

Учебники 80389
.pdfпрозрачности). Например, аквариум представляется дном и гранями. Каждый объект состоит, таким образом, из набора поверхностей.
Точное задание поверхности компактно, но технически непригодно для построения сцен. Поэтому в 3D-графике применяют приближенное представление гладкой поверхности множеством мелких плоских полигональных (то есть многоугольных) плиток, обработка которых элементарна. Такая аппроксимация (приближение) поверхности многогранником называется тесселяцией (tesselation - мозаика) этой поверхности. В качестве плиток обычно используются треугольники.
Чем больше плиток в тесселяции, тем реалистичнее выглядит объект и незаметнее шероховатости на стыках плиток. Общее число плиток в сценах современных игр исчисляется десятками тысяч. Увеличение числа плиток является основным путем достижения фотореалистической графики, к чему вплотную приблизилась потребительская 3D-графика. Вместе с тем возрастает и объем вычислений, требуя более производительных видеоплат.
Тесселяция большинства объектов производится всего один раз, до начала игры. Но некоторые объекты тесселируются динамически, при создании кадра. Тесселяция требует плавающей арифметики и выполняется процессором (под управлением приложения). Объекты могут задаваться и в уже протесселированном виде.
Тесселированные объекты задаются в некоторой канонической системе координат (С К), где их координаты постоянны. Перемещение объекта по сцене производится его отображением из канонической СК в СК сцены.
Как работает 3D-графика
В построении каждого кадра участвуют процессор и 3D-акселератор. При этом последовательно проводят следующие шаги:
*расчет сцены;
*обработку полигонов;
*рендеринг.
Расчет сцены
При расчете каждой сцены (geometry setup) производятся следующие действия:
1.Размещение объектов (transformation). Каждый объект, попадающий
вкадр, отображается из своей канонической СК в СК сцены. Заметим, что СК сцены не статическая, а связана с игроком и перемещается вместе с ним.
2.Расчет освещенности (lighting). Производится для каждой плитки, исходя из расположения и интенсивности источников света, а также теней, отбрасываемых другими плитками. Обычно расчет производится только для вершин полигона, а освещенность всей плитки получается интерполяцией.
3.Отсечение (clipping) полигонов, выходящих за кадр.
4.Привязка текстур к полигонам - задается, какая текстура будет наложена на каждый полигон и относительное положение полигона относи-
211
тельно текстуры. Требуется только для динамической замены текстуры. Для статических объектов наподобие монстра, которые заданы в тесселированном виде, привязка уже выполнена.
Текстура (map, texture - ткань, рисунок) - квадратные рисунки, играющие роль обоев. Накладываются на полигоны для придания поверхностям реалистичности. Вы вероятно знаете, что элемент изображения на экране называется пиксел (Picture Element). Текстура тоже состоит из элементов, так как это - растровое изображение, элемент текстуры называется текселом (по аналогии с пикселом).
Расчет сцены иногда сокращенно называют TL по имени основных шагов (Transformation and Lighting). Заметим, что сцена рассчитывается полностью, прежде чем будет передана для дальнейшей обработки.
Вся работа по расчету сцены производится в арифметике с плавающей точкой, а сама сцена находится в основной памяти.
Вплоть до самого последнего времени расчет сцены выполнялся центральным процессором. Но в некоторых чипах последних поколений расчет выполняет графический сопроцессор (GPU)
Обработка полигонов
Обработкой полигонов (Polygon setup, иногда Triangle setup) занимается выделенный блок Polygon setup engine (движок обработки полигонов) 3D акселератора графического чипсета. На блок из основной памяти по шине AGP посылаются полигон за полигоном. Блок обрабатывает полигон и сразу отсылает его на блок рендеринга, работая как конвейер.
