

Учебное пособие 800628
.pdf
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 2 |
|
|
|
|
Исследование двух сетей LeNet для двух классов |
|
|
||||||||||||||||
|
|
|
|
ПЭТ |
|
|
|
|
Банки |
|
|
|
|
Другое |
|
Общая |
||||||
|
Образец |
1 |
2 |
|
3 |
|
4 |
5 |
6 |
7 |
|
8 |
|
9 |
1 |
1 |
1 |
|
1 |
1 |
1 |
правильно |
|
|
|
|
|
0 |
1 |
2 |
|
3 |
4 |
5 |
сть |
||||||||||
LeNet (can) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
Правильно |
1 |
1 |
|
1 |
|
1 |
1 |
0 |
0 |
|
1 |
|
1 |
1 |
1 |
1 |
|
1 |
1 |
1 |
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
сть |
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
87% |
|
|
% |
9 |
9 |
|
9 |
|
9 |
5 |
8 |
9 |
|
9 |
|
8 |
7 |
7 |
9 |
|
9 |
9 |
9 |
|
|
|
|
|
|
|
|
||||||||||||||||
|
8 |
6 |
|
6 |
|
1 |
8 |
4 |
9 |
|
9 |
|
8 |
4 |
2 |
9 |
|
6 |
9 |
9 |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
LeNet (pet) |
Правильно |
1 |
1 |
|
1 |
|
1 |
1 |
0 |
1 |
|
1 |
|
1 |
1 |
1 |
1 |
|
1 |
1 |
1 |
|
сть |
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
93% |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
% |
9 |
7 |
|
6 |
|
6 |
9 |
7 |
9 |
|
6 |
|
8 |
5 |
9 |
9 |
|
9 |
9 |
9 |
|
|
|
|
|
|
|
|
||||||||||||||||
|
1 |
6 |
|
9 |
|
7 |
9 |
0 |
2 |
|
4 |
|
8 |
8 |
8 |
9 |
|
8 |
8 |
8 |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
MobileNet – это более сложная CNN, чем LeNet. Изображения, используемые для обучения сети, изменяются до 224x224 и передаются скрытым слоям. Это обеспечивает более подробное изучение моделей [5,7].Очевидно, что эта CNN обеспечивает лучшую точность, чем LeNet, с сопоставимой скоростью распознавания на Raspberry PI (табл. 3).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 3 |
|
|
|
|
|
|
Исследование MobileNet для 2 классов |
|
|
|
||||||||||||||
|
|
|
|
ПЭТ |
|
|
|
Банки |
|
|
|
|
Другое |
|
|
Общая |
|||||||
|
Образец |
1 |
2 |
|
3 |
|
4 |
5 |
6 |
7 |
|
8 |
|
9 |
1 |
1 |
1 |
|
1 |
|
1 |
1 |
правильно |
MobileNet |
|
|
|
|
0 |
1 |
2 |
|
3 |
|
4 |
5 |
сть |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
Правильно |
9 |
9 |
|
8 |
|
8 |
9 |
8 |
6 |
|
6 |
|
6 |
5 |
5 |
8 |
|
9 |
|
9 |
9 |
|
|
|
сть |
1 |
1 |
|
1 |
|
1 |
1 |
0 |
1 |
|
1 |
|
1 |
1 |
1 |
1 |
|
1 |
|
1 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
93% |
|
|
% |
1 |
2 |
|
5 |
|
6 |
1 |
2 |
9 |
|
3 |
|
9 |
3 |
5 |
3 |
|
8 |
|
3 |
8 |
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|||||||||||||||
В открытом доступе можно найти описание множества нейронных сетей глубокого обучения (Deep neural networks, DNN), которые достигают этого уровня точности [15-20]. Имея примерно такую же точность распознавания, меньшие архитектуры DNN предлагают такие преимущества, как снижение требований к пропускной способности канала для экспорта новой модели в автономный автомат, а так же уменьшение требований к вычислительным мощностям устройства. Кроме того, с помощью методов сжатия модели мы можем сжать MobileNet до размеров менее 0,5 МБ при сохранении высокой распознающей способности [5,7].
