


Федеральное агентство связи
федеральное государственное бюджетное образовательное учреждение
высшего образования
«Сибирский государственный университет телекоммуникаций и
информатики»
(СибГУТИ)
Кафедра Передачи дискретных сообщений и метрологии (ПДСиМ)
10.05.02 Информационная безопасность телекоммуникационных систем, специализация Защита информации в системах связи и управления (очная форма обучения)
Получение прямоугольных импульсов суммирования гармоник. Построение амплитудного спектра.
отчет по лабораторной работе №2
дисциплины «Эффективное кодирование на примере кода Хаффмена»
Выполнил:
студент ФАЭС,
гр. АБ-66 / А.В. Полянский/
«__»_________ 2018 г. (подпись)
Проверил:
доц. каф. ПДСиМ / И.Е. Шевнина/
«__»_________ 2018 г. (подпись)
Новосибирск 2018
Цель работы:
Изучение принципа эффективного кодирования источника дискретных сообщений.
Таблица 1 – Исходные данные
ai |
a1 |
a2 |
a3 |
a4 |
a5 |
a6 |
a7 |
p(ai) |
0.28 |
0.04 |
0.16 |
0.02 |
0.13 |
0.07 |
0.3 |
Энтропия:
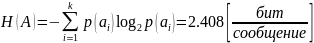
Максимальная энтропия:

Код Хаффмена:
Таблица 2 – код Хаффмена
ai |
a1 |
a2 |
a3 |
a4 |
a5 |
a6 |
a7 |
код |
10 |
01101 |
00 |
01100 |
010 |
0111 |
11 |
li |
2 |
5 |
2 |
5 |
3 |
4 |
2 |
Среднее число двоичных символов на одно сообщение:
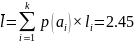
Коэффициент статистического сжатия:

Коэффициент относительной эффективности:
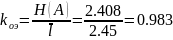
Выполнение:
Определение средней длины сообщения при передаче последовательностей, составленных из сообщений, имеющих разную вероятность появления.
Чередование двух наиболее вероятных сообщений:
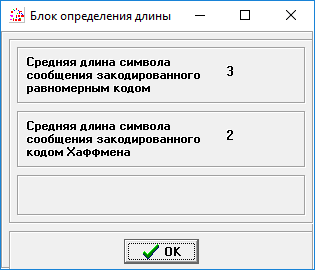
Рисунок 1– Чередование двух наиболее вероятных сообщений.
Чередование двух
сообщений, вероятность которых наиболее
близка к 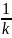 ,
где k
– объем алфавита:
,
где k
– объем алфавита:
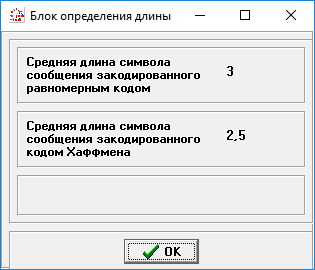
Рисунок 2 – Чередование двух сообщений, вероятность которых наиболее близка к .
Повторение сообщения алфавита, вероятность появления которого минимальна:


Рисунок 3 – Повторение сообщения алфавита, вероятность появления которого минимальна.
Исследование влияния одиночной ошибки на результаты декодирования.
Произвольная комбинация из 16 сообщений:

Рисунок 4 – Произвольная комбинация из 16 сообщений.
Введем ошибку:

Рисунок 5 – Ввод ошибки.
Принятая двоичная последовательность:

Рисунок 6 – Приятая двоичная последовательность.
Принятые сообщения:
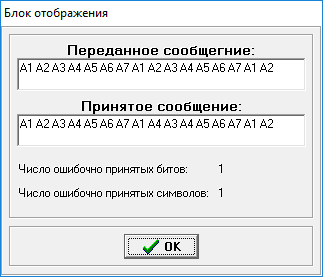
Рисунок 7 – Принятые сообщения.
Введем последовательность слов, состоящую из букв русского алфавита:
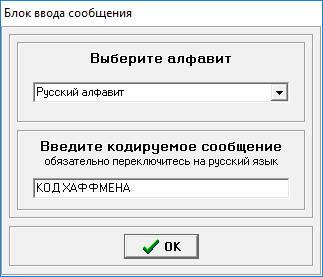

Рисунок 8 – Последовательность слов, состоящая из букв русского алфавита.
Введем ошибку:
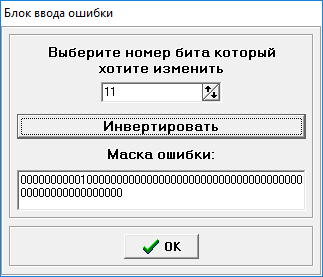
Рисунок 9 – Ввод ошибки.
Принятое сообщение:
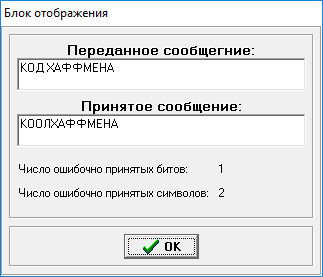
Рисунок 10 – Принятое сообщение.
Вывод:
Код Хаффмена более эффективный, чем равномерный код (kст = 1.224).
Одна ошибка может привести к неправильному декодированию нескольких подряд идущих сообщений (треку ошибок).