Производительность блока обработки полигонов называется Triangle throughput и представляет собой пиковую скорость обработки треугольников в секунду. Реальная скорость обработки треугольников может быть ниже, если, например, процессор не успевает рассчитывать и передавать необходимую видеоплате информацию. Т.е., медленный процессор замедляет работу 3D ускорителя.
Скорость обработки современных чипсетов составляет 15 млн. треугольников в секунду и более.
Обработка каждого треугольника включает:
1.Прием координат вершин треугольника и их атрибутов: освещенности, координат в текстуре(это называется текстурными координатами) и др.
2.Коррекцию перспективы треугольника. То есть фигура масштабируется в зависимости от ее удаленности.
3.Проектирование треугольника на плоскость XY экрана
4.Вычисление пикселов, входящих в проекцию треугольника.
5.Расчет для этих пикселов атрибутов. Расчет производится интерполяцией значений, задаваемых обычно на вершинах треугольника.
6.Посылкуобработанноготреугольникаследующемублоку(рендеринг). Рендеринг (render - представлять) - преобразование рассчитанной
сцены (после фазы обработки полигонов) в виде пикселов в буфер кадров (для последующего вывода на экран).
212
Рендеринг производится выделенным блоком Fill engine (движок заполнения) 3D акселератора графического чипа, который обрабатывает "на лету" поток треугольников от предыдущего блока.
Производится попиксельное заполнение треугольника. Для каждого пиксела вначале вычисляется, является ли он видимым (обычно посредством z-буфера). Еслипикселневидим, товыводитьеговбуфер, очевидно, ненужно.
Далее производятся следующие действия:
1.Вычисляется накладываемый тексел (иногда весьма изощренно).
2.Производится наложение тексела с учетом освещенности пиксела.
3.Опционально на пиксел накладываются эффекты, увеличивающие реалистичность (туман, карта освещенности, карта рельефа, и т.д.).
4.Производится запись пиксела в буфер кадров.
После заполнения буфера кадра весь кадр может быть опционально подвергнут постобработке. Примером постобработки является сглаживание, улучшающее изображение, или наложение дополнительного изображения на часть кадра для создания эффекта зеркального отражения у части кадра.
Пиковую производительность блока заполнения пикселов называют Fill rate (скорость заполнения, прорисовки, растеризации), и измеряется она в количестве пикселов в секунду. Реальная скорость прорисовки много меньше, и тем меньше, чем больше текселов накладывается на один пиксел, поэтому рассчитывается для наиболее простого режима текстурирования.
Скорость заполнения у современных чипсетов составляет 400 млн. пикселов в секунду и более.
В ЗD - графике, обязательны минимум 2 буфера кадров (БК), в отличие от 2D-графики (это называете двойной буферизацией, double buffering). Дело в том, что обычно в процессе заполнения каждый пиксел многократно переписывается (например, при постобработке) пока не получится окончательный вид кадра. Поэтому па экран выводится законченный буфер кадров, а во втором готовится следующий кадр.
Для большей скорости графики (более гладкого воспроизведения) применяются также 3 и более кадровых буфера, что является характеристикой чипсета.
Эволюцию графических ускорителей можно представить так:
Первое поколение, которое было более-менее распространено – это акселераторы, использующие API Direct3D 5 и Glide. Представителем первых была NVIDIA Riva128, а вторых – 3Dfx Voodoo. Карты этого поколения брали на себя только последнюю часть построения сцены – текстурирование и закраску. Все предыдущие этапы выполнял CPU.
Второе поколение использовало API Direct3D 6, также в это время началось стремительное возрождение API, разработанного SGI – OpenGL. Представителями карт того времени были NVIDIA RivaTNT и ATI Rage. Это было практически эволюционноеразвитие карт предыдущего поколения.
Третье поколение – Direct3D 7. Именно тогда появились карты, снабженные TCL-блоком, снимавшим с CPU значительную часть нагрузки.