Оценка быстродействия нейронной сети MobileNet при использовании разных языков программирования для работы с OpenCV
MobileNet – это класс сверточной нейронной сети, разработанный исследователями из Google [15,16]. Они создавались таким образом, чтобы потреблять мало ресурсов и быстро запускаться прямо на телефоне
OpenCV – одна из популярных библиотек компьютерного зрения. Главную роль в реализации наших программ будет играть модуль dnn [17,18]. Основная возможность dnn заключается в загрузке и запуске нейронных сетей (inference).
Программа на Python содержит несколько строк по вызову сети (см рис.1.)
231

Рис. 1. Фрагмент кода программы на Python
Строки 6-9 отвечают за загрузку нейронной сети, отправку информации в нейронную сеть и получение информации из нее. Файл deploy.proto.txt содержит в себе структуру нейронной сети, а файл mobilenet_bottles_another_iter_7000.caffemodel содержит в себе информацию о весах нейронов сети, этот файл был получен путем тренировки сети на основе файла deploy.prototxt, а также наборе изображений, соответствующих каждому из описанных ранее классов. Оба эти файла были сформированы заранее. Чтобы узнать к какому классу нейронная сеть отнесла объект на изображении, находим максимальный аргумент из информации на выходе при помощи out.argmax(). Максимальный аргумент – показывает к какому классу объект подходит больше всего. Пример работы программы показан на Рис. 2.
Рис. 2. Результат работы программы на Python
Программа на C++, выполняющая те же вызовы, представлена на Рис.3.
Рис. 3. Фрагмент кода программы на C++
Программа выполняет аналогичные функции, что и программа на Python. результат работы программы показан на Рис. 4.
Рис. 4. Результат работы программы на C++
Анализ быстродействия
Для оценки времени работы программ обе программы были модифицированы таким образом, чтобы производились замеры времени работ интересующих нас функций. Также, для получения более корректных результатов, измерения будут проводиться не на одном изображении, а на наборе из ста изображений, объекты на которых относятся к разным классам, а сами изображения при этом имеют разные
232
размеры. Набор одинаков для программ на обоих языках программирования. Для удобства сравнения были выбраны участки кода выполняющие схожие функции на разных языках.
Результат запуска обеих программ показан в таблице 4.
|
|
|
Таблица 4. |
Анализ времени работы функций программ |
|
|
|
|
|
Python |
C++ |
Функций до цикла |
|
|
|
Загрузка нейронной сети |
|
0,0951 |
0,1161 |
|
|
|
|
Средние показатели при обработке ста изображений |
|
|
|
Загрузка изображения |
|
0,0074 |
0,0065 |
|
|
|
|
Формирование пакета для нейронной сети |
|
0,0062 |
0,0077 |
|
|
|
|
Работа нейронной сети |
|
0,0015 |
0,0005 |
Получение информации из нейронной сети |
|
2,3057 |
1,4707 |
|
|
|
|
Определение класса объекта на картинке |
|
0,0015 |
0,0013 |
|
|
|
|
Суммарное время |
|
2,3225 |
1,4870 |
Итог |
|
|
|
Общее время |
|
232,3590 |
148,9100 |
|
|
|
|
Анализ используемой программами памяти
Для анализа потребляемой программами памяти, воспользуемся стандартной в ubuntu библиотекой time (usr/bin/time). Данная библиотека показывает время работы программы (изначально время планировалось измерять именно так, но позже было принято решение измерить время работы отдельных функций, поэтому от идеи использования библиотеки time отказались), а также потребляемую программой память.
Ниже в таблице 5 показаны результаты после выполнения программы обработки ста изображений с библиотекой time.
Таблица 5.
Анализ потребления памяти программами
|
Python |
C++ |
Потребление памяти, |
444164 |
76020 |
Кб |
|
|
Выводы
Результатом проделанной работы стала оценка нескольких подходов к распознаванию и классификации изображений и их применение для распознавания и сортировки пустых контейнеров в автомате по приёму тары. Самое точное решение было обработано CNN MobileNet, но мы получили сопоставимую точность с моделями LeNet после нескольких улучшений.
