбиения исходного набора данных на подмножества. В данном окне производится настройка разбиения ис-
ходного набора множества данных на обучающее и тестовое множество. Размер обучающего множества задается в процентном соотношении равным 100%, так как мастер обработки запущен для обучающего набора данных, сформирован-
ного на этапе сэмплинга.
Рисунок 3.3. – Мастер разбиения исходного набора данных После разбиения исходного набора выполняется настройка параметров от-
бора переменных в регрессионные модели (Рисунок 3.4). Сокращение числа не-
зависимых переменных призвано уменьшить размерность модели не только с тем, чтобы удалить из нее все незначащие признаки, не несущие в себе какой-то полезной для анализа информации, и тем самым упростить модель, но, и чтобы устранить избыточные признаки.
67
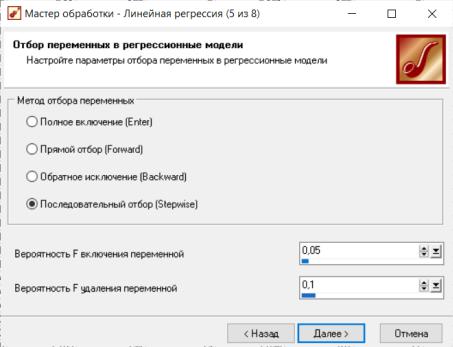
Рисунок 3.4 – Отбор переменных в регрессионные модели В качестве метода отбора переменных выбирается метод последователь-
ного отбора (Stepwise), который представляет собой модификацию метода пря-
мого отбора, отличающегося от него тем, что на каждом шаге после включения новой переменной в модель осуществляется проверка на значимость остальных переменных, которые уже были введены в нее ранее. В случае, если такие пере-
менные будут обнаружены, то их следует вывести из состава модели. После кор-
ректировки списка включенных в модель переменных осуществляется очередная итерация процедуры прямого отбора по поиску новой переменной, удовлетворя-
ющей условиям включения ее в состав модели.
На рисунке 3.5 представлена окно с результатами построения модели мно-
жественной линейной регрессии.
68
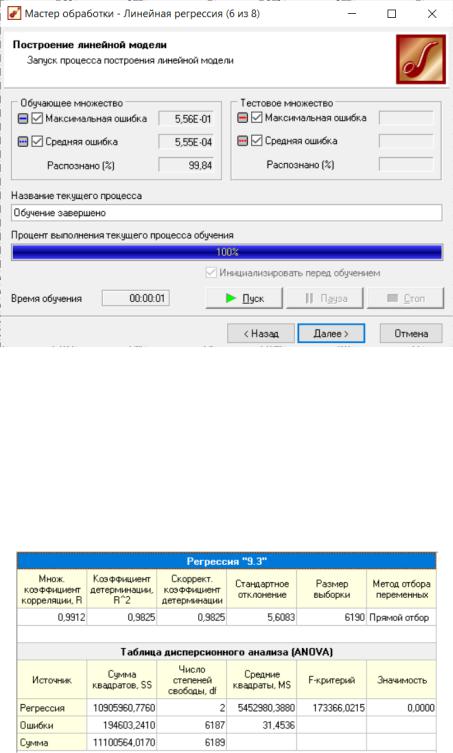
Рисунок 3.5 – Процесс построения линейной модели Построение при заданных параметрах шло около 1 секунды. Были распо-
знаны 99,84% данных. Средняя ошибка на обучающем множестве достигла
5,55 10−4. Максимальная ошибка на обучающей выборке достигла 5,56 10−1.
На рисунке 3.6 представлена таблица с результатами регрессионного и дис-
персионного анализа.
Рисунок 3.6 – Таблица регрессионного и дисперсионного анализа Множественный коэффициент корреляции , являющийся качественным
показателем линейной зависимости между зависимой переменной и объясняю-
щими переменными, равен 0,9912, что свидетельствует о сильной прямой связи между переменными.
69

Коэффициент детерминации 2 равный 0,9825 близок по значению к 1.
Это означает, что модель работает хорошо и имеет высокую значимость.
Для оценки качества модели прогноза используется диаграмма рассеива-
ния. На рисунке 3.7 представлена диаграмма рассеяния, которая отображает от-
клонение прогнозируемого значения гликемии от его истинностного значения.
Красными точками отмечены ответы модели линейной регрессии, зелеными точ-
ками – целевые параметры модели, красной линией – доверительный интервал значений.
Рисунок 3.7 – Диаграмма рассеяния Согласно построенной диаграмме рассеяния можно сделать вывод, что в
обученной модели присутствуют единичные выбросы и отклонения прогнозиру-
емых значений от эталонов минимальны.
На рисунке 3.8 представлена таблица, состоящая из трех столбцов, сгене-
рированная после построения модели линейной регрессии. Первый столбец
(BG4) – это целевые значения, второй столбец (BG4_OUT) – это ответы модели,
третий столбец (BG4_ERR) – это разница между целевыми значениями и отве-
тами модели.
70