213
Этот блок отвечал за трансформацию, освещение и отсечение. (TCL - Transformaton-Clipping-Lighting) Теперь видеокарта строила сцену само-
стоятельно – от начала до конца. Представителями этого поколения стали
NVIDIA GeForce256 и ATI Radeon.
Четвёртое поколении – очередная революция. Кроме прочих новых возможностей API Direct3D 8 (и 8.1) эти карты принесли с собой самую главную возможность – аппаратные шейдеры. Причину их появления мы опишем чуть позже. Представляют это поколение NVIDIA GeForce 3,4 и ATI Radeon 8500, 9000, 9100, 9200.
Пятое поколение – это, в основном, развитие шейдерных технологий (версия 2.0). Это поколение, поддерживает API Direct3D версии до 9.0b
включительно, представляют ATI RADEON 9500, 9600, 9700, 9800, Х800, а также NVIDIA GeForce FX 5200, 5500, 5600, 5700, 5800, 5900, 5950.
Шестое поколение – это поколение DirectX9.0c. Оно включает в себя серию NVIDIA GeForce 6 и платы GeForce 6800Ultra/6800GT/6800 на базе чипа NV40. Эти карты поддерживают шейдеры версии 3.0, и предлагают некоторые другие возможности.
Вершинный и фрагментный процессоры, шейдеры.
Причиной появления шейдеров стало отсутствие какой-либо гибкости у фиксированного TCL блока. Ждать момента, когда производители внесут очередную порцию функций в TCL блок видеокарт – не лучший выход. Разработчикам не нравилась мысль, что для того, чтобы внести в игру новый эффект им надо годик подождать выхода нового ускорителя. Производителям пришлось бы постоянно увеличивать как сами чипы, так и драйверы к ним. Это и стало причиной появления шейдеров – программ, способных настраивать ускоритель так, как того требует следующая сцена.
Шейдер – это программа, которая загружается в ускоритель, и конфигурирует его узлы для обработки соответствующих элементов. Снимаются ограничения заранее заданным набором способов обработки эффектов, и появилась возможность составлять из стандартных инструкций любые программы (ограниченные спецификациями используемой версией шейдера), задающие необходимые эффекты.
Шейдеры делятся по своим функциям на вершинные и фрагментные (пиксельные): первые работают с вершинами и треугольниками, заменяя собой функциональность TCL блока (сейчас он практически исчез – в случае необходимости он эмулируется специальным вершинным шейдером). Фрагментные же шейдеры служат для создания программ обработки фрагментов размеров 2х2 пикселя – квадов. Они необходимы для реализации некоторых текстурных эффектов.
Шейдеры также характеризуются номером версии - каждая последующая добавляет к предыдущим всё новые и новые возможности.
Спецификация фрагментных и вершинных шейдеров версия 3.0, поддерживается через API DirectX 9с.
Главное отличие шейдеров 3.0 от предыдущих версий (кроме 2.0а) –
214
это DFC – Dynamic Flow Control – динамическое управление потоком. С одной стороны – это великолепная возможность, позволяющая заметно повысить скорость построения сцены, с другой – лишние транзисторы, и соответственно лишнее тепло и ниже максимальные частоты.
В ситуации, когда для какой-либо вершины (или фрагмента) шейдер нужно выполнить не весь, а только 12% от него, используя DFC выполним лишь те необходимые 12%, основываясь на параметрах объекта. Без DFC необходимо выполнять шейдер целиком. С DFC выигрыш может быть в 10 раз, при этом, заплатив пониженной производительностью на вершинах, для которых нужно выполнить все 100% шейдера.
Первые шейдеры состояли всего из нескольких команд, и их нетрудно было написать на низкоуровневом языке ассемблера. Хотя сложность отладки ассемблерного кода поначалу отпугнула от шейдеров многих разработчиков. Но с ростом сложности шейдерных эффектов, насчитывающих иногда десятки и сотни команд, возникла необходимость в более удобном, высокоуровневом языке написания шейдеров. Их появилось сра-
зу два: NVIDIA Cg (C for graphics) и Microsoft HLSL (High Level Shading Language) - последний является частью стандарта DirectX 9. Cg не получил широкого распространения, ввиду появления нового, более продвинутого
GLSL – аналога HLSL для API OpenGL.