Проводимое исследование не было ограничено изучением CNN и возможности переноса на устройства IoT. Мы пытались понять, как предварительная обработка изображения и улучшение данных наборов обучения и тестирование могли влиять на точность распознавания и после нескольких экспериментов пришли к выводам, что обучение LeNet может быть более эффективным, если мы используем 56×56 и более высокое изменение учебных образов, использование двух моделей LeNet каждого из 2 классов более эффективно, чем одиночная модель из 3-6 классов. Предварительная обработка обучающих образов (резкость) может улучшить распознавание только для модели банок, состоящей из двух классов, но в тоже время уменьшает точность для аналогичной модели ПЭТ бутылок. Поэтому мы должны настраивать эти две модели по-разному.
233
Библиографический список
1.Reverse vending 101: a beginner’s guide [Электронный ресурс]. – 2011. – Режим доступа: https://www.tomra.com/en/collection/reverse-vending/reverse-vending-news/2017/how- does-a-reverse-vending-machine-work/ – Дата обращения 30 декабря 2017.
2.Cost of a Deposit Return Reverse Vending Machine [Электронный ресурс]. – Режим
доступа: |
http://www.zerowastescotland.org.uk/sites/default/files/reverse%20v |
%20- |
%20CFE%20response.pdf– Дата обращения 30 декабря 2017. |
|
|
3.Rosebrock A. Histogram of Oriented Gradients and Object Detection [Электронный ресурс]. – Режим доступа: https://www.pyimagesearch.com/2014/11/10/histogram-oriented- gradients-object-detection/– Дата обращения 30 декабря 2017.
4.Rosebrock A. Practical Python and OpenCV + Case Studies [Электронный ресурс]. – 2016. – Режим доступа: https://www.pyimagesearch.com/2016/11/20/Python-OpenCV/– Дата обращения 30 декабря 2017.
5.Iandola F. Forrest, Han Song, Moskewisz W. Mattewet. al. SqueezeNet: MobileNet-level accuracy with 50x fewer parameters and <0.5 Mb model size, ICLR’17 conference proceedings, p.207-212, 2017.
6.LeCun Y., Bottou L., Haffner P., Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278-2324. 1998.
7.Krizhevsky Alex, Sutskever Ilya, Geoffrey E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks [Электронный ресурс]. – Режим доступа:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural- networks.pdf– Дата обращения 30 декабря 2017.
8.Огрель Л. Д. Оценка накопления, сбора и переработки отходов пэтф в России // Экологический вестник России – 2012. – №4. – С. 26-31.
9.Kokoulin А. N., Tur A. I., Yuzhakov A. A. Convolutional Neural Networks Application in Plastic Waste Recognition and Sorting // Proceedings of the 2018 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (2018 ElConRus)
10.Lasoff M. A., An Rv By Any Other Name // Waste Age – 2000. – Vol 31 №7. – p. 34.
11.Kokoulin A., May I., Kokoulina A., Image Processing Methods in Analysis of Component Composition and Distribution of Dust Emissions for Environmental Quality Management // Proceedings of 10th International Conference on Large-Scale Scientific Computations (LSSC) Bulgarian Acad Sci, Sozopol, BULGARIA. JUN 08-12, – 2015. – Vol.9374, – pp.352-359
12.Kokoulin A., Methods for Large Image Distributed Processing and Storage // IEEE EUROCON Conference, Zagreb, CROATIA, JUL 01-04, 2013, pp. 1600-1603
13.Yuzhakov A. A., Kokoulin A. N., Tur A. I., Application of Fuzzy Search Algorithms and Neural Networks in Fingerprint Document Analysis // 20th IEEE International Conference on Soft Computing and Measurements (SCM), St Petersburg, RUSSIA, MAY 24-26, – 2017. – pp.455457
14.Кокоулин А.Н., Использование нейронных сетей для обнаружения и распознавания пылевых частиц на микрофотографиях // Нейрокомпьютеры: разработка, применение – М.: Издательство "Радиотехника", – Номер: 10, 2015. – с.10-15.
15.Nielsen M. Neural Networks and Deep Learning. 2017. [Электронный ресурс]. – Режим доступа: http://neuralnetworksanddeeplearning.com/index.html – Дата обращения 30 декабря 2017.