Последней реализацией является DirectX 10 в котором по сравнению с DX9 – уменьшенное количество возможных состояний ядра за счёт большей унификации. Большее количество инструкций выполняется в рамках одного runtime, благодаря чему происходит меньше прерываний на обращение процессора к драйверу и смену состояния ядра API. Через DirectX 10 поддерживается Shader Model 4 (4 версия шейдеров) в которой включено большое количество новых инструкций и унифицирован их набор, введены новые регистры и константы и многое другое.
Революционным шагом в порядке обработки данных, которые в дальнейшем станут трёхмерным изображением, является концепция потоковой обработки.
Потоковый вывод данных даёт возможность намного быстрее отослать на повторную обработку данные, уже прошедшие через вершинный или геометрический шейдер, с помощью специального потокового буфера (stream buffer). Благодаря этому не тратится время на ожидание завершения работы пиксельного шейдера и растеризации.
В DirectX 10: введён новый вид шейдеров – geometry shaders (рис.9.32). Они позволяют работать с геометрией не на уровне отдельной вершины, как в случае с вершинными шейдерами, а на уровне примитивов. Это означает, что не нужно больше менять каждую вершину, собираемую затем в линию, можно геометрическим шейдером изменить всю линию. Это должно серьёзно разгрузить центральный процессор и предоставить ему работу только с движком игры и AI. Работа с геометрическим шейдером позволит затрачивать намного меньшее количество тактов графиче-
215
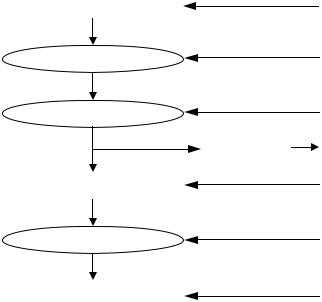
Input Assembler |
|
|
|
|
|
|
|
|
|
Vertex Shader |
|
|||
Geometry Shader |
Video |
|||
Memory |
||||
|
|
|
|
(Buffer |
|
|
Stream |
|
|
|
|
|
Texture, |
|
|
|
|
|
Constant |
Rasterizer |
|
|
|
|
|
Buffer) |
|||
Pixel Shader |
|
|||
|
|
|||
Output Merger |
|
|
||
|
|
|
|
|
Рис.9.32. Многопотоковый конвейер |
|
|||
ского процессора на просчёт сложных геометрических преобразований, в частности, всеми любимых реалистичных волос. Также геометрические шейдеры помогут увеличить реалистичность изображения воды за счёт возможностей тесселяции (разбиения полигонов на более мелкие). NVidia GeForce 8800 поддерживает DirectX 10.
8.3.7. Особенности видеопамяти
Текстуры высокого разрешения имеют большие размеры. Поэтому производительность видео карты не в последнюю очередь зависит от характеристик видео памяти. Первыми чипами памяти, пригодными для использования в компьютерной графике были DRAM, которая имела асинхронный доступ (работала на независимой частоте). Стоит сказать, что для считывания информации требовалось два цикла. Сегодня разные производители используют различные типы видео памяти.
VRAM (video RAM). Разрабатывалась как альтернатива DRAM, призвана увеличить производительность за счет записи и считывания информации за один цикл. Вариант WRAM (windows RAM) – имеет лучшую, примерно, на 25% пропускную способность, имеет ряд встроенных, часто используемых функций. Из-за специальных методов доступа, применяется лишь производителями Matrox и Number Nine.
3D-RAM. Разработана фирмой Mitsubishi. Объединяет все лучшее от архитектур VRAM, WRAM и DRAM. Специально оптимизирована для визуализации 3D графики. Имеет ограниченную область применения, в связи с высокой стоимостью.
CDRAM (Cached RAM). Включает обычный блок памяти DRAM +
216
блок кэш типа. Используется в качестве текстурной памяти в профессиональных видеоконтроллерах. Скорость передачи = 800 Mb/sec.
MDRAM (Multi bank DRAM). Разработана фирмой MoSys. Характе-
ризуется наличием множества независимых банков памяти.
SGRAM (Synchronous Graphics RAM). Является вариантом DRAM. В
отличие от DRAM имеет синхронный доступ.
Direct RAM Bus DRAM. Отличается собственной внутренней шиной (RAM Bus channel), скорость передачи данных по которой приблизительно равна 800 Mb/sec. Теоретически пиковая пропускная способность DR DRAM = 3,6 Gb/sec, на шине 64 bit при 100 Мгц.
DDR SDRAM (Double Data Rate SDRAM). Пожалуй самая распро-
страненная видеопамять сегодня. Это связано как с техническими характеристиками, так и с ценами на память данной архитектуры.
Традиционно названия поколений памяти для графических адаптеров соответствовали типам памяти для персональных компьютеров: GDDR-1 соответствовала DDR первого поколения, a GDDR-2 – появившейся в 2004 году DDR-2. Однако архитектурно GDDR-3 практически не отличается от GDDR-2 (и соответственно DDR-2) – данные по-прежнему передаются по двум фронтам сигнала, а эффективная пропускная способность вчетверо превосходит пропускную способность банка памяти. Основное отличие GDDR-3 от GDDR- 2 – в напряжении питания, сниженном с 2.5 до 1.8 В. Это позволило значительно снизить уровень тепловыделения, являющийся главным недостатком GDDR-2. Кроме того, была модернизирована архитектура микросхем, что позволило увеличить тактовую частоту шины памяти. В настоящее время максимальная эффективная частота шины при применении памяти GDDR-З можетдостигать1.6 ГГц(таблица8.1).
|
|
|
|
|
Таблица 8.1 |
Тип памяти |
Напряжение |
Тактовая частота |
Максимальнаяэффектив- |
Задержки |
|
|
питания, В |
шины, МГц |
наячастоташины, ГГц |
чтения, такт |
|
GDDR 1 |
2.5 |
183 |
- 500 |
1 |
3,4,5 |
GDDR 2 |
2.5 |
400 |
– 500 |
1 |
5,6,7 |
GDDR 3 |
1.8 |
500 |
- 800 |
1,6 |
5,6,7 |
Объем видеопамяти является важным параметром видеоадаптера, оказывающим влияние не только на качество работы видеоподсистемы компьютера, но и на стоимость видеоадаптера. Поэтому, производители видеоадаптеров обычно выпускает целую линейку видеоадаптеров, различающихся объемом видеопамяти и рассчитанных на различные сегменты рынка. Наибольшее распространение получили видеоадаптеры с объемами видеопамяти 32, 64, 128 Мб, также известны видеоадаптеры с 256 Мб видеопамяти.
Производительность. В первую очередь 3D ускорители принято оценивать по производительности, а лишь затем по качеству картинки. Очевидно, что фактор скорости, в основном, является определяющим при выборе той или иной карты. Современные видео карты для домашнего компьютера
217
рассчитаны, в основном, на работу с 3D играми. Поэтому, говоря о производительности, обычно сосредотачиваются на двух параметрах – Fill rate (время заливки 3D моделей) и Throughput (скорость построения 3D моделей). Производители, в свою очередь, указывают пиковую производительность, которая заметно отличается от показателей тестирования на конкретных приложениях. Действительные значения Fill rate в среднем ниже пиковых на 20%, а Throughput от 27% до 67%. Значения выше указанных показателей во многом зависят от приложений, на которых тестировались карты, т.к. в разных приложениях могут использоваться разные методы текстурирования и фильтрации. Например, видеопамять DDR SDRAM достигает пиковой пропускной способности лишь при обработке единых массивов, при обработке же отдельных элементов производительность снижается. Показатель Fill rate в основном зависит именно от видеопамяти и графического процессора, т.к. именно между ними происходит основной обмен данными при текстурировании. В построении же самих моделей очень важную роль играет CPU и оперативная память компьютера. Отсюда такой разброс значений показателя Throughput и зависимость производительности видео карты от CPU.