16.M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, et al. Tensorflow: Large-scale machine learning on heterogeneous systems, 2015. Software available from tensorflow. org, 1, 2015.
234
17.A. Khosla, N. Jayadevaprakash, B. Yao, and L. Fei-Fei. Novel dataset for fine-grained image categorization. In First Workshop on Fine-Grained Visual Categorization, IEEE Conf. on Computer Vision and Pattern Recognition, Colorado Springs, CO, 2011.
18.O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115(3):211–252, 2015
19.F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 815–823, 2015.
20.C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1–9, 2015
235

УДК 538.931
ПРИМЕНЕНИЕ МЕТОДА ОЦЕНКИ ВЗАИМНОЙ ИНФОРМАЦИИ ДЛЯ ПРЕДСКАЗАНИЯ УСТОЙЧИВОСТИ ПЕНТАПЕПТИДОВ ПО ДАННЫМ МОЛЕКУЛЯРНО-ДИНАМИЧЕСКИХ РАСЧЕТОВ
И.В. Петров, А.И. Михальский ИПУ РАН, лаборатория 38
Предсказание устойчивости пентапептида важно как для фундаментальных исследований структуры белка, так и практических приложений, например, создания лекарств с заданными свойствами. Продемонстрирован подход к решению задачи предсказания устойчивости пентапептидов с привлечением современного метода оценки взаимной информации для снижения размерности данных.
APPLICATION OF THE MUTUAL INFORMATION ESTIMATION METHOD TO PENTAPEPTIDE STABILITY PREDICTION ON MOLECULAR DYNAMICS DATA
Ivan Petrov
Anatoli Michalski
ICS RAS, Lab 38
Abstract: prediction of pentapeptide stability is important for both fundamental understanding of protein structure and practical applications such as drug design. We take a surrogate modelling approach to pentapeptide stability prediction using modern mutual information estimation method for dimension reduction.
Keywords: data analysis; mutual information; protein structure
Введение
Белок является одной из ключевых структурных единиц живого организма и выполняет огромное количество разнообразных задач. Полный цикл формирования белка состоит из следующих этапов:
1)Транскрипция: с ДНК считывается матричная РНК, которая затем урезается и превращается в зрелую мРНК.
2)Трансляция: рибосома превращает зрелую мРНК в последовательность аминокислотных остатков. Это и есть первичная структура белка – последовательность из двадцатибуквенного алфавита.
3)Вторичная структура белка: последовательность начинает принимать трехмерную форму. На данном этапе базовых организаций две: спираль и складчатая форма.
4)Третичная структура белка: здесь происходит более плотная пространственная укладка полипептидной цепи.
5)Четвертичная структура белка подразумевает сбор молекулы белка из нескольких полипептидных цепей. Появлению некоторых важных свойств белки обязаны именно этому этапу.
© Петров И.В., Михальский А.И., 2018
236
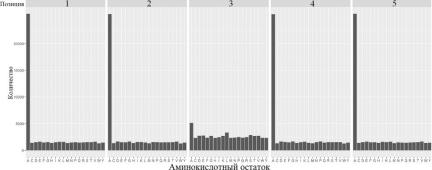
В работе [1] было выяснено, что первичная структура белка может быть разделена на пятёрки аминокислотных остатков или пентапептидов, которые имеют смысл структурного элемента последовательности.
Глобальная цель подобных исследований - лучше понять принципы организации белка, чтобы научиться создавать искусственные белки с желаемыми свойствами.
Первый шаг на этом пути - отбор устойчивы пентапептидов, для более эффективного проведения молекулярно-динамических расчетов и конструирования последовательностей, в широком смысле похожих на встречающиеся в природе. Под устойчивостью понимаются сохранение конфигурации внутренних углов при внешних возмущениях. Для этого необходимо проведение вычислительно емких и продолжительных по времени молекулярнодинамических расчетов.
Альтернативным походом является так называемое суррогатное моделирование [2]: вместо расчетов или лабораторных испытаний строится упрощенная модель для предсказания или генерации новых данных. Экономится огромное количество времени и материальных ресурсов, необходимых для проведения «полевых» испытаний.