8.3.8. Видеоадаптеры – эволюция интерфейсов
Старые графические платы имели интерфейс ISA и объём памяти который редко превышал 512 Кбайт. Появление специально расширенной шины VESA, повысило пропускную способность интерфейса видеоадаптеров. Такие карты устанавливались сразу в два слота, размером на всю ширину материнской платы, объем памяти в 2 Мбайт считался на начало 90-х годов огромным достижением. Сильным рывком в развитии видеоадаптеры стало использование шины PCI. В середине 90-х, были созданы первые 3Dакселераторы, и ставки в игровой индустрии резко пошли в гору. Слоты шины PCI пока всё ещё неизменно присутствуют на каждом современном ПК и сегодня, хотя видеокартами они давно уже не используются. Однако её возможностей все равно не хватало, и фирма Intel разработала шину AGP (Accelerated Graphics Port), которая, по сути, является отдельным каналом между видеоадаптером и памятью компьютера.
Появившаяся в 1997 году первая AGP 1.0 могла работать в двух режимах передачи данных 1Х/2Х (266/533 Мбайт/с), используя напряжение 3,3 В. Здесь под напряжением подразумевается уровень логической "1" сигналов, которыми видеокарта и системная плата обмениваются между собой, а не напряжение питания видеоадаптера со слота на материнскую плату. С 1998 года массово внедряется следующая спецификация, AGP 2.0, со скоростью передачи данных в режиме 4Х (1066 Мбайт/с) и пониженным напряжением сигнальных уровней 1,5 В. Последняя спецификация, AGP 3.0, использует восьмикратный режим передачи данных 8Х (2133 Мбайт/с) и ещё более низкое напряжение сигнала – 0,8 В.
Современному компьютеру нужна была замена, и прежде всего, устаревшей шине PCI и её производной, которой является AGP. При внедрении
218
новой универсальной высокопроизводительной шины как единой архитектуры ввода/вывода внутри компьютера нет никакого смысла разрабатывать интерфейс исключительно для видеокарт, как были вынуждены поступать раньше на примере AGP. В конце 2004 года на материнских платах начала появляться новая шина PCI-Express, удовлетворяющая самым высоким требованиям по пропускной способности. Видеоакселераторы первыми стали использовать новый интерфейс.
Базовая спецификация PCI-Express была утверждена в 2002 году. Ее разработка проводится организацией PCI-SIG при активной поддержке Intel и ряда других ведущих компаний компьютерной отрасли. В отличие от старых параллельных шин PCI, AGP, ISA, принцип передачи данных PCI-Express является последовательным. PCI-Express работает по принципу "точка-точка", то есть одна шина в чистом виде может объединять только два устройства. Поэтому в её архитектуре предусматривается свитч, распределяющий сигналы между всеми устройствами PCI-Express. Это принципиальное отличие от PCI, где на общую шину включаются все устройства.
За счёт последовательной передачи данных удается достичь огромных тактовых частот, на два порядка превышающих рабочие частоты старых параллельных шин. Сейчас PCI-Express работает на частоте 2,5 ГГц, хотя в перспективе она может быть легко масштабирована, лимитом здесь считается 10 ГГц. Уже при частоте 2,5 ГГц достигается скорость передачи данных 250 Мбайт/с независимо в каждую сторону (полный дуплекс). Из этого потока нужно вычесть потери на избыточное кодирование по схеме "8/10", применяемое в PCI-Express, и мы получим эффективную скорость передачи данных на уровне 200 Мбайт/с на одну линию передачи.
Последовательная шина требует меньше проводников на печатной плате, таким образом, высвобождается место, упрощается дизайн, уменьшаются электрические наводки. Каждая линия передачи данных состоит из двух дифференциальных контактных пар, для чего необходимо только четыре контакта. Уровню логической "1" сигнала PCI-Express соответствует напряжение 0,8 В. Для PCI-Express предусмотрена автономная система энергосбережения: питание от разъёма должно отключаться при отсутствии активности в промежутке определённого времен.
Разработчики уделили внимание проблеме масштабируемости производительности. Они отошли от принципа единого разъёма – в шине PCIExpress изначально предусмотрена возможность наращивания независимых линий передачи данных (рис.8.33, таблица 8.2). Линия передачи PCI-Express х1 (одна линия) имеет весьма скромные показатели – эффективная пропускная способность до 200 Мбайт/с. Но за счет добавления стандартных секций в разъёме, пропускная способность может быть легко наращена до 6400 Мбайт/с – PCI-Express x32 (32 линии). Предаваемые данные поровну распределяются между линиями по принципу: n-й байт на n-ю линию. При всём этом, линии передачи данных в разъёме PCI-Express остаются независимыми, работают в асинхронном режиме. Ко всему достигается обратная совмести-
219

мость: в многоканальные разъёмы PCI-Express можно вставлять платы расширения, рассчитанные на меньшее число каналов.
|
|
Таблица 8.2 |
Предусмотренные стандартом варианты масштабирования PCI-Express |
||
Тип разъёма |
Число контактов в разъёме |
Эффективная пропускная способ- |
(число линий) |
|
ность (в одну сторону), Мбайт/с. |
PCI-Express x1 |
36 |
200 |
PCI-Express x4 |
64 |
800 |
PCI-Express x8 |
98 |
1600 |
PCI-Express x16 |
164 |
3200 |
PCI-Express x32 |
294 |
6400 |
Начиная с 2007 года в поколении PCI-Express реализована возможность автоматического снижения скорости с 5 Мбайт/с до стандартных сейчас 2,5 Мбайт/с, в тех случаях, когда это необходимо.
Разъём PCI-Express (рис.8.33) делится ключом на две части. Первая часть (та, что ближе к задней стенке корпуса) одинакова для всех разъёмов и предназначена для питания карты. Сюда подводятся напряжения 3,3 В и 12 В. Спецификацией предусматривается подводка мощности 60 Вт. По другую сторону от ключа расположены контакты секций линий передачи данных: от одной до тридцати двух. Соответственно количеству линий передачи меняется длина разъёма. Самые короткие разъёмы PCI-Express x1, длина PCI-Express x16 примерно равняется размеру обычного PCI слота.
Эффективная пропускная способность PCI-Express x16 заметно выше таковой у AGP 8X: 3200 Мбайт/с против примерно 2000 Мбайт/с у AGP 8X. Другое дело, что даже самые современные видеоакселераторы пока не могут загрузить шину PCI-Express x16 работой полностью. Возможности AGP 8X пока что не исчерпаны полностью. Нагрузка на шину сглаживается также и за счет того, что для современных видеокарт с 256 Мбайт памяти на борту из-за большого буфера не требуется частая подкачка данных в память. Да и разработчики приложений, прежде всего игр, видимо, стараются писать
программы так, чтобы не нагружать видеокарту потоком информации более, чем доступно AGP 8X. Ситуация может изменится лишь в перспективе, с появлениемболеемощныхвидеоакселераторовиновыхприложений.
8.3.9. Принцип действия технологии SLI
В компьютерной индустрии повышение производительности обычно осуществлялось за счет роста частот, использование новых интерфейсов и
220