Описание данных
В данной работе, согласно подходу АНИС [1], исследуются цепи аминокислотных остатков длины 5. Пример такой последовательности: WQMPE. Согласно выводам исследования, это минимальная длина структурной субъединицы, которую имеет смысл рассматривать. Молекула читается слева направо, и ее разворот обычно влечет разительные изменения свойств.
Устойчивость моделировалась молекулярно-динамическими методами. Для 10000 дискретных временных состояний при моделировании записываются координаты восьми внутренних углов, задающих ориентацию пентапептида в пространстве. Рассматриваются последние 5000 состояний, когда пентапептид прошел стадию колебаний. Данные кластеризуются с использованием внутренних углов как признаков, и нормированный размер % самого большого кластера по смыслу отвечает степени устойчивости пентапептида. Если формируется много небольших кластеров, пентапептид не имеет устойчивых конформаций.
Рисунок 2: частоты различных аминокислотных остатков в пяти позициях.
237

На рис. 1 показаны частоты встречаемости остатков во всех пяти позициях: такой выбор остатков при генерации данных обусловлен их встречаемостью в реальных белках. Поскольку существует 20 аминокислотных остатков, общее количество пентапептидов - 205.
Выборка является несбалансированной: большая часть пентапептидов имеет низкую % ≤ 0.2
ипромежуточную 0.2 < % < 0.8 степени устойчивости, в то время как интересующие исследователя устойчивые % ≥ 0.8 последовательности составляют всего 3.4% от всей выборки. Именно они являются кандидатами для более тщательного изучения в дальнейшем
ипотенциальными составляющими искусственных белков. Распределение % отражено на рис. 2.
Рисунок 3: распределение устойчивости пентапептидов в выборке и ее дискретизация
Данные были закодированы двумя способами:
1. Бинарная кодировка. Каждой позиции соответствует 20 бинарных признаков, отвечающих на вопрос «в данной позиции находится остаток x?». Размерность пространства 100.
2.Кодировка n-граммами [3]. Генерируются все возможные последовательности длин 1, 2 и 3. Каждой из них соответствует признак, отвечающий на вопрос «эта последовательность включена в пентапептид?». Размерность пространства 1561 с исключенными редкими n-граммами.
Метод оценки взаимной информации Least-Squares Mutual Information
Взаимная информация - теоретико-информационная мера зависимости между случайными величинами, отражающая, насколько одна случайная величина детерминирована второй.
|
%(`, °) |
(1) |
¬(-, ®) = ¯ %(`, °) log %(`)%(°) @`@° = ¯ %(`, °) &(`, °)@`@° |
||
²,³ |
²,³ |
|
Ключевые преимущества метода LSMI [4]: прямая оценка отношения плотностей путем разложения по семейству радиальных ядерных функций, существование аналитического решения и встроенная регуляризация. Минимизируется по α следующий функционал:
€n(•) = |
1 |
|
@ (`)@ (°), |
(2) |
2 |
+&(`, °) − &¦(`, °), |
|||
|
|
238 |
|
|

&¦(`, °) = •µ¶(`, °) = ∑. • · (`, °).
где ˆ
Ядерная функция · (`, °) с центроидами ¸ , ˜ и шириной окна σ имеет вид:
· (`, °) = exp »0.5¼I½|` − ¸ |½ ¾ exp »0.5¼I½|° − ˜ |½ ¾ (3
Результаты
Для решение поставленной задачи использовались классические методы машинного обучения такие как логистическая регрессия, kNN-регрессия [5], реализованные в пакете R [6]. Были опробованы и более сложные методы - случайный лес и градиентный бустинг catboost, но это не дало значительно лучшего результата. Задача может ставиться как задача регрессии с последующей дискретизацией меток, так и как задача классификации. Наиболее важными параметрами являются точность предсказания (precision) и его полнота (recall) в классе устойчивых пентапептидов. Выборка разбивалась на обучение и экзамен в соотношении 80-20.
Отбор признаков осуществлялся следующим образом: для каждого признака на обучающем наборе случайным образом отбирались 50 пентапептидов со значением признака «1» и 50 со значением «0». Далее методом LSMI оценивалась величина взаимной информации между этим признаком и степенью устойчивости с использованием 100 ядерных функций.
Рисунок 4: зависимость качества kNN-регрессии от фильтрации признаков по величине взаимной информации. A: бинарная кодировка, B: кодировка n-граммами. Числами показано оптимальное количество ближайших соседей.
На рис. 3 показано, как отбор признаков по величине взаимной информации влияет на точность и полноту классификации. Отбирались только те признаки, взаимная информация между которым и степенью устойчивости была выше некоторого порога. Заметный прирост качества в начале по смыслу соответствует отсеиванию шумящих и неинформативных признаков. Оптимальный порог увеличивает точность и полноту приблизительно на 10%. Лучшие результаты отражены в таблице 1.
Модель, кодировка |
Точность |
Полнота |
Количество |
|
|
|
признаков |
|
|
|
|
kNN-регрессия, |
0.285 |
0.375 |
41 |
бинарная |
|
|
|
kNN-регрессия, |
0.308 |
0.313 |
946 |
n-граммами |
|
|
|
Логистическая |
0.209 |
0.839 |
24 |
регрессия, бинарная |
|
|
|
239
Таблица 1: лучшие модели и их показатели качества
Стоит отметить, что часто самые влиятельные признаки в модели логистической регрессии – одни и те же остатки в различных позициях, особенно этому подвержены первая и последняя позиции:
Остаток |
D |
E |
G |
K |
P |
R |
D |
E |
K |
E |
P |
R |
E |
H |
P |
R |
D |
E |
G |
K |
P |
R |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Позиция |
1 |
1 |
1 |
1 |
1 |
1 |
2 |
2 |
2 |
3 |
3 |
3 |
4 |
4 |
4 |
4 |
5 |
5 |
5 |
5 |
5 |
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 2: наиболее информативные аминокислотные остатки и их позиции в пентапептиде
Выводы
При решении задачи суррогатного моделирования устойчивости пентапептидов хорошо показали себя методы машинного обучения. Применение метода LSMI позволило значительно повысить точность моделей и определить наиболее влиятельные остатки и позиции в пентапептиде. На основе полученных результатов планируется создать веб-сервис для анализа пентапептидов в реальном времени и дообучения модели. Открытым вопросом остается репрезентативность выборки относительно запросов пользователей.
Библиографический список
1.МЕТОД ИССЛЕДОВАНИЯ ИЕРАРХИЧЕСКИХ ЭЛЕМЕНТОВ В ПРИРОДНЫХ АМИНОКИСЛОТНЫХ ПОСЛЕДОВАТЕЛЬНОСТЯХ; А.Н. Некрасов, А.А. Зинченко, Д.М. Карлинский, С.В. Козырев; Успехи современного естествознания, 242–248, № 11 (2), 2016 г. doi:10.17513/use.36217
2.Применение ядерной гребневой оценки к задаче расчета аэродинамических характеристик пассажирского самолета (сравнение с результатами, полученными с использованием искусственных нейронных сетей); А. Я. Червоненкис, С. С. Чернова, Т. В. Зыкова; Автомат. и телемех., 2011, выпуск 5, 175-182
3.Using distances between Top-n-gram and residue pairs for protein remote homology detection; B. Liu, J. Xu, Q. Zou, R. Xu, X. Wang and Q. Chen; BMC Bioinformatics 2014 v.15 (Suppl 2) :S3 https://doi.org/10.1186/1471-2105-15-S2-S3
4.Mutual information estimation reveals global associations between stimuli and biological processes; Suzuki T, Sugiyama M, Kanamori T, Sese J. BMC Bioinformatics. 2009 Jan 30; 10 Suppl 1:S52. doi: 10.1186/1471-2105-10-S1-S52.
5.The Elements of Statistical Learning; T. Hastie, R. Tibshirani, J. Friedman; Springer-Verlag New York 2009; https://doi.org/10.1007/978-0-387-84858-7
6.R Development Core Team (2008). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. ISBN 3-900051-07-0
240